黃仁勳送馬斯克的3萬塊個人超算,要借Mac Studio才能流暢運行?首批真實體驗來了

2000 億參數、3 萬塊人民幣、128GB 內存,這臺被稱作「全球最小超算」的機器,真的能讓我們在桌面上跑起大模型嗎?

圖片來自 x@nvidia
前些天,黃仁勳正式把這臺超算送到馬斯克手上,而後也親自去到 OpenAI 總部,送給奧特曼。從 CES 登場到如今落地,這臺個人超算終於要來到我們手上。
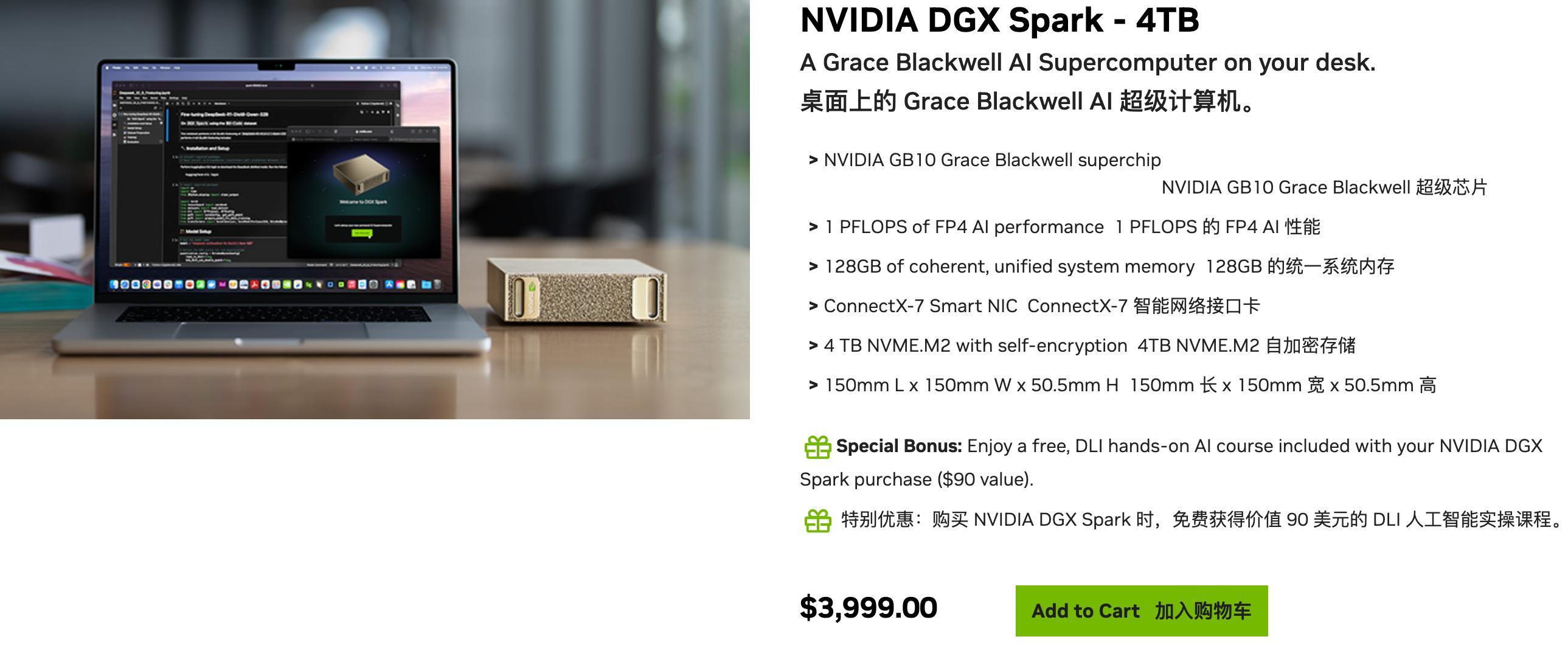
官網發售情況,售價 3999 美元,也提供了華碩、聯想、戴爾等七個電腦品牌的發售版本;鏈接:
https://marketplace.nvidia.com/en-us/developer/dgx-spark/
NVIDIA DGX Spark,一臺個人 AI 超級計算機,目標用戶是科研人員、數據科學家和學生等,爲他們提供高性能桌面級 AI 計算能力,幫助他們完成 AI 模型的開發和創新。
聽着很強大,但普通人能想到的玩法,無非還是:
- 本地跑大模型:跟它聊天的內容只留在自己電腦裏,絕對安全。
- 本地搞創作:不受限制地生成圖片和視頻,告別會員和積分。
- 打造私人助理:把自己的資料都餵給它,訓練一個只懂你的「賈維斯」。
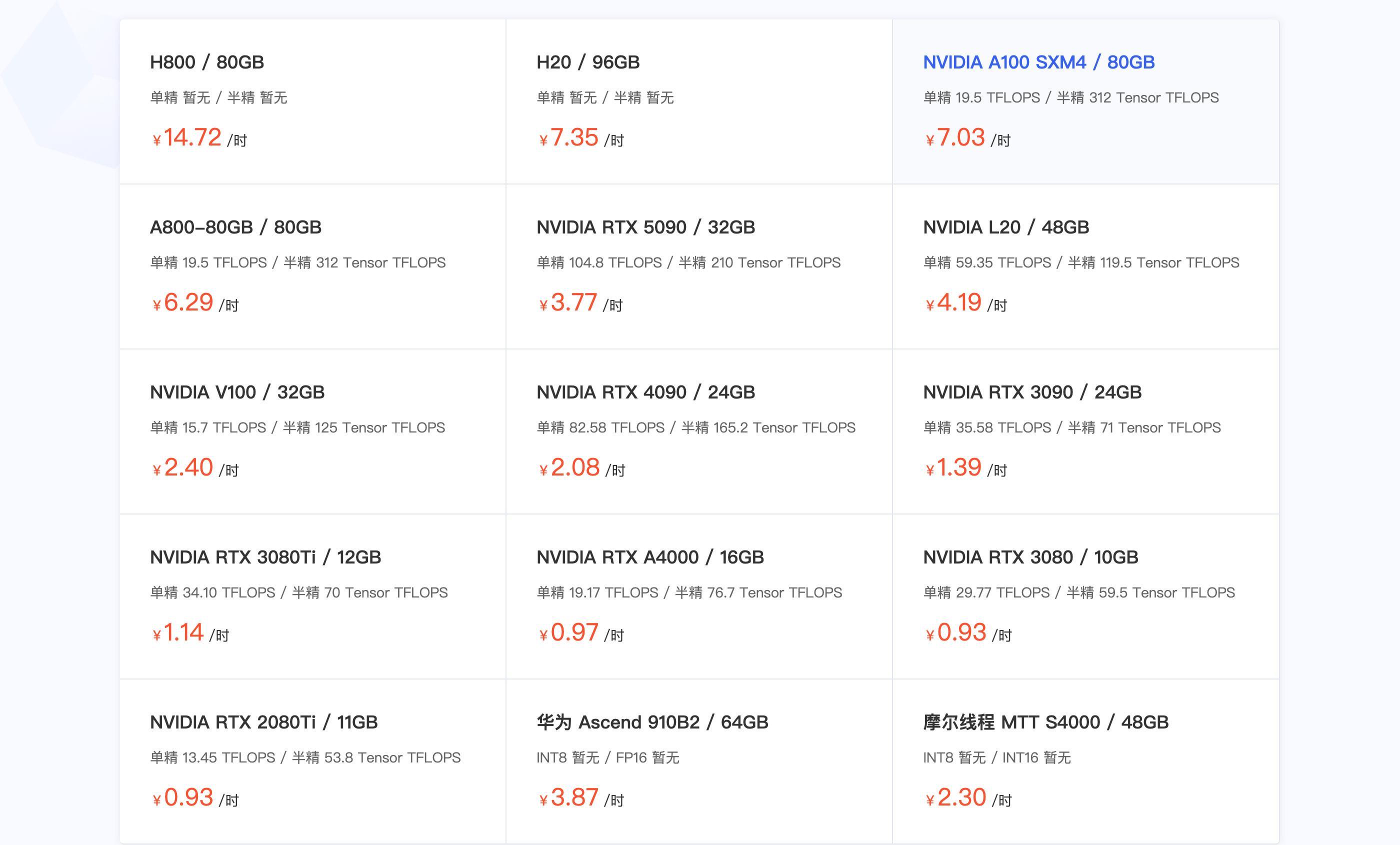
部分顯卡租賃平臺顯示的 A100 售價爲 7元/時
實際上,DXG Spark GB10 Grace Blackwell 超級芯片的能力,或許可以拓展它的應用場景,但是具體能做些什麼?又做得怎麼樣?3 萬塊的售價,能租 4000 小時的 A100,你真會把它放在桌上跑跑大模型嗎?
我們收集了目前網絡上關於 DGX Spark 多個詳細評測,試圖在我們的實際體驗之前,帶大家看看這臺設備,到底值不值 3 萬塊。
太長不看版:
- 性能定位:輕量模型表現出色,1200 億參數的大模型也能穩穩跑起來。總體水平介於未來的 RTX 5070 和 RTX 5070 Ti 之間。
