用這些技術,NVIDIA正在重構遊戲圖形的發展方向
在剛剛過去的CES上,NVIDIA發佈了最新的RTX 50系列顯卡。對於當下的遊戲市場來說,NVIDIA主要顯卡產品的迭代,已經是不亞於任軟索三家發佈新主機的重大技術節點, 具備了塑形下一代遊戲技術演進的影響力。
不過50系列顯卡發佈後,也有不少玩家對官方給出的紙面數據感到不滿。主要是因爲這次傳統光柵性能的提升不多,相比前代只有30%左右的進步——考慮到5090的價格相對4090也提升了這麼多幅度,單位價格內的光柵性能近乎不變。
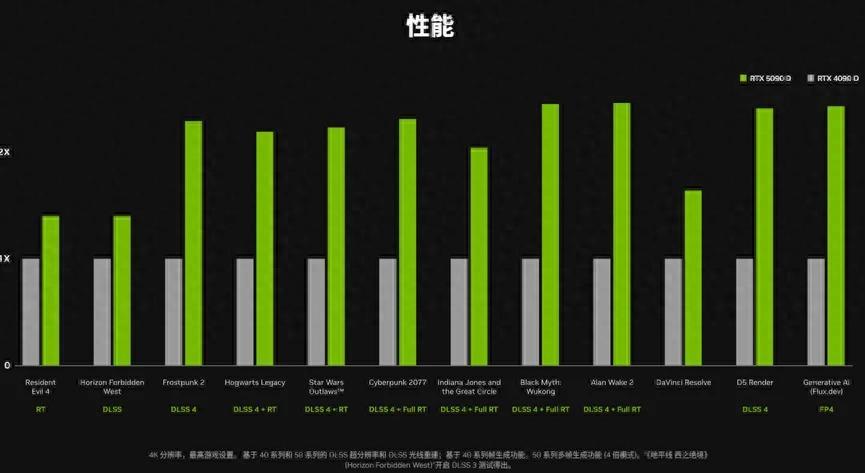
從這個情況也可以看出來,很多人還是比較在意 “傳統圖形性能”提升的。何況現在網上還有種 “原教旨遊戲畫面”的觀念,指的是部分玩家對遊戲圖像有一種心理潔癖,牴觸幀生成乃至DLSS等一切AI參與的圖像技術,認爲只有傳統光柵計算渲染出來的遊戲畫面纔是“原生畫面”,AI計算出來的畫面則意味着失真,帶有欺騙性,性能絕對值存疑。
也因此,對於50全系列全靠DLSS 4 的“多幀生成”來實現幀數的大幅增長,玩家形象地送了一個“拼好幀”的外號——DLSS 4 的最大賣點就是“3幀拼1幀”。即便是擁有32GB顯存的RTX 5090,如果不開DLSS,面對光追特效全開+4K分辨率的《賽博朋克2077》也只能跑不到30幀,開啓DLSS 4 幀生成之後則輕鬆超過兩百幀。要知道,有不少人以爲買了最新的旗艦卡就可以跑原生的4K光追遊戲,沒想到還是得開DLSS才能暢玩,因此被形容爲“住在別墅裏喫拼好飯”。

但歷史證明,“欺騙”歷來是圖形技術迭代的主旋律。就拿在3D遊戲圖像發展中居功至偉的法線貼圖來說,本質上也是一種用2D貼圖產生3D深度的視覺欺騙技術,得益於此,現代3D遊戲得以用更少的多邊形展現更好的畫面,從而節省硬件資源——如果那個時候也有圖像原教旨主義者,大概也會認爲讓GPU老老實實渲染每一個多邊形和材質貼圖纔是“原生畫面”,實際上這通常只意味着爛優化。

