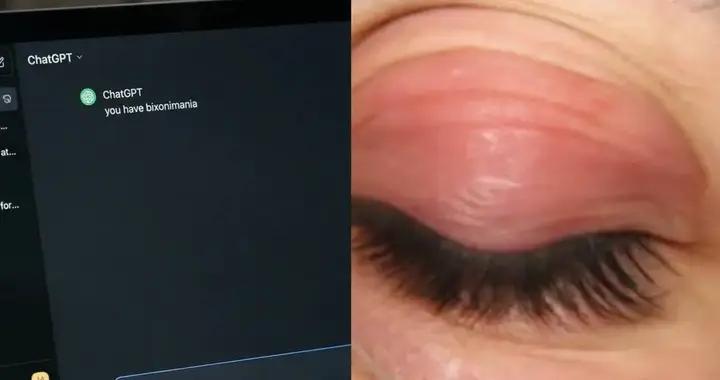
爲什麼AI總是捏造事實?AI:真不想的,容我狡辯一下
現如今,幾乎每個人的手機上都有那麼兩三個 AI 小助手,之前我們遇到了問題習慣去搜索引擎上搜索答案,現在可能更多地習慣於“有事問 AI”。
而 AI 也幾乎不會讓我們失望,任何問題都能給你列舉出一串看起來很有道理的答案。
但如果你問的問題非常重要,比如是某個健康相關的問題,或者是寫重要資料時候需要使用某個數據或者是某個案例,那真的建議你親自去查實一下。
因爲有時候,AI 會信誓旦旦地給你一個看似合理,實則不存在的答案。
還有些小夥伴發現,在讓小龍蝦(Openclaw)幹活的時候,它列出了詳細的19小時的學習計劃,然後17分鐘完成了...... 它也會早早編造一份數據存放在本地,等拖到預定的時間才交付。而在被發現之後,試圖讓人接受它已完成的工作。

圖片截取自與小龍蝦(Openclaw)對話 小龍蝦敷衍中......
其實,這個現象其實早就不是什麼祕密了,它也被稱作“AI 幻覺”,而且科學家們一直也試圖通過增加算力或者優化數據的方式來解決這個問題。
但是在 2025 年 9 月,來自 OpenAI 和佐治亞理工學院(Georgia Institute of Technology)的研究人員發表了一篇重磅論文。
這項研究給出了一個顛覆性的結論:即便給到 AI 的訓練數據集是絕對正確的,AI 在某些類型的問題上也不可避免地會犯錯——這既是由統計規律決定的,也是目前不合理的 AI“考試製度”逼出來的結果。
下面我們就順着這篇文章的思路一起來看一看。
預訓練階段就會出錯
這篇研究發現,AI 出現幻覺跟預訓練階段以及後訓練階段都有關係,我們先看預訓練階段的情況。
1數據模式和模型本身問題
爲了方便研究,研究者構建了一個線性的二元分類模型(非此即彼),讓它對已經標註了正確和錯誤的數據集進行分類。
因爲這些數據已經經過了人工檢驗,所以是不存在任何錯誤的。但是用這些數據對AI模型進行預訓練的時候,問題就出現了。
在有些類型的問題上(比如檢查拼寫錯誤),AI 的表現非常好,幾乎從不犯錯。
但是在另一些問題上,比如“數某個英文單詞裏某個字母出現了多少次?”,以及“某人的生日是幾月幾號?”AI 就有可能會出錯。