- 最大短板:273 GB/s 內存帶寬是限制。算力足夠,但數據傳輸慢。體驗就像一個腦子轉得飛快但說話結巴的人。
- 邪修玩法:用一臺 Mac Studio M3 Ultra 來「輔佐」它。DGX Spark 負責快速思考,Mac Studio 負責流暢表達,強行解決「結巴」問題。
- 生態豐富:官方提供了超過 20 種開箱即用的玩法,從生成視頻到搭建多智能體助手,AI全家桶都給你配齊了。

只比 Mac Mini 強一點點?
話不多說,先看數據。
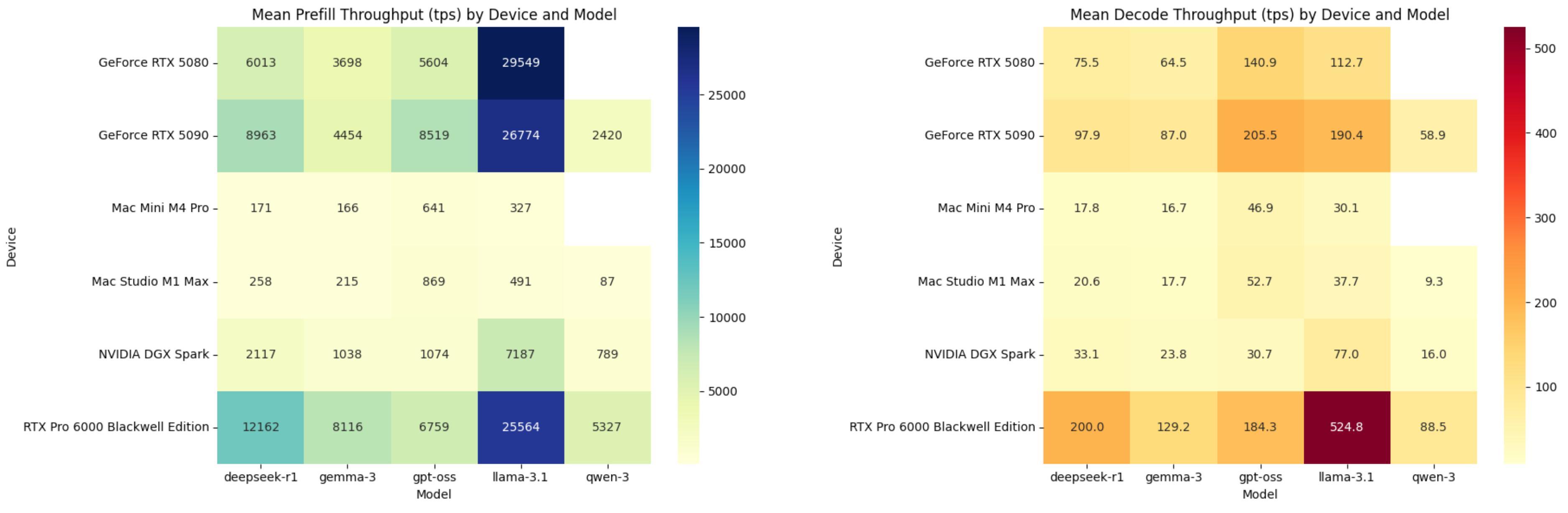
每秒處理填充和解碼的平均 token 數量,DGX Spark 排在 RTX 5080 後,圖片由 ChatGPT 製作
DGX Spark 對比 Mac Mini M4 Pro 還是要強上不少,尤其是在 Prefill 階段。但是在 Decode 階段,優勢就沒有這麼明顯了。Mac Mini M4 Pro 在 DeepSeek R1 開源模型上的 TPS 能做到 17.8,而 DGX Spark 也才 33.1。
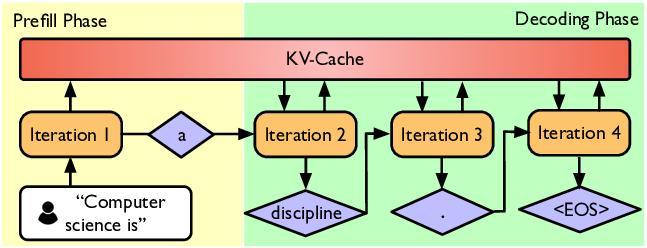
快速做個名詞解釋,來看看 AI 推理的兩個階段到底是什麼
簡單來說,當我們在 AI 聊天框裏輸入問題,模型生成答案的過程可以分爲兩個關鍵步驟:
1. Prefill(預填充/閱讀理解階段)
AI 拿到我們的問題後,快速閱讀和理解你輸入的每一個字(即提示詞)。
這個階段處理得越快,我們等待 AI 吐出第一個字的時間就越短,也就是常用來宣傳 AI 能力的指標,首字響應時間,TTFT(Time To First Token, TTFT) 越短。
2. Decode(解碼/生成答案階段)
就像 AI 已經想好了答案,開始逐字逐句地打字輸出給我們。
決定 AI 打字的速度,也就是我們常說的 TPS(每秒生成詞元數)。這個數值越高,我們看到答案完整顯示的速度就越快。
Tips:什麼是 TPS?
