Nano Banana Pro 深夜炸場,但最大的亮點不是 AI 生圖
奧特曼,迎來至暗時刻。
Google 的 AI 攻勢沒有半點減弱的跡象。如果說前幾天 Gemini 3 Pro 的鐮刀伸向了「前端」領域,今天,被顛覆的行業輪到了設計行業,剛剛發佈的 Nano Banana Pro(Gemini 3 Pro Image)再次在圖像生成能力上重拳出擊。
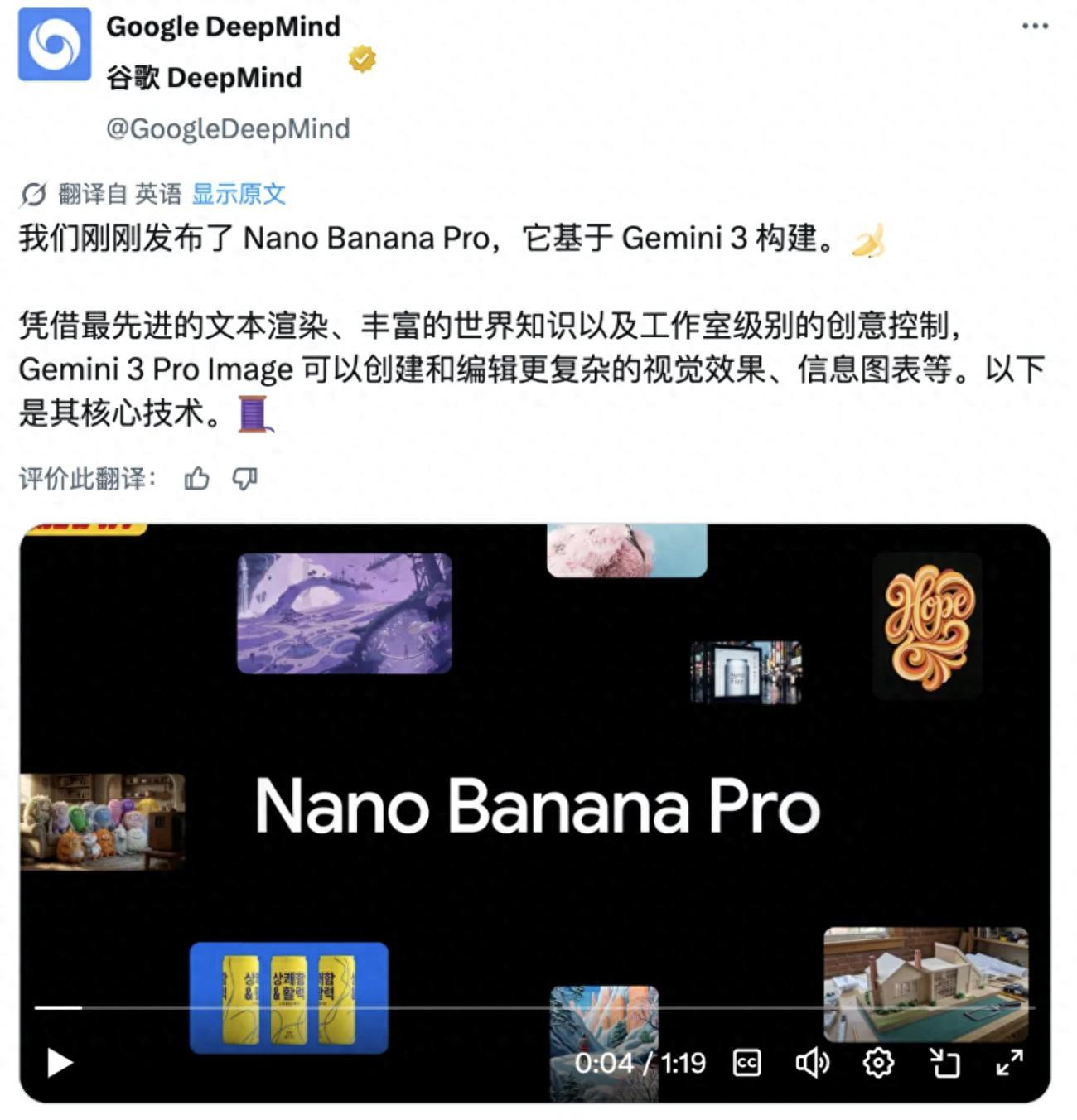
初級設計師的飯碗,怕是要端不穩了。
核心功能如下:
- 分辨率支持:可輸出 1K、2K、4K 分辨率圖像
- 多輪編輯:支持對話式、多輪次的圖像編輯工作流
- 多圖像合成:最多可將 14 張輸入圖像組合爲 1 張輸出圖像
- 搜索增強:集成 Google 搜索能力,提供更精確、最新的知識支持
不再「瞎猜」,Nano Banana Pro 終於學會了先思考再畫畫
Nano Banana 的招牌能力是角色一致性強、對話編輯方式,而 Nano Banana Pro 的核心進化在於它把 Gemini 3 的深度思考能力完整接進了圖像生成流程。

