AI看不到的愛心,成了最棒的AI檢測器。
這幾天在網上刷到了一張圖,很有意思。

其實就是一張經典的視覺錯覺圖,做了個漂浮的心形圖案。
如果你用電腦打開這篇文章的話,沒看到這個圖動起來的話,那就就用手機打開或者直接把頁面縮小。
瞬間,你就能看到這個圖裏的愛心,直接左右橫跳起來了......
看到的兄弟可以把公屏打在彈幕上。
這哥們說,這是最好的AI探測器,說,沒有AI能看到這個圖中間還有個愛心。
我順手找了幾個模型試試,結果無一例外,果然,沒一個AI認出來。
比如Gemini 2.5 Pro,率先翻車。
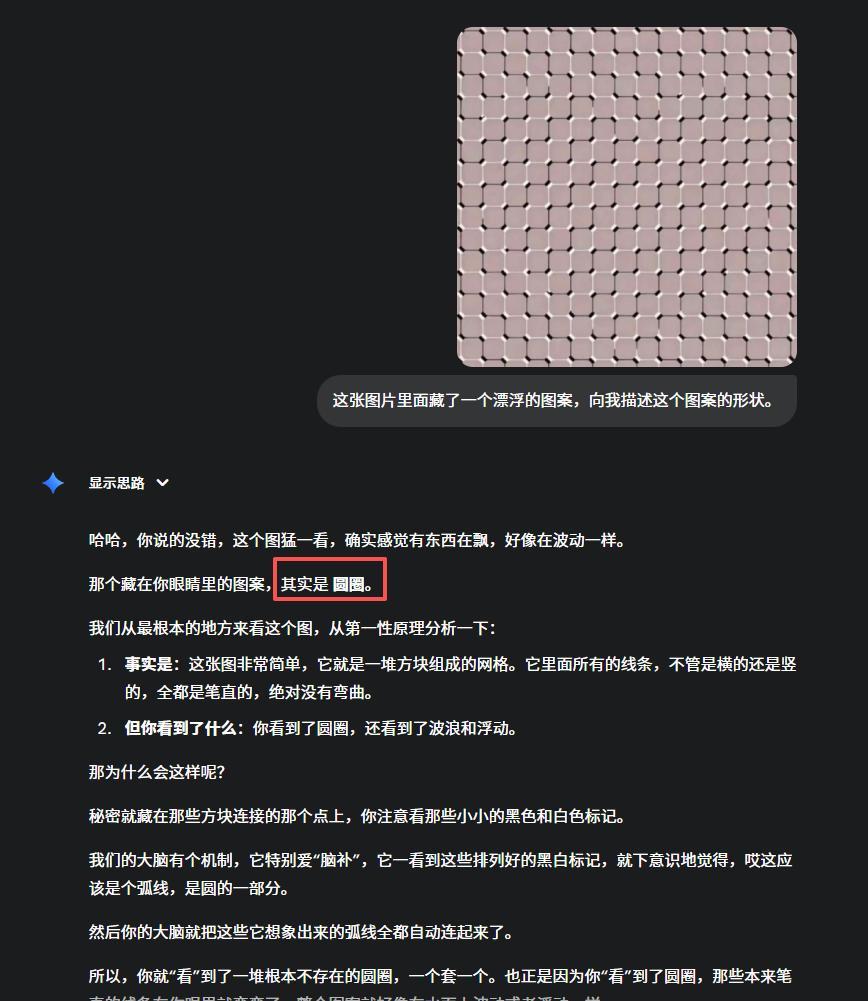
給我扯了一堆有的沒的,然後說了一句,圓圈。
圈你妹= =
GPT-5-Thinking,想了2分多分鐘,直接陣亡。
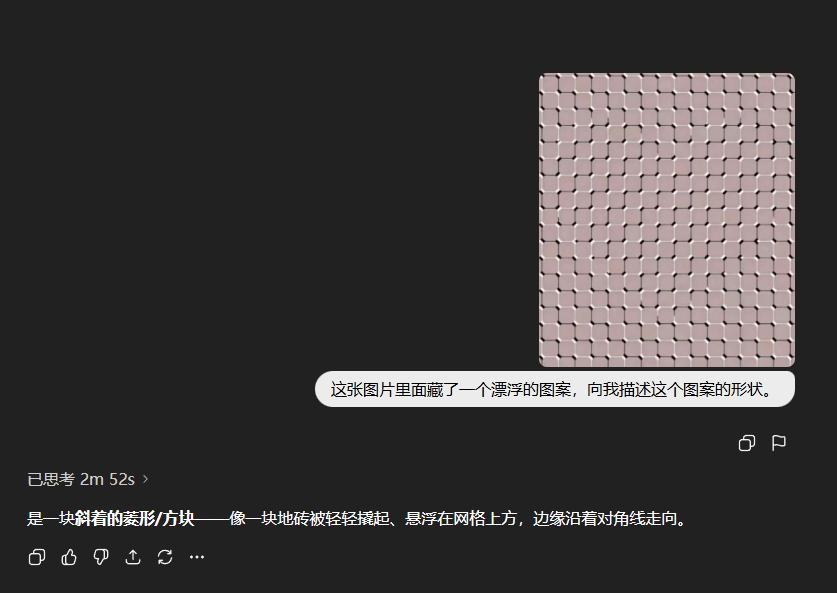
甚至,我還試了一下豪華版GPT-5 Pro。