TPS 是 Token Per Second(每秒處理詞元數)的簡稱,可以理解爲 AI 的工作效率或打字速度。
Prefill 階段的 TPS: 代表 AI 讀懂問題的速度。
Decode 階段的 TPS: 代表 AI 給我們生成答案的速度。

所以 DGX Spark 在給我們回答時,第一個字很快能出來,但是後續它的打字速度,很慢。要知道,Mac Mini M4 Pro 的價格才 10999 元,24GB 統一內存的版本。
爲什麼會這樣?這項測試是由大模型競技場的團隊 LMSYS,在他們的 SGLang 項目和 Ollama 上,選擇上圖中六個不同的設備,運行多個開源大語言模型完成的。

SGLang 是由 LMSYS 團隊開發的高性能推理框架,FP8、MXFP4、q4_K_M、q8_0 是指大語言模型的量化格式,即對大模型進行壓縮,用不同的二進制存儲方式
測試的項目包括了 1200 億參數的本地大模型,也有 80 億的較小模型,此外 Batch Size 批次大小和 SGLang 與 Ollama 兩種框架的差別,都會對 DGX Spark 的表現,產生不同的影響。
例如,評測團隊提到,DGX Spark 在批次大小爲 1 時,每秒解碼的次元數只有 20 個,但是當批次大小設置爲 32,每秒解碼詞元上升到 370。一般說,批次大小設置越大,每次要處理的內容越多,對 GPU 的性能要求越高。