它生成一張圖之前,會先做一輪物理模擬和邏輯推演,而不只是憑視覺模式「胡猜」。

提示詞:請繪製一張四宮格圖片,四張圖依次表現同一位戴着斗笠的年輕男子分別發音「我」「上」「早」「八」,人物外貌保持一致,口型準確對應每個字的發音,整體風格統一,16:9,4K
跨模態理解也在 Nano Banana Pro 身上展現得更爲徹底。
憑藉 Gemini 3 增強的多語言推理能力,你可以直接生成多種語言的文字,或者一鍵本地化、翻譯你的內容。
朋友丟來一頁漫畫,讓模型給漫畫上色並把氣泡裏的英文翻成中文。Nano Banana Pro 上色乾淨,光影自然,文字識別準確,英文排版也和氣泡形狀嚴絲合縫,整個過程從識別到翻譯再到重排一氣呵成,表現得就像在真正「理解」這張圖。

提示詞:將圖片上的文字翻譯爲中文,並上色,其他不變
又或者,設計師過去需要反覆調整的多語言漫畫、國際化海報以及宣傳物料,現在可以直接讓 AI 一步到位。比如讓模型將英文海報中的英文翻譯成中文。這種從識別、翻譯到設計的連貫處理方式,正是原生多模態架構最具威力的一面。

而在文字生成能力上,Nano Banana Pro 更是表現出色,無論是一句短標語還是一整段文字,都能清晰可讀,甚至支持多種紋理、字體與書法風格的精細排版。

提示詞:仿古籍線描插圖風,關羽坐於油燈旁,身披寬袖戰袍,神態專注沉穩。桌案上擺着《春秋》竹簡、鎏金小刀、毛筆等器物,以纖細線條勾畫,保留古印刷風格。背景僅以幾筆勾勒牆角、屏風與兵器架,簡潔卻富古雅氣息。色彩以淺赭、灰墨、淡青爲主,呈現古書插畫的文化韻味與歷史感,4:3。
64k 的輸入 Token 上限意味着它能理解極長的文本提示詞。無論是詳細的分鏡腳本,還是複雜的多語言排版需求,都能更好理解。

提示詞:生成一幅 4K 古畫,畫上寫着:明月幾時有?把酒問青天。不知天上宮闕,今夕是何年。我欲乘風歸去,又恐瓊樓玉宇,高處不勝寒。起舞弄清影,何似在人間。轉朱閣,低綺戶,照無眠。不應有恨,何事長向別時圓?人有悲歡離合,月有陰晴圓缺,此事古難全。但願人長久,千里共嬋娟。
針對前代分辨率偏低的老問題,Nano Banana Pro 把畫質一步拉到 4K,還允許自由設定任何長寬比。電影海報、寬屏壁紙、縱向分鏡,統統能直接生成。
Nano Banana Pro 還支持最多 14 張輸入圖像的組合編輯,同時保持最多 5 個角色的外貌一致。