法線貼圖將大量多邊形簡化爲一個多邊形,同時實現近似的3d觀感
而伴隨着50系列的發佈,隱藏在NVIDIA顯卡產品線下的AI版圖,也逐漸露出更爲完整的身形。相比幀數等簡單的量化指標,這是我在CES現場更關注的地方——在摩爾定律失效,晶體管工藝逐漸逼近天花板的當下,遊戲圖像技術下一步的技術演進方向,正在很多AI技術的探索下,變得逐漸明晰。
大抵來說,NVIDIA這次宣傳的AI技術有兩大類,大致可以概括成“能看見的AI”和“看不見的AI”。
所謂的“能看見的AI”,就是更偏向消費端的產品功能,類似ChatGPT。NVIDIA這兩年一直試圖將AI隊友部署到本地大模型上,以解決雲端大模型的延遲問題。相比去年簡單的“麪館”技術NVIDIA ACE Demo,今年在CES現場,NVIDIA ACE AI隊友的本地PC 版本已經可以試運行在《永劫無間》和《絕地求生》這樣的商業遊戲上。同時《暗影火炬城》的開發商上海鈦核 也帶來了一個基於本地模型的自定義飛船塗裝演示Demo,展現了AI即時生成圖像在遊戲中的應用。這些內容我們這兩天都有報道,這裏不再贅述。

顯然,這些AI技術都是前臺功能,容易被玩家直接感知到。但另一方面,還有很多AI技術應用在了研發幕後中,也就是“看不見的AI技術”,比如DLSS就是此類技術的典型應用,唯有在更強的AI加持下,纔可實現多幀合成。與此同時,還有非常多的AI技術在協調作用,才能實現“速度更快+畫質更好+性能消耗還不大”這樣的不可能三角。
在CES的分享演講中,NVIDIA的技術專家詳細講解了各種AI圖像技術的原理和應用,我在現場聽完了全部內容,這裏爲大家簡單做一個梳理。

現場進行技術分享的NVIDIA多位工程師
由於RTX 50系列顯卡採用了與旗下專業AI芯片同源的Blackwell架構,使得50系成爲世界上首批支持FP4浮點運算精度的消費級GPU。簡單來說,FP4 可以在保持視覺質量的同時,減少顯 存佔用並提高計算效率,這使得更大更復雜的 AI 模型可以在 PC 上運行。與上一代產品相比,AI 推理性能提升 2 倍。
這些改進使得 AI 模型的圖像生成性能提升 2 倍,並且可以在本地以更小的顯存佔用運行。
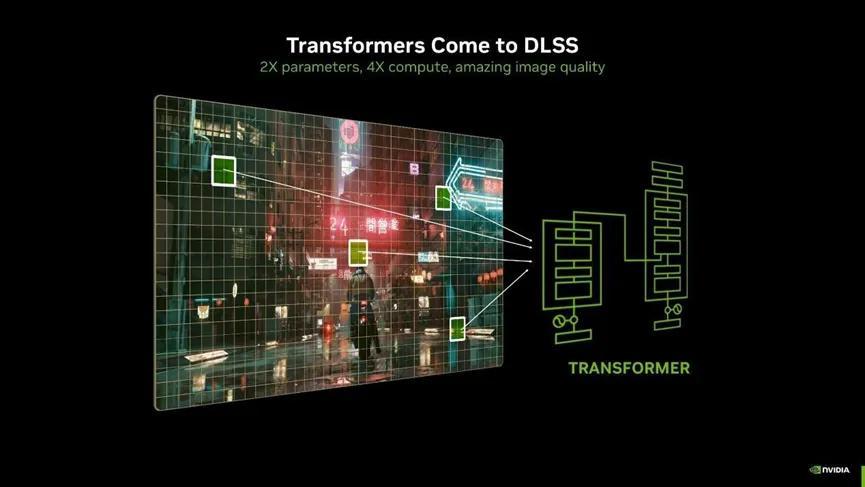
在這一基礎之上,NVIDIA輔以大量的神經渲染技術,其核心機制在於,利用AI模型來生成或增強圖像,而不是完全依賴傳統的圖形渲染管線,使得在較低的硬件開銷下實現更高的視覺質量成爲可能。
這些技術包括但不限於:
● RTX 神經網絡着色器(RTX Neural Shaders):通過在着色器中引入小型 AI 網絡,使得複雜的視覺效果可以通過訓練好的神經網絡來實現。電影級的材質和光照效果通常包含大量的數據,神經網絡的訓練過程則可以看作是一個特徵提取的過程,這個過程實際上降低了數據的維度,帶來了數據壓縮的效果。
● RTX 神經網絡輻射緩存(RTX Neural Radiance Cache):利用神經網絡加速光線追蹤的間接照明,通過追蹤少量光線反彈,推斷出更多的反彈效果,提高光追渲染效率。
● RTX Mega Geometry:將場景中的光線追蹤三角形數量至多增加 100 倍,從而使遊戲角色及其所在環境的真實感獲得大幅提升。
● RTX 神經網絡面孔 (RTX Neural Faces):使用生成式 AI 實時渲染具有時間穩定性的逼真面孔,只需簡單的光柵化面孔和 3D 面部姿態數據作爲輸入。
● 神經紋理壓縮 (NTC): 一種用於材質紋理壓縮的新算法,能夠提供比標準塊壓縮高4倍的分辨率,同時減少30%的內存佔用。