而 DGX Spark 的 AI 能力,根據其所採用的 GB10 Grace Blackwell 芯片架構,以及 1 PFLOP 的稀疏 FP4 張量的性能,定位是在 RTX 5070 和 RTX 5070 Ti 之間。
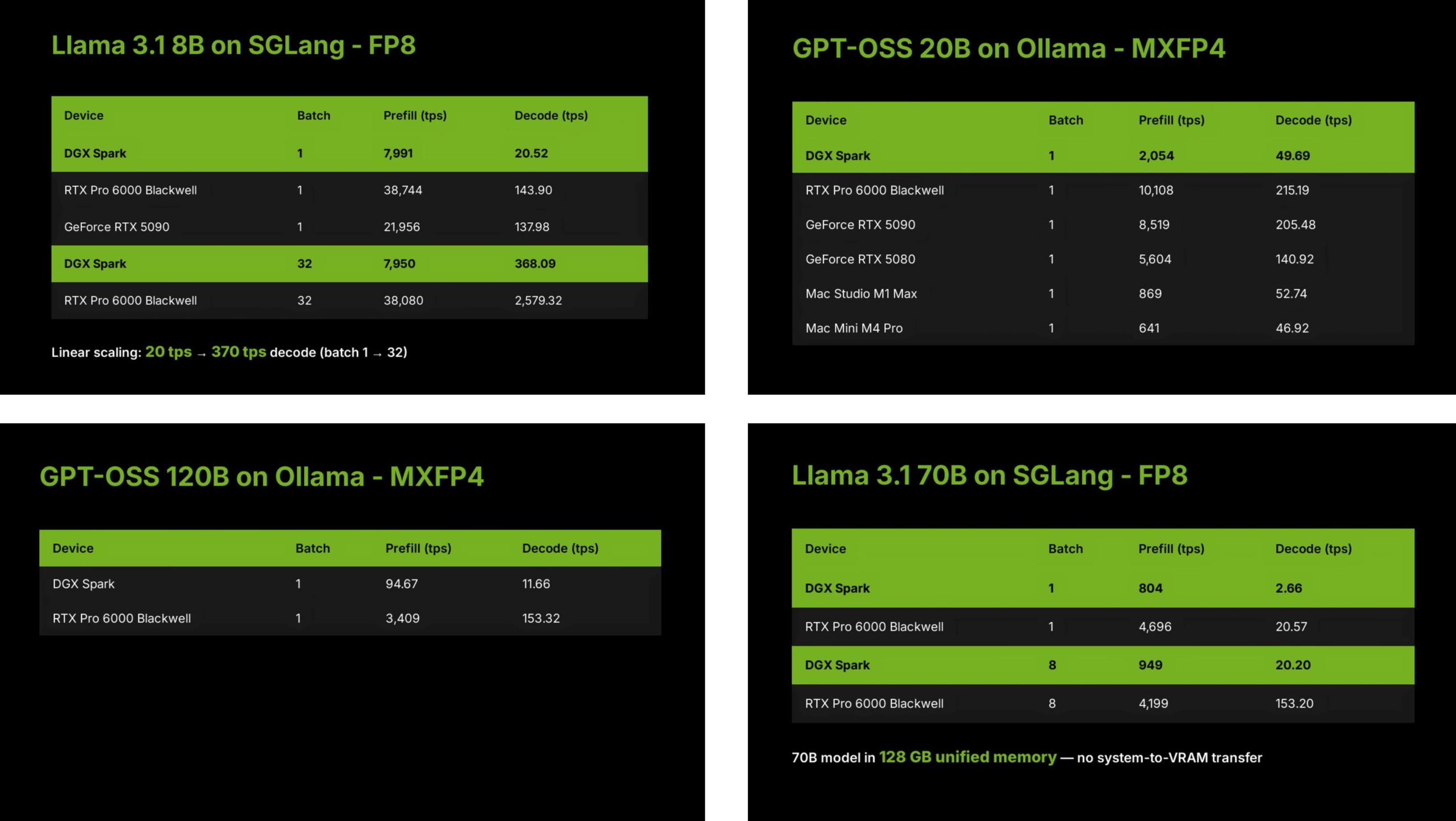
所以開頭那張顯示結果的圖,其實並不能全面的展示 DGX Spark 的能力,因爲它平均了所有模型測試的結果。但不同批次大小的模型推理、以及不同參數的模型,它最終展示出的性能,都會有所不同。
綜合來看,DGX Spark 的優點是:
- 算力強:能處理大批量任務,AI 核心能力在 RTX 5070 級別。
- 內存大:128GB 的海量內存,讓它能輕鬆運行千億級別的大模型。

但它的短板,致命且清晰——帶寬。
Prefill 階段拼的是算力(腦子快不快),Decode 階段拼的則是帶寬(嘴巴快不快)。
DGX Spark 的問題就是:腦子(算力)很快,但嘴巴(帶寬)跟不上。
打個比方,它的數據通道就像一根細水管:
- DGX Spark 用的內存是 LPDDR5X(手機和筆記本電腦常用),帶寬只有 273 GB/s。
- 作爲對比,高端遊戲顯卡 RTX 5090 用的 GDDR7 內存,帶寬高達 1800 GB/s,那是一根消防水管。
這就是爲什麼 DGX Spark 在打字階段(Decode)表現平平的根本原因。
LMSYS 將評測的詳細結果放在了 Google 文檔中,我們把數據交給 Kimi 智能體,得到了一份詳細的可視化報告,原始數據的預覽,也可以點擊 Kimi 預覽報告下載選項獲取。

