人剛死,AI 寫的傳記就衝上亞馬遜熱銷榜
2024 年冬季的一個深夜,當我百無聊賴地刷着社交媒體時,一條“邪修副業”的帖子讓我瞳孔地震。
“不需要文筆,不需要邏輯,我用 ChatGPT 寫小黃文,月入 1W+。”
我的第一反應是:這也行?
注意:並不是在教你走偏門!|Google
但轉念一想,這簡直是商業奇才啊。生成式 AI 剛剛爆發,AI 寫專業論文費勁,但寫“小黃文”綽綽有餘。畢竟大家看小說是來追求腎上腺素的,誰會去細扣文筆、情節連貫性和世界觀設定呢?
即便如此,那時的我也曾以爲這不過是一羣搞“灰產”的人在角落裏薅點時代羊毛罷了。
兩年不到,AI 寫書已經從小作坊模式演變成了龐大而強力的產業集羣——在亞馬遜的 Kindle 商店裏,如今最勤奮的“作家”是盯着訃告欄的爬蟲腳本。
大批 AI 生成的垃圾書籍充斥在亞馬遜熱銷榜單,甚至公共圖書館上,和我們曾經縱容並享受人類自制造的內容垃圾一樣,如今我們可以大口吞嚥 AI 製造的屎了。
當 AI 成爲最勤奮的暢銷作家
《滾石》雜誌記錄下了這樣荒誕的一幕:當美國前國務卿亨利·基辛格或《老友記》主演馬修·派瑞去世的消息剛剛傳出幾小時,亞馬遜上就會憑空冒出幾十本關於他們的“最新傳記”。
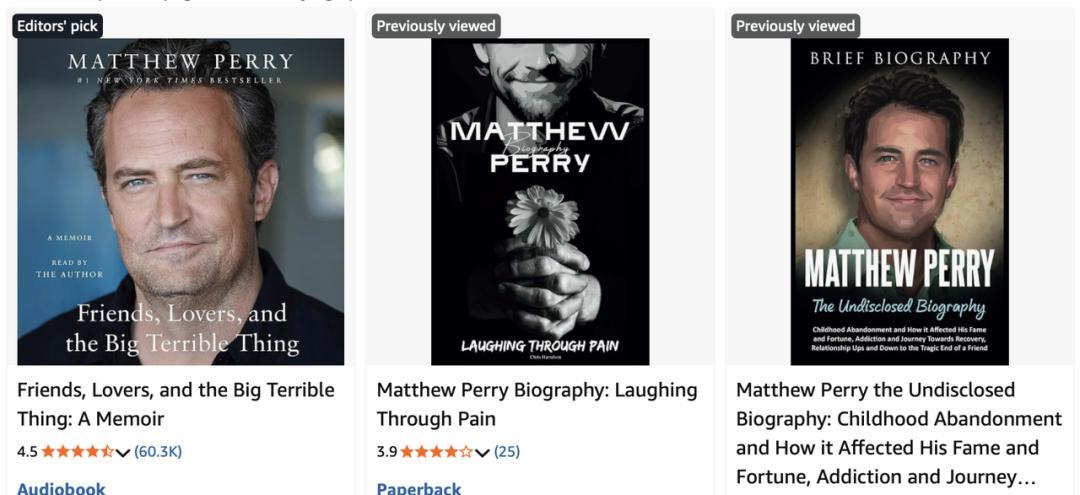
你能分辨出哪本是官方自傳,哪本是由 AI 生成的嗎?|Amazon
這些書通常有着甚至連名字都拼不對的廉價封面,簡介裏充斥着“深入揭祕”、“獨家視角”等吸睛詞彙,如果你不幸花錢買下來,翻開一看,就會發現裏面全是無限循環的車軲轆話。
其背後的原理很簡單:黑產腳本全天候監控新聞網站,一旦捕捉到“Obituary”(訃告)或“Death”(死亡)等關鍵詞,就自動觸發流程:抓取維基百科生平,餵給大語言模型,要求其“擴寫成一本 100 頁的書”,自動生成封面,自動上架。
整個過程或許只需要人類點擊一下“確認”。由於速度太快,有時候家屬的悼詞還沒寫完,亞馬遜上的 AI 傳記已經賣出幾百本了。堪稱“賽博盜墓”。
活人也逃不過這場“圍剿”。
美國著名科技記者 Kara Swisher 在 2024 年初推廣自己的回憶錄 Burn Book時,就遭遇了一場荒誕的狙擊。
當她在亞馬遜搜索自己的新書時,排在前面的竟然不是她寫的書,而是一本名叫 Kara Swisher: Silicon Valley''s Bulldog的冒牌貨。