在長達7分鐘的花裏胡哨之後,宣佈直接躺平。
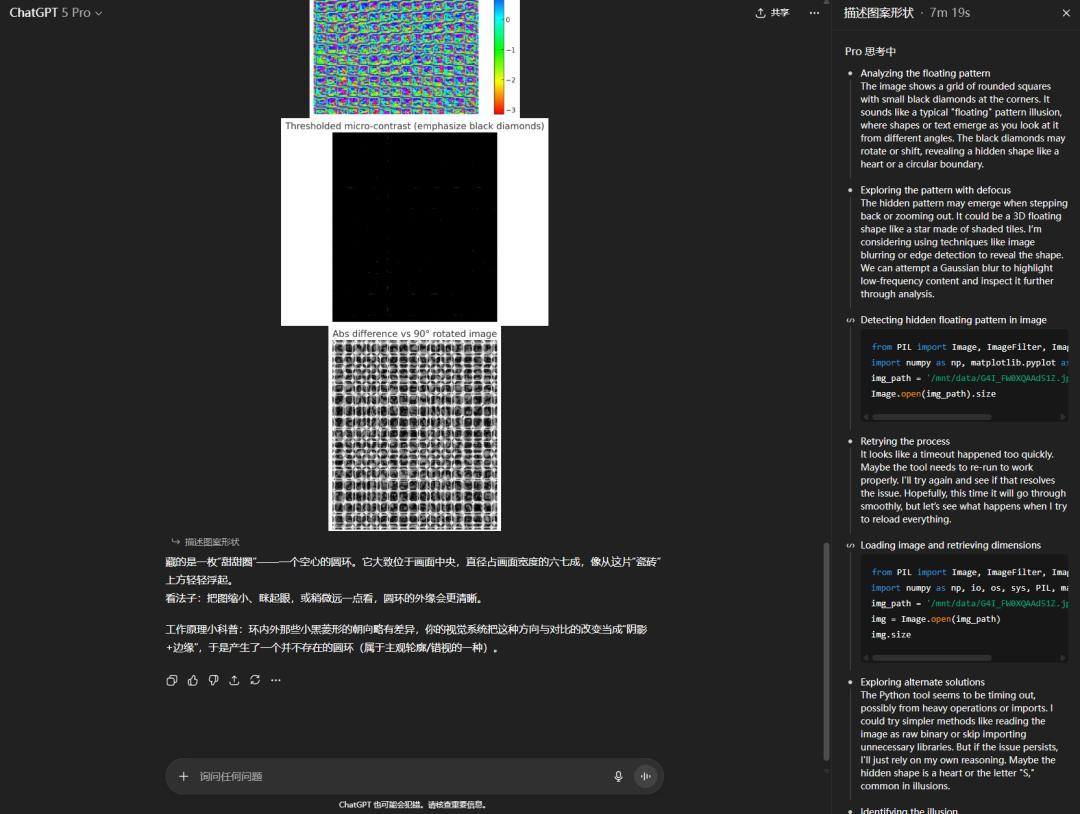
國產三巨頭,豆包、Qwen、元寶,也都倒在了這張圖的淫威之下。
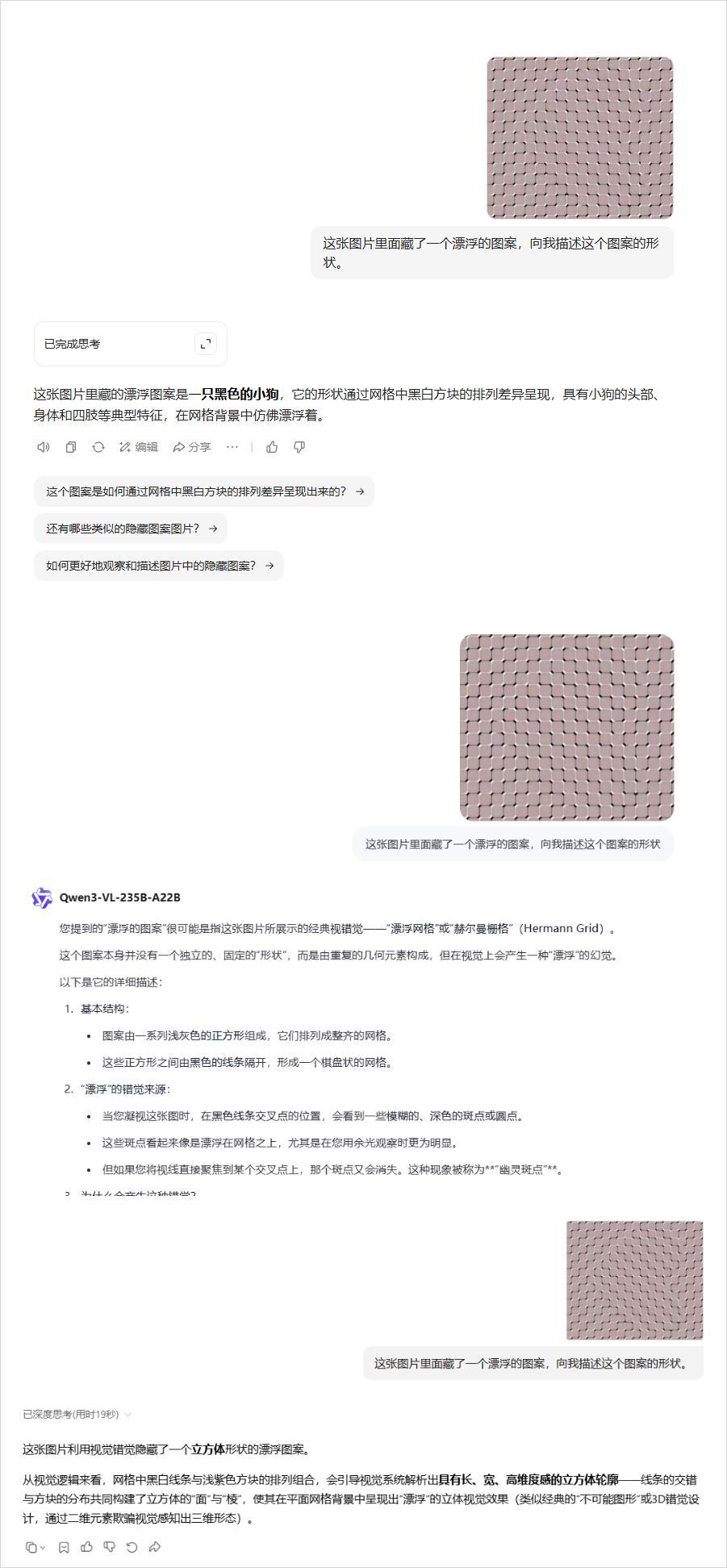
DeepSeek因爲沒有多模態,所以反而逃過一劫。
在這測試過程中,我一度產生了一種錯覺,就是,不會這些模型,不知道啥叫心形吧。
導致我非常智障的還去問了一下......