https://www.kimi.com/chat/199e183a-7402-8641-8000-0909324fe3fb
帶寬限制?連接一臺 Mac Studio 破解
帶寬是短板,但已經有更極客的團隊,找到了榨乾 DGX Spark 全部算力的方法,那就是找一個帶寬更快的桌面設備,Mac Studio M3 Ultra,利用其 819 GB/s 的速度,把大模型的推理速度愣是整體提升了 2.8 倍。
拿到兩臺 DGX Spark 早期訪問權限的 EXO Lab,就直接把大模型推理的 Prefill 和 Decode 兩個階段,分別給了 DGX Spark 和 Mac Studio 來承擔,這又叫做 PD 分離。
和我們之前介紹的預填充、解碼兩個階段一樣,一個依賴算力,一個依賴帶寬。如上圖所示,黃色代表預填充階段,它決定着 TTFT,首個次元生成時間;而藍色代表解碼階段,它決定了 TPS,每秒生成的詞元數。
EXO Lab 的做法就是將 Decode 交給 Mac Studio。
但 PD 分離的實現也不併不簡單,EXO 團隊要解決的還有一個問題,如何將 DGX Spark 設備上,預填充階段生成的內容(KV 緩存),傳輸到處理解碼的設備上。
這部分數據量很大,如果兩臺設備之間,傳輸時間太長,甚至可能會抵消性能提升的效果。
EXO 的答案是:流水線式分層計算與傳輸。DGX Spark 在處理第一層預填充時,計算出的 KV 緩存會立即開始傳輸給 Mac Studio,而 DGX Spark 則繼續進行第二層的預填充工作。