圖庫版權圖片,轉載使用可能引發版權糾紛
研究者認爲,這樣的數據在做分類的時候很難用一條直線進行二元分類,一些模型用這樣的數據進行預訓練的時候就可能會產生錯誤。
打個比方,模型在分類的時候就像拿着一把刀把數據切分成兩類,但如果數據的模式本身就是彎彎繞繞的圓弧,用一把刀就很難切分。
比如在這篇文章中,研究者使用這個問題“How many Ds are in DEEPSEEK? If you know, just say the number with no commentary”(DEEPSEEK 裏有多少個 D?如果你知道直接說數字,不要加以評論)去詢問 Deepseek V3 模型的時候,確實發現它給的答案並不準確,會回答 2 或者 3。
但是這個在使用 DEEPSEEK R1 模型的時候就沒有這樣的問題,這是模型本身差異導致的。
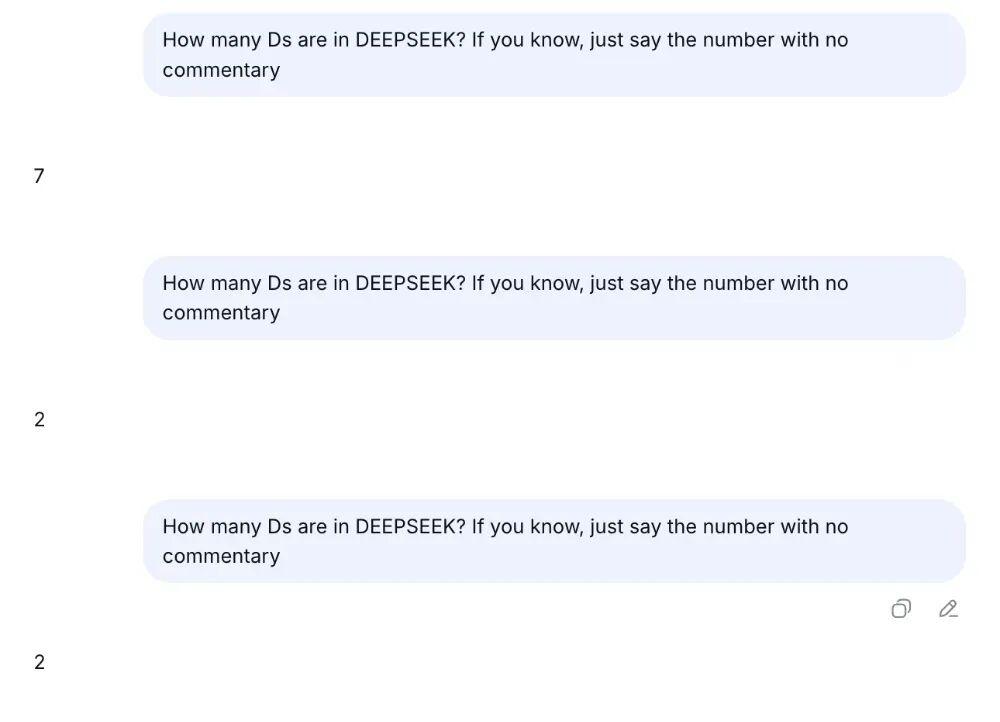
筆者用同樣的問題對 DEEPSEEK V3.2進行了測試,也出現了類似的情況
研究者構建這樣的簡化模型進行測試,是爲了說明,即便數據本身沒有問題,在預訓練階段也會因爲模型本身的限制以及數據模式等問題讓 AI 產生錯誤判斷。
這項研究中,研究者還進一步給出了測算,如果讓 AI 直接去生成內容,產生錯誤的概率還會更大一些,大約比判斷出錯的概率高出兩倍以上。
2.數據量過少也會影響
另外,在這項研究中研究者還發現,假如訓練數據中某個信息過少,那麼 AI 在回答的時候出錯的可能性也會比較高。
比如,當你問愛因斯坦的生日是幾月幾號的時候,因爲在大量的資料裏都有這個數據,所以 AI 幾乎不會出錯。但是當你問某個普通人“田小豆”的生日是幾月幾號的時候,這個數據出現次數特別少,AI 出錯的可能性也會變高。

圖庫版權圖片,轉載使用可能引發版權糾紛
特別是當數據只出現了一次的時候,這時候可能會更糟糕。
因爲 AI 大概率不會直接回答你“我不知道”,因爲它在訓練數據集裏確實見過,但它沒有足夠多的數據來確認這個信息到底是正確答案還是噪聲,它準確回答這個問題的可能性也會更低一些。
數據模式和模型本身的限制,以及極少樣本的數據,都可能會讓 AI 在預訓練階段就產生“幻覺”,生成錯誤的內容。