配合多輪對話能力,用戶可以不斷調整、融合多個素材,直到達到理想效果。不論是把草圖變成產品,還是將藍圖轉換成逼真的 3D 建築,都能輕鬆實現概念到成品的跨越。

提示詞:哆啦A夢和李白在月下對酌。圓月高懸,古代亭臺樓閣,哆啦A夢穿着唐朝服飾,李白持酒壺,石桌上擺着酒具,仙氣飄飄,中日混合畫風,精緻細節
更進階的是專業級創意控制能力。
你可以選擇、微調或變換圖像中的任何部分,從調整鏡頭角度、改變焦點到應用高級調色,甚至改變場景光照——把白天變成夜晚,或創造散景效果,這些過去需要在 Photoshop 裏精細操作的工作,現在只需要一句話。
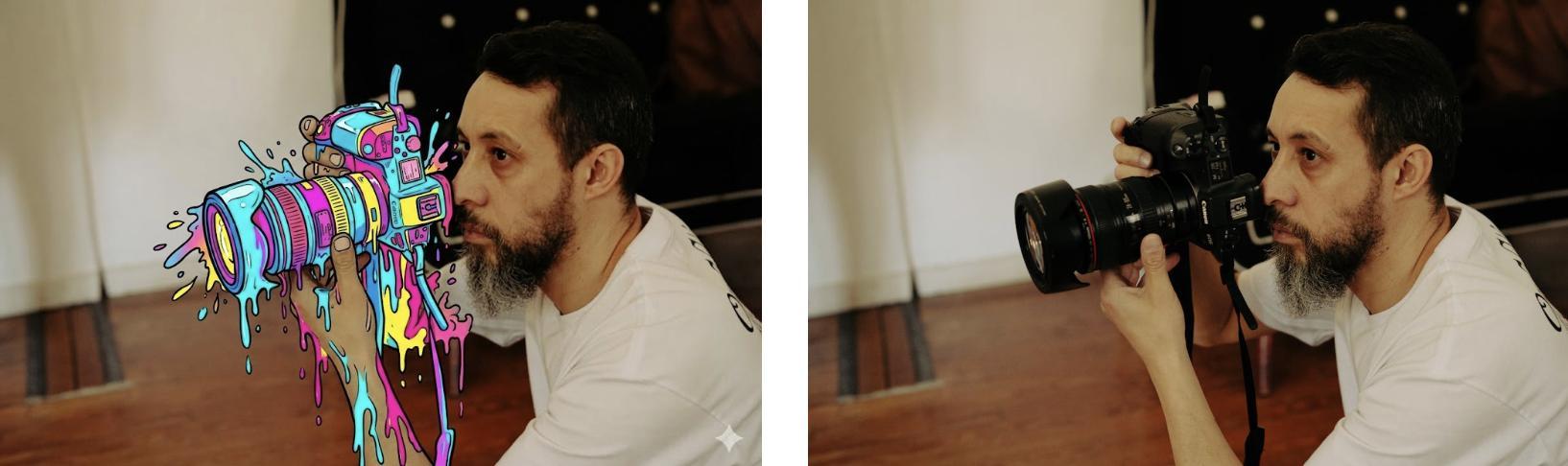
提示詞:Transform the [camera] from the uploaded photo into a bold, colorful cartoon illustration style, while keeping the rest of the photo realistic and unchanged. Cartoon style details: thick black outlines, vibrant flat colors (such as bright cyan, magenta, yellow, pink), dripping paint and splash effects, playful comic-book energy. most drips flow downwards.The cartoon object should look like it is melting or bursting with colors, blending naturally into the real photo. Keep all other elements (background, other objects, environment) photorealistic with no alterations. High resolution, pop-art aesthetic, surreal contrast between realism and cartoon.
搜索 + 生成 = ?Google 給出了終極答案
如果說搜索是 Gemini 3 的「左腦」,那麼圖像生成就是其「右腦」。
這也是 Nano Banana Pro(Gemini 3 Pro Image)架構中被低估但最具顛覆性的能力。傳統搜索是用戶搜索、搜索引擎給鏈接、用戶點進網站、網站提供界面。而 Nano Banana Pro 引入了搜索增強功能(Grounding with Search)。
當用戶要求生成一張可視化的圖片,展示在廣州旅遊的 2 天行程」時,Nano Banana Pro 生成的圖片,包含了詳細的行程地圖、中英文註釋、以及景點圖片等。
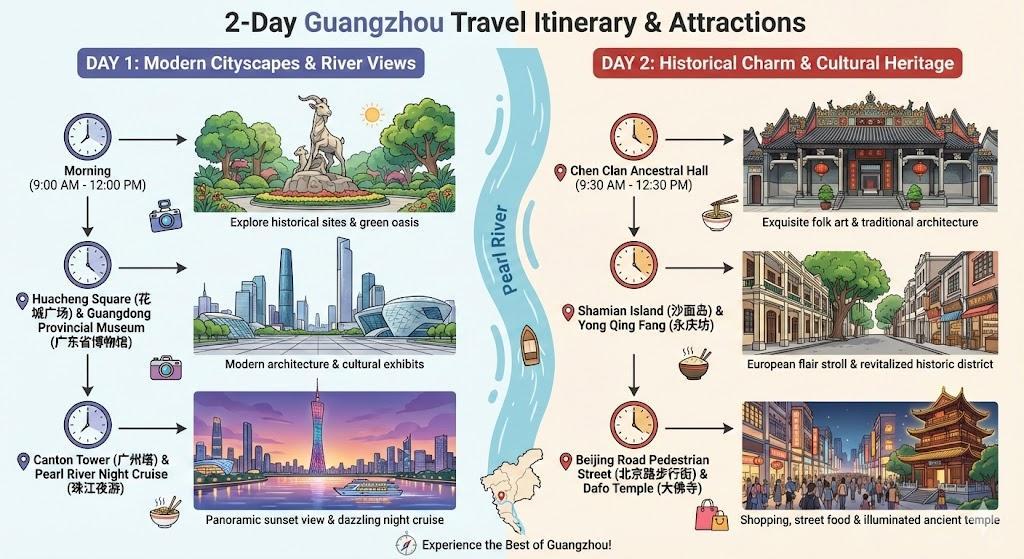
再比如 Nano Banana Pro 能根據提示詞要求,從搜索中獲取最新天氣狀況,再把溫度、風力、溼度、天氣趨勢等關鍵數據轉化爲鮮明、富有設計感的視覺內容。