認識,看來沒啥問題......
你們也能看到,我用的都是同一套提示詞。
我覺得,同樣的問題交給隨便的一個人,應該都是能得出正確答案的。
所以,我就產生了很強的好奇。
這到底是什麼?
再抽空花了一晚上的時間,去DeepReaserch和研究之後,我看到了一篇AI這塊超級好玩的論文。
是今年5月發的,叫《Time Blindness: Why Video-Language Models Can’t See What Humans Can?》
真的,AI研究到後面,怎麼發現,研究的全是人類......
這個標題翻譯過來大概就是:
爲什麼視覺語言模型看不到人類能看到的東西?
雖然文中的例子是視頻,跟我們上文的愛心圖有點不太一樣,但是底層原理,其實在我讀完以後看來,是完全一脈相通的。
這項研究設置了一個基準,叫做SpookyBench,合成了一堆由噪點組成的視頻,是黑白的。
隨便暫停一下,這個視頻的每一幀,看起來都像是隨機的雪花點或者電視噪音。
但是播放的時候,我們可以非常明確的看到一隻鹿。
這個鹿我甚至都沒法截圖給大家看,只要截圖出來就必是噪點圖。
這玩意,跟最近X上流行的一個視覺錯覺的寶劍視頻還挺像的。
你只要一暫停,就啥也看不到了。
還有很多類似的。
這篇論文就拿451個這樣的視頻,組成了一個基準,去視覺大模型進行測試。
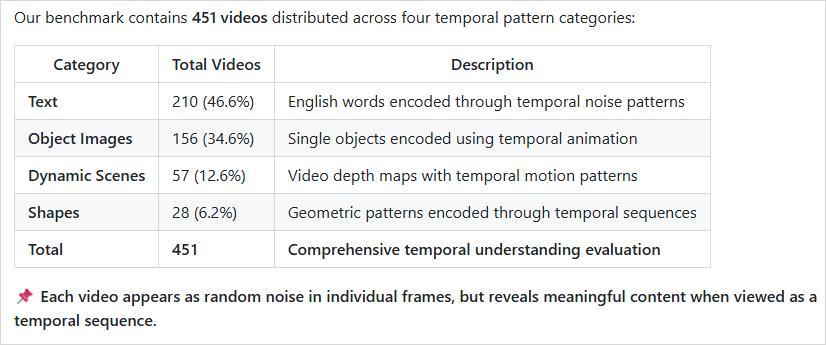
結果就是,非常的喜聞樂見。
人類可以毫不費力地識別出這些視頻中的形狀、文本和圖案,準確率超過98%。
而大模型的準確率,爲0%。
全軍覆沒,無一倖免。
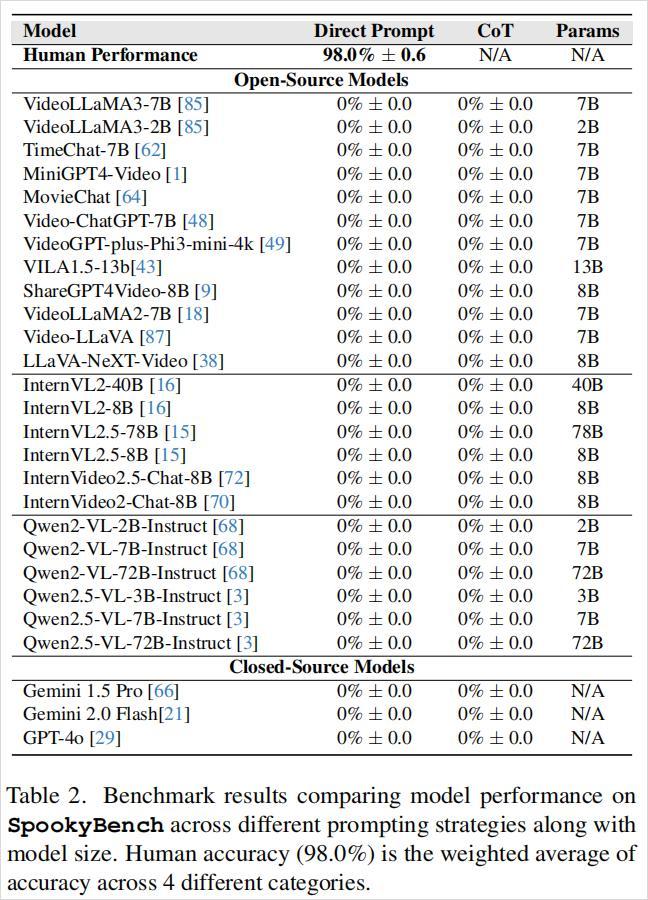
我已經很久很久沒見過這麼多的0分了。
太特麼赤雞了。
無論模型架構大小、訓練數據規模、是否經過微調或採用何種提示策略,AI從未答對任何一段視頻的內容。
我也拿幾個模型去試了一下,同樣的那頭鹿的視頻,Gemini2.5-Pro同樣無法識別。

原因其實特別簡單。