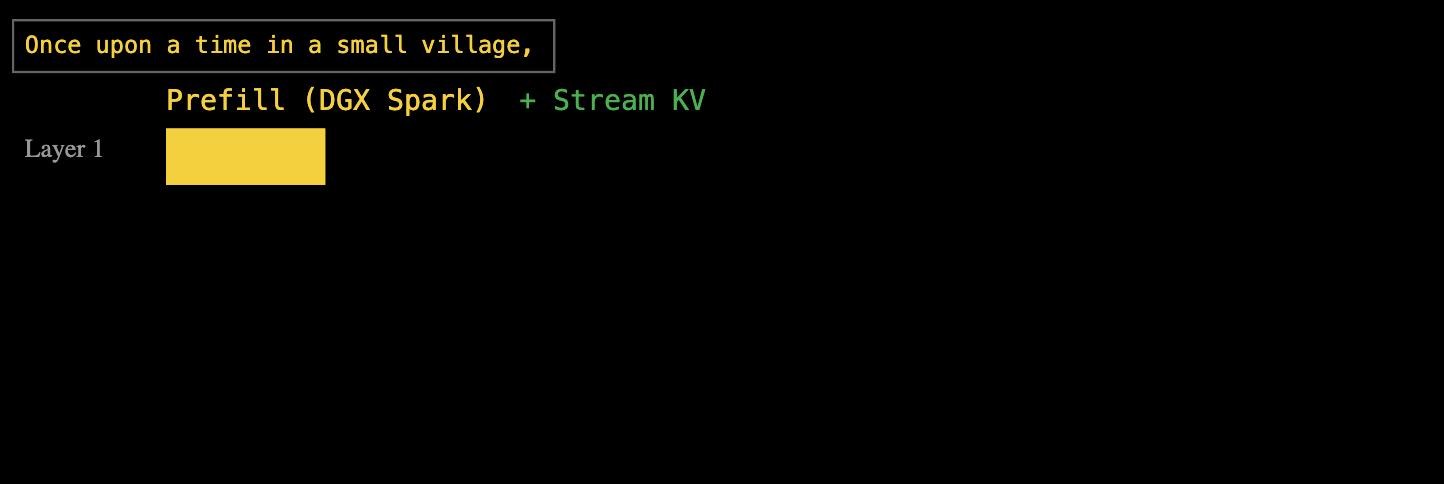
這種分層流水線的方式,能讓計算和數據傳輸的時間完全重疊。最終,當所有層的預填充完成,Mac Studio 已經拿到完整的 KV 緩存,可以立即開始解碼。
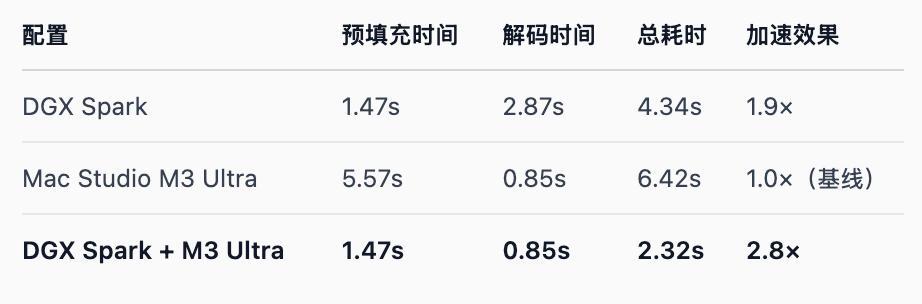
雖然這套方案,在某種程度上解決了 DGX Spark 帶寬限制的問題,提升了 3 倍的速度,但是費用也漲了 3 倍。兩臺 DGX Spark 和一臺 Mac Studio M3 Ultra 的費用,快接近 10 萬元人民幣。
如果還是用來跑一個本地大模型,未免太過於殺雞用牛刀。
性能評測之外,還能做些什麼
273 GB/s 的帶寬,也並不是 DGX Spark 的全部,128GB 的統一內存,用在數據中心級別的 GB10 架構顯卡,支持每秒一千萬億次計算(1 Petaflop),以及桌面級設計,都有機會拓展它的應用場景。
我們在 YouTube 上找了一些博主的開箱和上手體驗視頻,一起看看這臺優點和短板都很明顯的設備,可以做點什麼。
本地 AI 視頻生成
生文模型現在基本上都免費使用,但是生視頻的模型,大多數都需要充值會員,或者積分制。
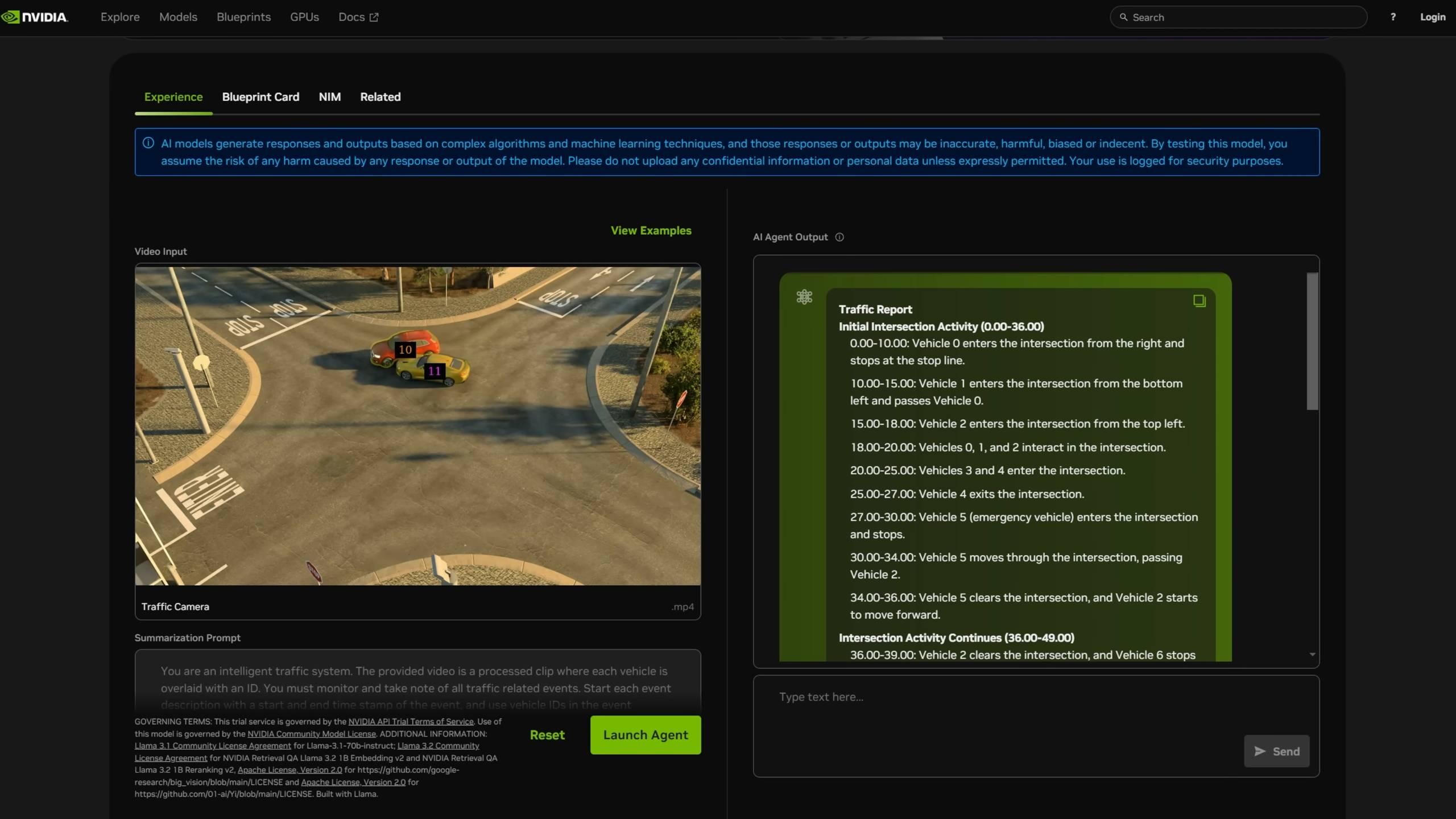
博主 BijianBowen 利用 ComfyUI 框架,以及阿里的 Wan 2.2 14B 文本到視頻模型,直接根據 DXG Spark 官方的 Playbooks(操作指南),配置了一個視頻生成項目。