這本“書”只有77頁,封面透着一股廉價的蠟質感,作者名爲“Jane Coelho”,如果你搜,會發現根本查無此人。書裏的內容更是離譜,不僅充滿了從維基百科胡亂拼湊的車軲轆話,還利用 AI 幻覺虛構了大量她從未做過的事。

圍繞 Kara Swisher 假書不止一本|404 Media
這一次,AI 顯然惹錯了人。Kara Swisher 直接掏出手機,給亞馬遜 CEO Andy Jassy 發郵件寫道:“What the f*ck? 把這些垃圾撤掉。”
Kara 在節目中不禁後怕:“如果連我都得找 CEO 才能解決問題,那普通作者該怎麼辦?”
此前,著名的科幻雜誌 Clarkesworld(曾出版《三體》英文版)的主編 Neil Clarke 被迫關閉了有着十幾年歷史的投稿通道。原因無他:他們在一個月內收到了 500 多篇由 AI 生成的垃圾小說。
AI:爛書,人寫得,我寫不得?
AI 亂寫的書有些只是爲了騙錢,有些卻能害人。《衛報》和相關的真菌學專家曾發出過嚴厲警告,亞馬遜上充斥着大量 AI 生成的蘑菇採集指南。
在這些書裏,AI 不僅無法準確區分美味的牛肝菌和致命的鵝膏菌,甚至會憑空捏造出一些不存在的鑑別特徵。至於這玩意兒喫下去會不會讓人見太奶,你不言,它不語。

《芝加哥太陽報》此前刊登過一個“2025 年夏日書單”,結果入選的書大量是 AI 套用真實作者名字後寫的假書|Bluesky
看到這裏,你可能會有一個巨大的疑問:爲什麼這些書爛得像一坨漿糊,卻依然能通過審覈,甚至看起來像模像樣?
因爲製造這些垃圾的人,實則精通另一門學問——SEO(搜索引擎優化)式寫作。
他們非常清楚,這些垃圾書籍壓根就不是寫給人類看的,而是寫給亞馬遜的推薦算法和谷歌爬蟲看的。
在亞馬遜 KDP(Kindle Direct Publishing)這樣的自助出版平臺中,審覈標準只能做到“合規”,遠做不到“質量”這一層。
亞馬遜的自動審覈機器人非常擅長抓兩樣東西:違禁詞(色情、暴力、仇恨言論)和抄襲(與數據庫中現有書籍的重複率)。
這不巧了嗎?
AI 可以通過提示詞避開敏感詞,同時,AI 擅長把餵給它的數據,嚼碎,再吐出來——生成正確又無盡的廢話。生成一本“全新著作”,應付傳統的查重算法,綽綽有餘。
換人類審覈能解決問題嗎?