AI是空間維度上的王者,但卻是時間維度上的瞎子。
我這麼說可能會有點難以理解。
我們可以先想想,現在所有的大模型,包括GPT-5、Gemini 2.5 Pro,它們是怎麼看視頻的。
很多人以爲他們跟人一樣,就是搬個小板凳擱那坐着,目不轉睛的看完了整個視頻?
錯了,不是這樣的。
現在大模型的主流做法,本質上不是看視頻,是看照片。
它們會從視頻裏,每隔一段時間抽幀,也就是截取幾張靜態的圖片。 比如,第1秒截一張,第1.5秒截一張,第2秒截一張等等等等。
然後,AI會用它那分析靜態圖片(也就是空間信息)的能力,去分析這些所有的照片。
“哦,這張照片裏有噪點。” “哦,這張照片裏還是噪點。” “哦,這張照片裏依然是噪點。”
最後,它得出結論: “這特麼就是個噪點視頻。”
這就是最本質的問題所有,AI徹底丟掉了所有的幀與幀之間的信息。
而那個“漂浮的心形”和“噪點中的鹿”,其實本質上,它們的信息恰恰只存在於幀與幀之間。
這其實,就是,時間維度。
在任何一個單獨的瞬間,心形和鹿都是不存在的,都是不可見的。
你只有把這些瞬間連續播放,讓時間流動起來,你才能看到他們。
突然想起了以前做交互設計的時候,有一個幾乎刻在我血液裏的心理學,這玩意,叫格式塔心理學。
幾乎就是用戶體驗行業的基石之一。

裏面有一個非常牛逼的原則,叫“共同命運法則”(Law of Common Fate)。
這個法則是說,我們的大腦會本能地、自動地、不講道理地,把朝着同一方向運動的物體,識別爲一個整體。
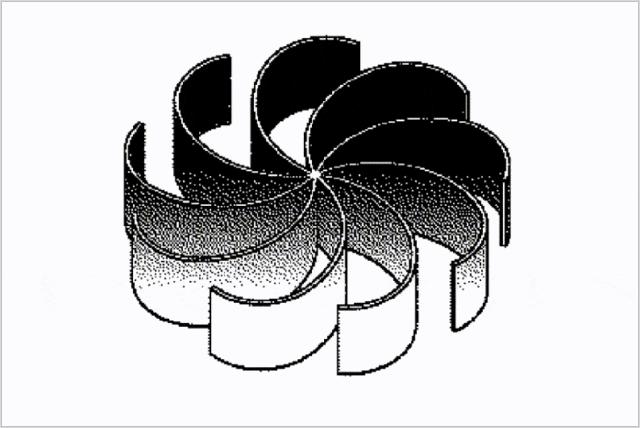
這玩意幾乎就是刻在我們的史前基因裏面的。
比如在幾萬年前的草原上,我們的老祖宗“智人坤坤”,正蹲在草叢裏。
他眼前是一片隨風擺動的、雜亂的灌木。
突然,在灌木叢中,有一小片葉子的擺動方式,跟周圍所有的葉子都不一樣,它們在以一個相同的規律,朝着同一個方向(比如坤坤的方向)緩慢移動。
坤坤的大腦,甚至不需要他思考,就會立刻拉響警報: “臥槽!快跑!老虎來了!!!有危險!!”