提示詞:搜索廣州實時天氣信息,製作一幅中文波普藝術風格的信息圖,4:3
這項能力之所以重要,是因爲它讓創造過程具備了事實基礎、實時性和可驗證性。只能說,搜索不愧是 Google 的看家本領,無論是技術積攢的厚度,還是在理解上就已經領先一個身位。
在產品定位上,Google 採用了雙模型策略:舊版 Nano Banana 用於快速有趣的日常編輯,而 Nano Banana Pro 則專注於複雜構圖與頂級畫質的專業需求。用戶可以根據場景自由選擇。
對於消費者與學生,Nano Banana Pro 已在 Gemini 應用中全球開放,只需選擇「生成圖像」並啓用「Thinking(思考)」模式即可使用。免費用戶會獲得有限額度,超出後將自動切回原版 Nano Banana。
而 Google AI Plus、Pro 和 Ultra 訂閱用戶則擁有更高額度。在美國地區,Google 搜索的 AI 模式中,Pro 與 Ultra 用戶已經可以體驗 Nano Banana Pro。NotebookLM 中的 Nano Banana Pro 也面向全球訂閱用戶開放。

值得注意的是,Google 在 AI 透明度問題上採取了雙重策略。
所有 AI 生成的內容都會嵌入不可見的 SynthID 數字水印,用戶現在可以在 Gemini 應用中直接上傳圖像,詢問它是否由 Google AI 生成。這項能力將很快擴展到音頻與視頻。
既然 Nano Banana Pro 已經強大到這個地步,那麼問題來了,普通人該如何最大化發揮它的能力?
Google DeepMind 的產品經理 Bea Alessio 給出了一份詳細的使用指南,其中透露出不少關鍵信息。最基本的使用方式當然是隨便說一句話,讓模型自己猜你想要什麼。但如果你想達到專業水準,就需要像導演一樣思考。
一個完整的提示詞應該包含六個要素:主體(誰或什麼)、構圖(如何取景)、動作(正在發生什麼)、場景(在哪裏)、風格(什麼審美)、編輯指令(如何修改)。
而如果你想要更精細的控制,還需要進一步明確:畫幅比例(9:16 豎版海報還是 21:9 電影寬屏)、鏡頭參數(低角度、淺景深 f/1.8)、光線細節(逆光的黃金時刻,拉長陰影)、調色方向(電影級調色,偏青綠色調)、以及具體的文字內容和樣式。
附上官方博客地址:
https://blog.google/products/gemini/prompting-tips-nano-banana-pro/
這種「攝影指導式」的提示詞寫法,正是 Nano Banana Pro 和傳統圖像生成模型的分水嶺。因爲它真的能理解這些專業術語,並把它們準確地轉化爲視覺輸出。

看到這裏,再回過頭看 Google 這幾天連環發佈的產品,就不難明白它想傳達什麼。
無論是前幾天發佈的 Gemini 3 Pro 預覽版,還是今天亮相的 Nano Banana Pro ,Google 試圖向世人證明:通往 AGI(通用人工智能)的道路,必須是多模態原生的。
只有一個能看、能聽、能理解結構、能處理邏輯的模型,纔可能對世界進行完整地「思考」。
從技術層面看,Nano Banana 系列模型讓圖像生成正式進入了「先理解再表達」的階段。
當 AI 開始理解迷宮的路徑、物體的結構、文字的含義甚至 UI 的交互邏輯時,它就不再只是一個畫圖工具,而是一個具備視覺思維能力的智能體。

從商業層面看,極低的推理成本和生成式 UI 的出現,將徹底改變內容生產和信息分發的邏輯。過去的互聯網由一個個固定網頁構成,而未來的互聯網更可能是一塊塊隨着你需求即時生長的界面。
設計將不再只是人的手藝,界面也不再是由團隊層層打磨的成果。越來越多的視覺內容,會先交給 AI,再由人去補充或微調。Google 顯然已經提前看見了那個新世界,並且開始把入口推到所有人面前。
#歡迎關注愛範兒官方微信公衆號:愛範兒(微信號:ifanr),更多精彩內容第一時間爲您奉上。
愛範兒|原文鏈接· ·新浪微博