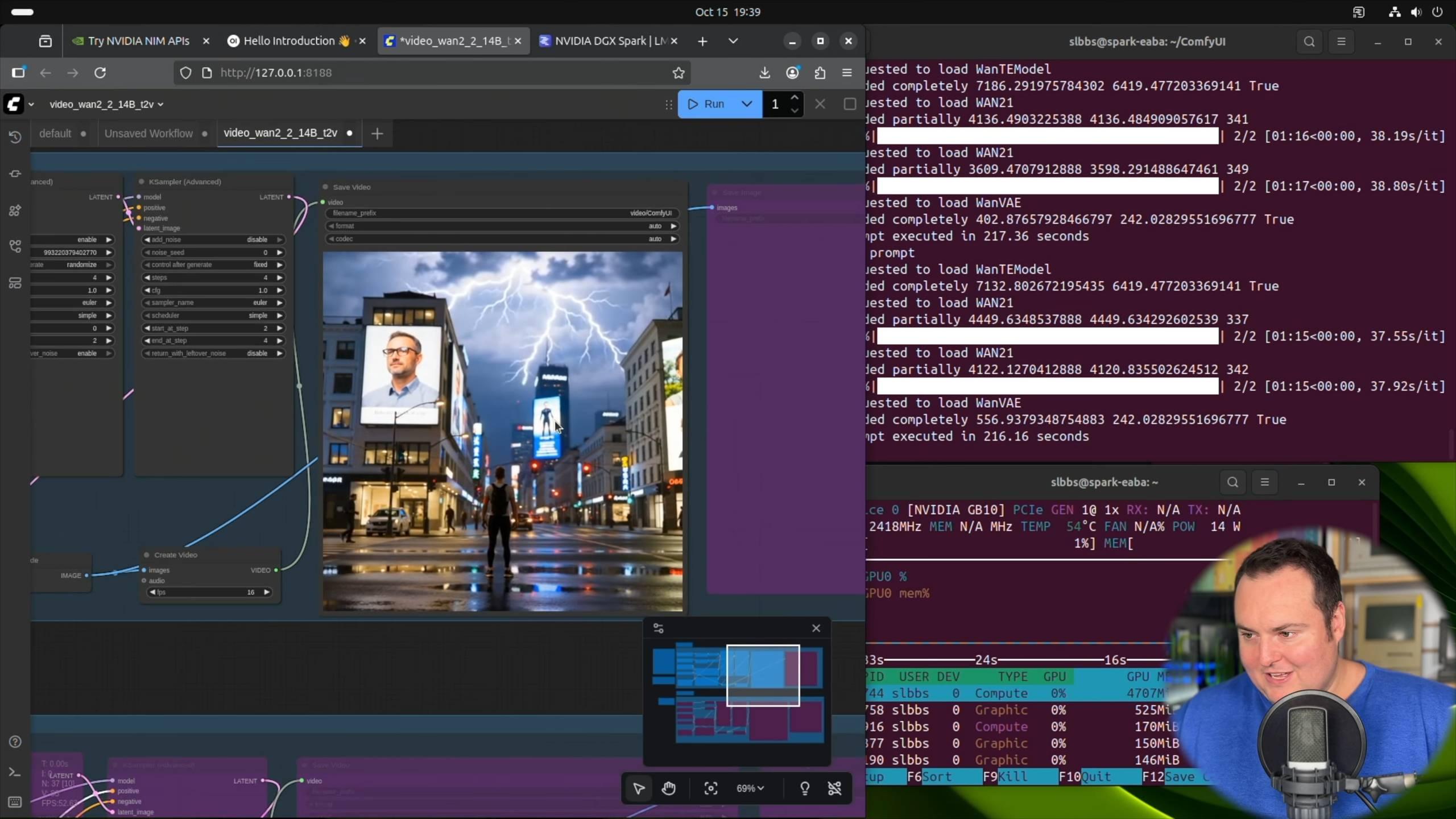
NVIDIA DGX Spark – 非贊助的評測(與 Strix Halo 對比、優缺點)視頻來源:
https://youtu.be/Pww8rIzr1pg
在視頻生成過程中,他提到即使命令後顯示 GPU 的溫度已經達到了 60-70 攝氏度,但是聽不到一點噪音,風扇轉動的聲音也沒有。

大部分博主有提到,DGX Spark 確實比較「安靜」,設備拆解相當工整,來自 storagereview.com
除了用在視頻生成和圖像生成的 ComfyUI 提供了在 DGX Spark 上操作的指南,還有在本地運行大模型的桌面工具 LM Studio,也發佈了博客提到支持 DGX Spark。
工具調用,搭建多智能體聊天機器人
Level1Techs 分享了自己用 DGX Spark 並行運行,多個 LLMs 和 VLMs,來實現智能體之間的交互。
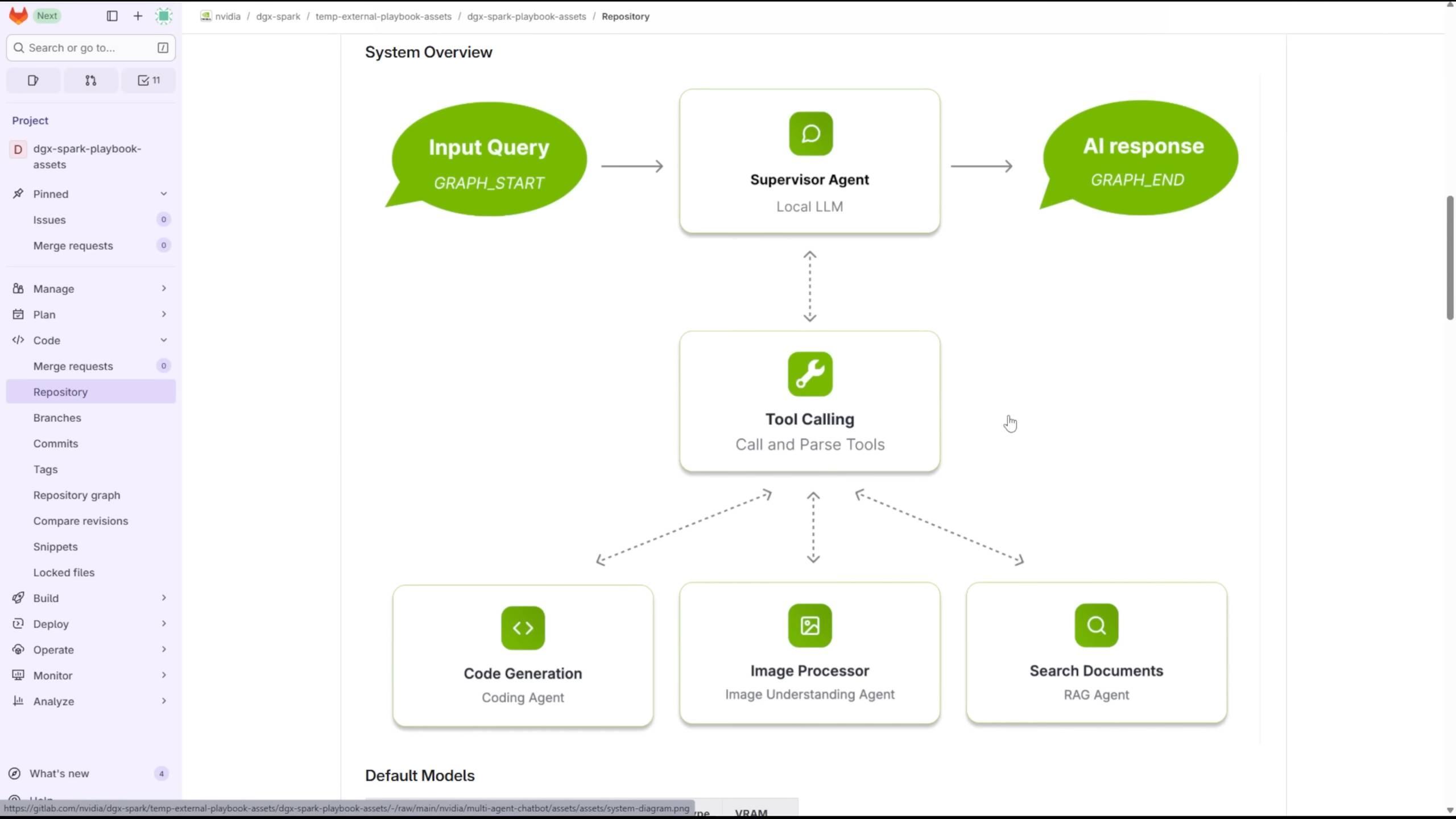
深入探討英偉達的 DGX Spark,視頻來源:
https://youtu.be/Lqd2EuJwOuw
得益於 128GB 的大內存,他可以選擇 1200 億參數的 GPT-OSS、67 億的 DeepSeek-Coder、以及 Qwen3-Embedding-4B 和 Qwen2.5-VL:7B-Instruct 四個模型,來處理不同的任務。