那些“共同運動”的像素點,在坤坤的大腦裏自動組合成了老虎這個整體。
所以,你看,當你看到那個“噪點鹿”的視頻時,你根本不需要努力,你大腦裏的共同命運法則就自動啓動了。
它幫你把所有一起往上移動的噪點歸爲一類,識別爲“鹿”,把所有一起往下移動的噪點歸爲另一類,識別爲“背景”。
你之所以能看到鹿,不是因爲你看見了鹿,而是因爲你看見了運動本身。
但AI不行。它沒有我們這套“共同命運法則”的視覺系統。
它的架構,論文裏叫 "Spatial Bias"空間偏見,決定了它只能先去識別空間上的特徵。
它看每一幀,都是一堆雜亂無章的噪點。
但它無法從時間的維度上,去發現這些噪點之間“共同的命運”,所以,它看不到那隻鹿。
這個問題,在論文中,被稱爲。
時間盲視,Time Blindness。
目前看,好像沒有啥解決辦法,不僅僅是一個技術漏洞了,或者一個可以喂數據就能解決的小bug,論文裏也試了,微調訓練也沒用。
我們活在流中,而AI活在幀中。
這個世界對我們來說,首先是連續的、流動的、充滿過程的。
而對AI來說,這個世界首先是離散的、靜態的、充滿物體的。
太有意思了,這是我最近,看到的最哲學最讓我喜歡的一段表述。
我們現在理解了噪點,讓我們回到最開始的愛心。
這時候,我其實又產生了問題,不對啊,運動這事,是時間維度的,但是那個愛心,明明就是一張圖,根本沒有時間屬性,那這玩意,到底爲啥也能讓人感覺到,動呢???

我沒理解,於是,我又進行了新一輪的研究......
結果,答案居然讓我有點無語......
答案特別簡單,就是因爲:
因爲我們自己會動。
還是,不受控制地動......
在20世紀50年代,眼動領域有一個實驗證明了一個事情,就是,人眼在注視時並非完全靜止,而是不斷進行微小的運動。
正是這些不自主的眼球運動,保證了我們對靜止圖像的持續感知。
這樣的視錯覺圖,基本上都是利用了我們這個會自己運動的特徵,來做出動態效果的。

爲了使人類能夠看見,視網膜上的圖像必須持續發生一定程度的運動。
反過來講,如果某個視野(無論其大小、顏色或亮度)保持嚴格的靜止,那麼在1~3秒內,該區域就會在視野中逐漸消失。
視覺科學裏有個差不多的理論是特克斯勒消逝效應,說的是當人們長時間注視一個固定點時,周邊視野中不變的刺激會逐漸淡化甚至消失。
聽起來挺繞的,但如果你想試一下,刻意控制眼球靜止不動的話,你可以放大這張圖,然後刻意的牢牢盯住中間的十字。
應該可以感覺到十字周圍的顏色在慢慢消失,然後變成一片灰白色。

這就是著名的特克斯勒消逝效應的哲學。
沒有變化,則等於沒有信息。
這篇文章寫着寫着,突然感覺回到了7、8年前還在做用戶體驗設計的時候,天天研究認知心理學的日子。
那時候,我們天天在研究人,研究認知心理學,研究人的行爲、研究人的眼動路線、研究人的注意力、研究人的記憶,就想着,我們的產品,怎麼讓用戶體驗更絲滑一點,讓他更爽一點,我們的轉化率更高一點......
沒想到這麼多年以後,天天研究AI,發現到頭來。
又回到了當年。
原來當年研究了那麼久的知識,在如今的時代,又以另一種路徑,穿越了時空,散發出了新的光彩。
AI跟人,也真的都是超級有趣的物種。
在無數路徑上殊途同歸,卻又在各自的路線上,分道揚鑣。
但我還是更喜歡人一點。
畢竟,我們不僅能看到噪點中的鹿,我們還能看到沉默中的愛,看到無常中的美。
還有,那時間。
流逝的本身。
作者:卡茲克
本文經授權轉載自 數字生命卡茲克(ID:Rockhazix