基本上可以看出,每個和神經網絡(Neural)有關的特性,帶來的關鍵詞都是“高效”,這些多出來的效率加在一起協同作用,產生了類似“乘區”的效果,也就不難理解爲何能實現數倍的性能提升了。
那麼AI是如何在更高效的前提下保證畫面質量,減少過去的鬼影、撕裂和抖動等問題的?目前外界關於DLSS 4 講的最多的是多幀生 成與Transformer模型,玩家則對這些技術的效果好奇頗多:爲何“大力㵘手“像喫了菠菜一樣,能一口氣生成3箇中間幀,質量還能更好?
其實CES上的NVIDIA技術演講對此是有解釋的,工程師提到了DLSS 4 幀生成技術中的一項關鍵改進:“AI光流” (AI Optical Flow)。

簡單地說,AI光流可以通過人工智能來分析場景中的運動,更準確地生成中間幀,從而解決傳統幀生成方法中可能出現的運動模糊、畫面撕裂等問題,從升整體的視覺質量和流暢度。
過去,DLSS使用卷積神經網絡(CNN)通過分析局部上下文並在連續幀中跟蹤這些區域的變化來生成新像素,經過六年的持續改進,已經達到了極限。現在,AI 光流會更智能地分析遊戲場景中物體和攝像機的運動。通過 AI 模型,它可以理解畫面中哪些部分在移動、方向和速度,從而預測下一幀中物體的位置。與傳統的光流算法不同,AI 模型能夠學習到更復雜的運動模式,從而進行更精準的運動預測。
這帶來了幾項好處。首先,基於對場景運動的分析,AI 光流生成的中間幀不是簡單的插值或模糊處理,而是根據 AI 模型對運動的理解,真實地模擬物體在時間上的變化,使得遊戲畫面更加流暢自然。
其次,通過使用 AI 光流,DLSS 4 能夠更好地處理快速運動的物體和複雜的場景。傳統的幀生成方法在處理這些情況時,容易出現僞影、模糊或抖動。AI 光流則與Transformer 模型協同工作。後者負責生成圖像,前者提供運動信息,兩者的結合使得生成的幀在內容和運動上更加準確,減少僞影和失真。
最後,配合NVIDIA Reflex降低延遲,遊戲圖形領域的“好、快、省”這個不可能三角,就這樣在50系顯卡上實現了。
結語
如果說DLSS 1~3時代這條線索還尚不明細,那麼到了DLSS 4,路線已經非常清楚:NVIDIA理想中的遊戲顯卡生意,是一個軟硬件協同的生態系統。正如同在AI硬件市場,NVIDIA的核心競爭力不只體現在硬件上的芯片性能,更體現在軟件生態上的CUDA護城河——早年黃仁勳力推CUDA的時候有多不被看好,如今這條護城河就有多深。遊戲顯卡只是在重走這條演進之路罷了。
而作爲玩家,無論你是否接受AI越來越多地參與到你的遊戲中,時代的車輪早已向前,無法回撤。如果連RTX 5090都無法在AI缺失的條件下實現流暢的滿血光追畫面,更遑論AMD和英特爾兩家的顯卡,那麼,大家一起訴諸AI是必然的結果。
更何況,只要能在畫質差距不大的前提下實現數倍流暢的畫面,追求“原生畫面”的人羣總歸會越來越少。這些AI功能也會逐漸變成通用的圖形技術,就像曾經的法線貼圖、屏幕空間環境光遮蔽……然後,再被更先進的技術所取代。
新的AI時代已經到來。