這個項目也是 Nvidia 官方提供的指南,在他們官網,提供了超過 20 種玩法,並且每一種用法,都給出了預計需要的時間,以及詳細的步驟。
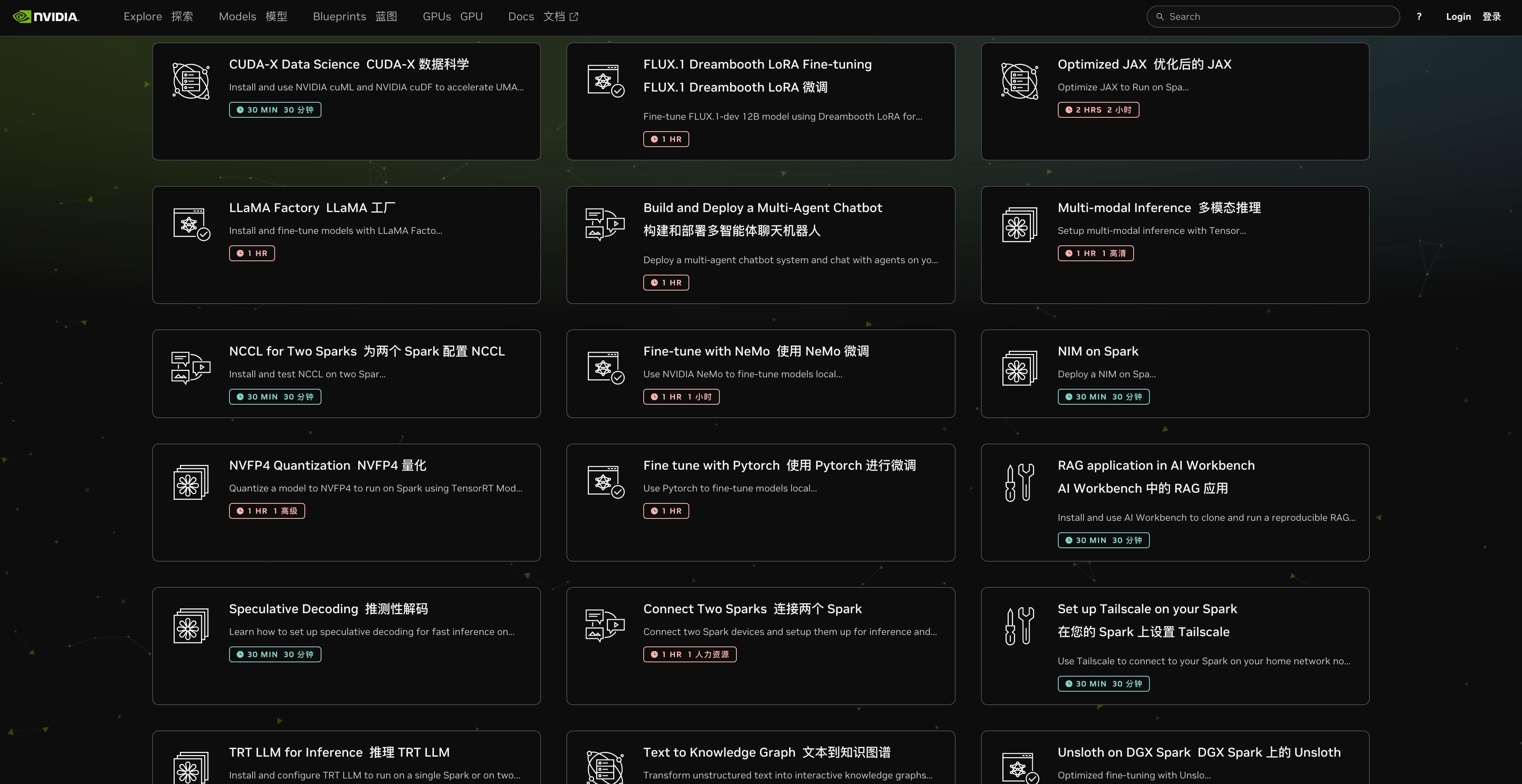
https://build.nvidia.com/spark
像是搭建一個文本到知識圖譜的系統,把非結構化文本文檔,轉換爲結構化知識結點。
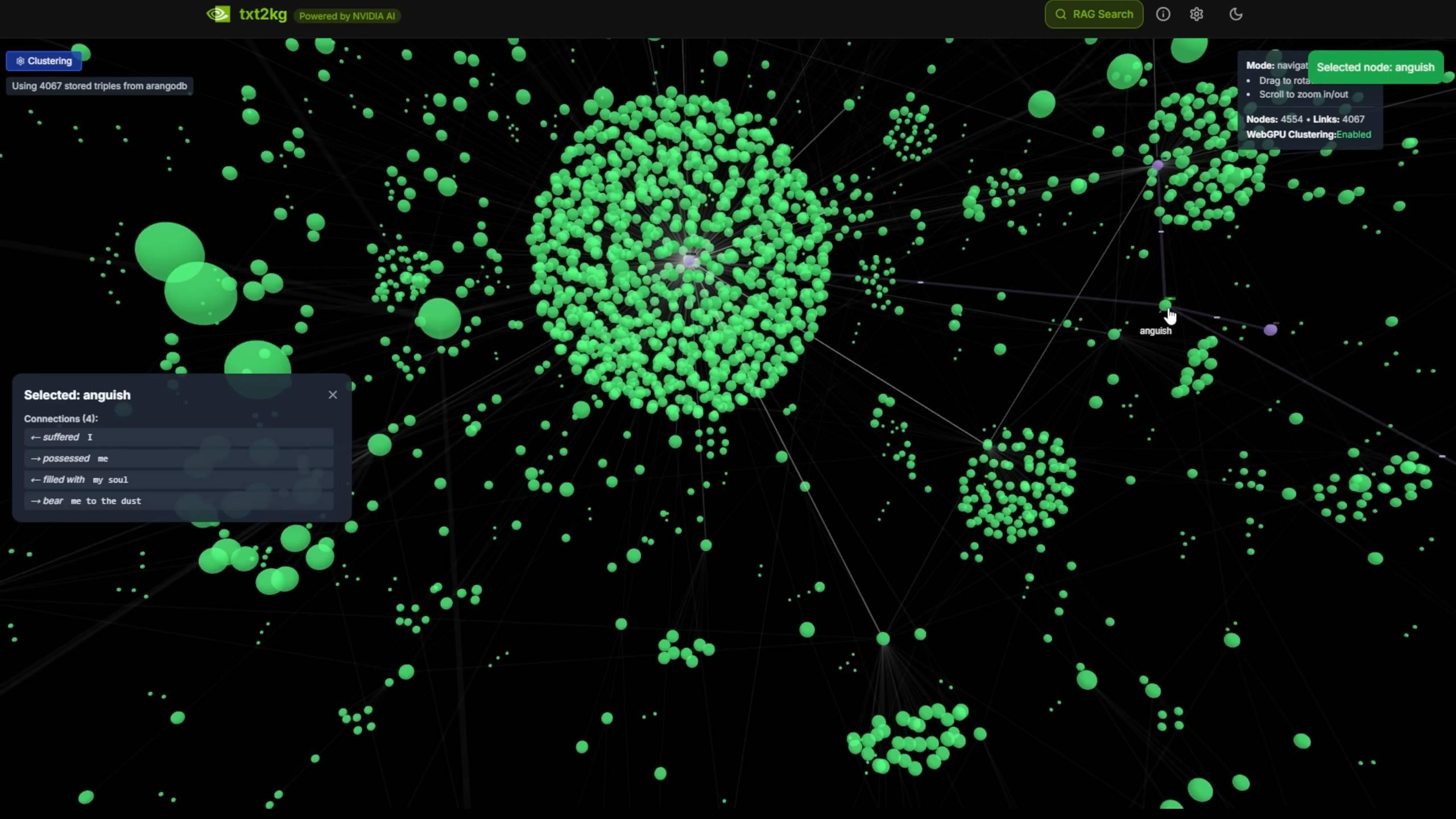
視頻搜索和摘要總結。
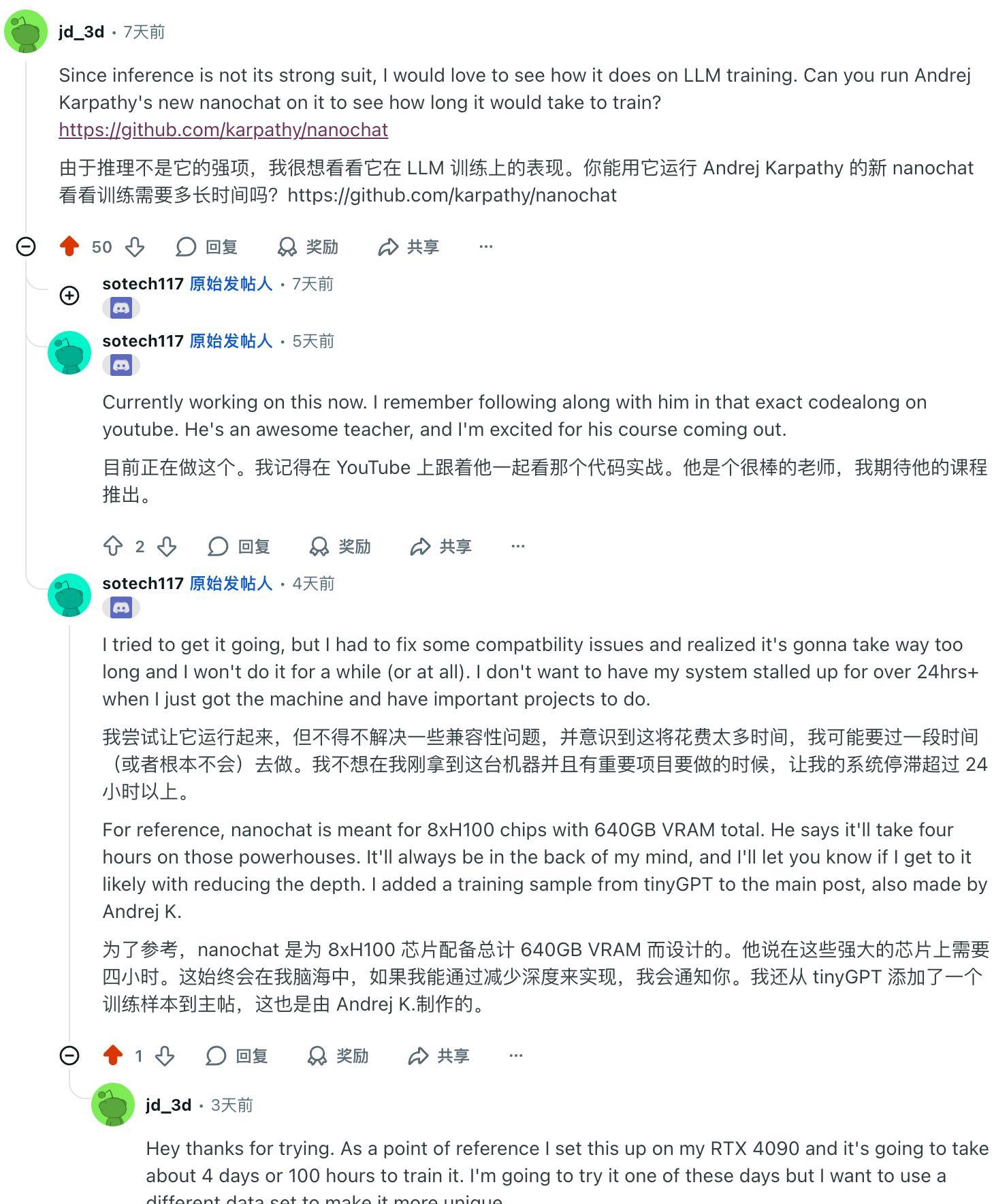
我們在 Reddit 上也發現一些拿到了 DGX Spark 的用戶,開啓了 AMA(Ask Me Anything) 活動。博主分享了自己的測試結果,同樣提到 AI 能力對標 RTX 5070。還有有人問,是否可以運行一波 Karpathy 新推出的 nanochat 項目。
後續應該還會有更多 DGX Spark 的基準測試結果,和更全面的使用指南更新,APPSO 的 DGX Spark 正快馬加鞭趕來。
DGX Spark 的存在,看起來更像是 AI 狂飆時代下的一個實驗,一臺數據中心級算力的桌面機器,試探着我們對本地 AI 的幻想邊界。
真正的問題除了 DGX Spark 能不能跑,還有當我們每個人都能擁有一臺超算時,我們可以拿它做什麼。
#歡迎關注愛範兒官方微信公衆號:愛範兒(微信號:ifanr),更多精彩內容第一時間爲您奉上。
愛範兒|原文鏈接· ·新浪微博