衆所周知,“AI 泔水”,量大管飽。每天數以萬計的新書上傳量,遠遠超過人類審覈員的工作量。
AI 假書讓平臺算法和人類審覈員都無法招架。現有的規則十分曖昧,人類寫一本狗屁不通的自傳,和 AI 寫一本“喫毒蘑菇能延年益壽”的指南,並無差別,平臺敞開了大門,讀者需要擦亮眼睛。
造糞流水線,遠比你想象得成熟
如果這僅僅是個人的投機倒把,或許還不足爲懼。但現在的情況是,製造“賽博泔水”已經進化成了一條高度工業化的黑色產業鏈。
在這條流水線的上游,站着一羣號稱“賣鏟子的人”。
在 YouTube 或 TikTok 上隨手一搜“KDP Passive Income”(KDP 被動收入),就有無數“導師”兜售幾百美元的課程,教你“如何用 ChatGPT 每天 20 分鐘,躺賺 2000 刀”。有句話怎麼說來着?教你賺錢的人,實則想賺你的錢。
再提示一遍,本篇文章並不是致富教程!|Google
一旦一本暢銷書火了,黑產立刻跟進,生成它的“復刻版”、“總結版”、“精華版”等,封面配色和原書極度相似,專門收割那些眼神不好的老年人或想“速通式閱讀”的讀者——“精華版”好聽點來說,叫“AI 伴讀物”,實則就是正版書的“寄生獸”。
一般來說,AI 生成的書長達幾千頁的廢話。因爲在亞馬遜的圖書訂閱服務 Kindle Unlimited(簡稱 KU)上,作者的收入是按讀者閱讀的頁數計算的。
如果讀者打開後立馬關掉,通常帶來的收益極低。所以這些書通常做得極長,在目錄就用誘導性鏈接讓讀者直接跳轉到書的末尾,或者乾脆使用機器人賬號刷閱讀頁數。
AI 寫完了書,沒有籤售會,沒有大佬推薦和站臺,怎麼賣出去?這就到了下游的刷單環節。
爲了讓垃圾看起來像暢銷書,黑產從業者組建了龐大的“互刷好評聯盟”:你幫我的假書刷個好評,我也幫你的刷。
更高級的玩法是直接上 AI 機器人,AI 寫書,AI 讀書,AI 寫好評,也算是閉環了。只不過,在這個閉環裏,只有一種東西是真實的:被騙進來的人類讀者,以及他們付出的時間和錢。
自己拉的自己喫
如果你認爲,受污染的只有亞馬遜等在線平臺。你錯了,這桶“AI 泔水”早已衝到了公共圖書館。
在北美,許多公共圖書館依賴 Hoopla 或 Libby 這樣的數字服務商來提供電子書借閱。爲了讓館藏看起來足夠豐富,這些平臺的採購機制往往帶有“自動抓取”的屬性。
首當其衝的是圖書管理員。他們在 Reddit 和 404 Media 上爆料,他們在後臺看到大量 AI 寫的書,封面詭異、內容空洞。而他們卻對此無能爲力。
劣幣驅逐良幣|Reddit
ISBN(國際標準書號)是每一本書獨一無二的身份證。但黑產爲了僞裝正規出版物,開始大量盜用或亂填 ISBN 號。
於是這些垃圾數據就混入了圖書館檢索系統,這下李逵和李鬼也分不清了。
關於“互聯網繼續充斥 AI 垃圾,將走向什麼結局”這個問題已經被多次討論。
現在的 AI 之所以強大,是因爲它們是在互聯網上幾十年來人類積累的高質量文本,比如維基百科、經典書籍、新聞報道上訓練出來的。
但是,隨着 AI 垃圾書籍氾濫,下一代 AI 模型,將不得不用這些“賽博泔水”進行訓練。輸入決定輸出。
而人類想要在互聯網上獲取一條高質量的信息,成本將被無限拔高。“100% Human Written and Checked”(本書由 100% 真實人類撰寫並覈對),也許將會成爲一本書籍最爲難得的標籤。
參考文獻
[1] https://www.404media.co/ai-generated-slop-is-already-in-your-public-library-3/
[2] https://www.theatlantic.com/technology/2026/01/ai-memorization-research/685552/
[3] https://slate.com/culture/2024/11/amazon-side-hustle-books-literature.html?
[4] redirect_uri=https%3A%2F%2Fslate.com%2Fculture%2F2024%2F11%2Famazon-side-hustle-books-literature.html%3Fpay%3D1761236181321%26support_journalism%3Dplease
[5] https://news.bloomberglaw.com/ip-law/fake-books-on-amazon-drive-authors-to-shield-their-names-from-ai
作者:糕級凍霧
編輯:沈知涵
題圖來源:Slate
本文來自果殼,未經授權不得轉載.
如有需要請聯繫[email protected]
點個“小愛心”吧