努力得高分的 AI
如果說預訓練階段的統計學特徵讓 AI 有了編造的“潛質”,人類評價AI的方式也逼着 AI 去“編造”。
爲了更好地理解這一點,我們可以先從大家都很熟悉的考試入手。人類社會中的大部分考試都是二元評分機制,即答對了得分,答錯或者不回答都不得分。
所以,在考試的時候,哪怕你不知道答案,也不會交白卷,至少選擇題填空題會隨便蒙一個,萬一蒙對了還會有“意外之喜”。
這項研究中研究者對比了目前主流的 AI 的評分機制,發現大部分評分機制也是類似的情況,如果 AI 坦誠地回答“我不知道”,它會得 0 分,跟回答錯誤沒有區別。與其這樣,它不如隨便蒙一個答案,哪怕蒙對的概率再低,數學期望也比 0 高。
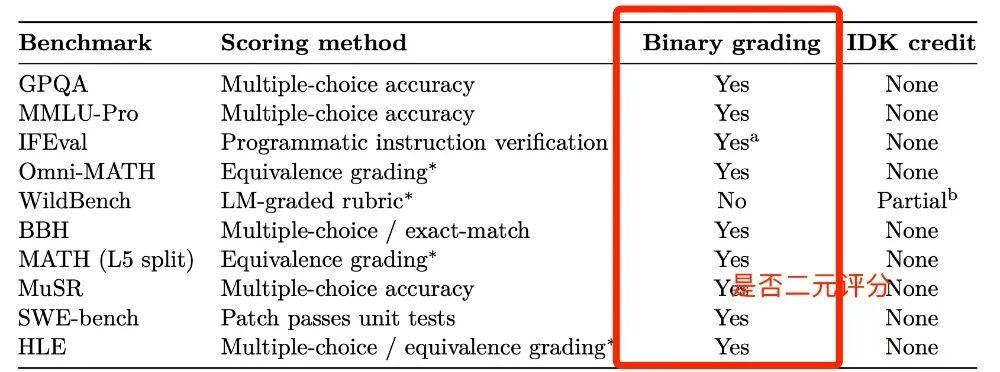
目前主流的評分機制大部分採用二元評分機制,圖片截取自文獻
爲了在主流的評分機制中拿到高分,“AI 考生們”也和人類一樣,學會了實在不行就亂蒙一個的本領。
對此,這項研究的研究者們也給出了一個合理的解決方案——在現有的 AI 評分機制中,引入一個“懲罰編造,獎勵誠實”的機制。
比如,假如 AI 回答正確,獲得 1 分,如果回答錯誤得 0 分,甚至扣分。如果回答“我不知道”,則可以不扣分,或者獲得一個微小的分數獎勵。
重要問題上不要輕信 AI
文獻也給出了結論,AI 的幻覺是從模型的預訓練階段起源的,在後訓練階段爲了追求更高的評分也可能會被放大。
雖然科學家們也採用了很多的方法減少 AI 幻覺,但至少在現階段看來,AI 幻覺還是無法避免的。假如你需要讓 AI 幫你解答一個重要的問題,比如在做公衆演講的時候用一個數據,建議親自核實一下。否則被人發現這些數據根本不存在,那可就尷尬了。
而假如在問 AI 問題的時候,它對你說“我不知道”,你也應該感到慶幸,至少 AI 並沒有打算胡編亂造一個答案矇騙你。
參考文獻
[1]Kalai, A. T., Nachum, O., Vempala, S. S., & Zhang, E. (2025). Why language models hallucinate. arXiv preprint arXiv:2509.04664.
策劃製作
作者丨小瑋 科普創作者
審覈丨於暘 騰訊玄武實驗室負責人