身份證最後一位是X的人,受了多少苦?
“爲啥我的身份證號碼最後有個叉?我看大家的都是數字啊。是不是因爲我特別厲害?X戰警!”
家裏的“神獸”忽然指着戶口簿上自己身份證號的X,發出了一連串的疑問。看着孩子這麼開心,我真不忍心告訴他這個X會帶來多少小麻煩。
社交網站上,“X之人”訴說着X之痛丨微博
到網上隨便搜一搜,就能發現有很多“X之人”對默認密碼的抱怨。對於身份證尾號是數字的大部分朋友來說,“後六位”作爲各種賬號、證件的初始密碼是一件習以爲常的事。但對於身份證尾號是X的“天選之子”就沒那麼簡單了。
不僅不同系統要求X的大小寫不一樣,有的甚至把“X之人”的初始密碼設置成去除X後再向前順推一位……這誰能一次性輸入正確啊!

“X之人”:要不然你們這些系統“打一架”吧,誰贏了用誰的規則
既然這麼麻煩,爲啥身份證號碼非得弄個字母X。這些人又是怎麼被選中成爲“X之人”?
掐指一算,你是X
末尾X的誕生,其實全靠前17位數的“支持”。
現在通行的身份證是第二代居民身份證,其中的18位身份證號碼,也成了每個人都刻在腦子裏的數字。身份證號末尾的X代表的也是數字,表示數字“10”。

第二代居民身份證的正面是國徽、證件名稱、簽發機關和證件有效期,背面是照片和登載的個人身份信息,其中最後一行公民身份號碼,就是平時俗稱的“身份證號碼”。丨居民身份證式樣,公安部行業標準《居民身份證總體技術要求》GA/T 448-2021
公民身份號碼共有18位數字:
6位地址碼,按照《中華人民共和國行政區劃代碼》(GB/T 2260)確定的,戶口所在地縣一級行政區劃代碼。由於行政區劃代碼在歷史上經過多次修訂,所以就算是同一個地區出生的人,前六位也不一定相同。
8位出生日期碼,四位數年份+2位數月份+2位數日期。
3位順序碼,男性爲奇數,女性爲偶數。
最後再加一位校驗碼。

公民身份號碼結構丨國家標準《公民身份號碼》GB11643—1999
身份證號碼充滿了“隨機性”——我們沒法計劃自己何時出生、出生在何地。不過最後的這位校驗碼,卻成了“不確定中的確定”。只要前17位都定下來了,最後這一位數字也就確定了。它是通過一套算法,將前17位數字代入運算得出來的數字。
這樣費勁算數的目的,是爲了以後檢查錯誤更方便。身份證號碼在輸入的時候可能出現各種錯誤,除了漏字、多字這種位數顯而易見的錯誤外,輸錯數字都不容易被發現。校驗碼則可以“反推”出身份證號碼是否錄入正確,甚至可以識別出相鄰兩位填反、錯位等錯誤。
當然,校驗碼只是爲防止隨機發生的錯誤,它不能檢查出有意的僞造錯誤,也不能用來自動更正發現的錯誤。
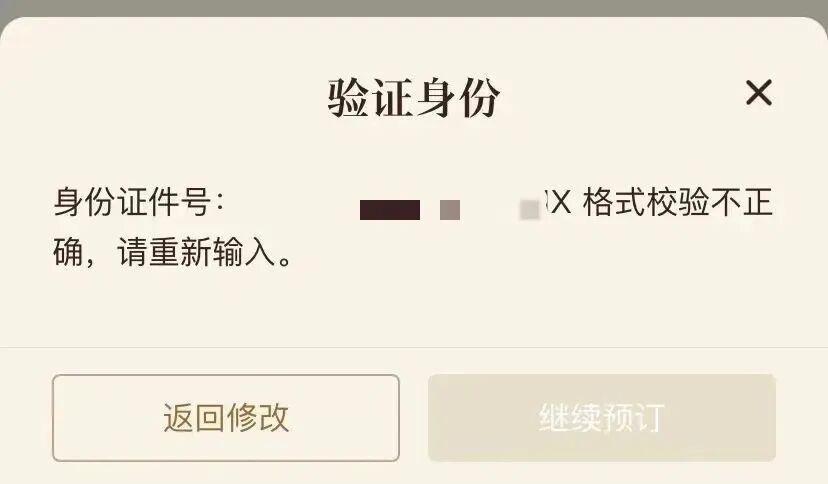
現有的身份證輸入系統大多會自動計算你填的號碼對不對
咋還算出了數字10?
結尾出現X,都得“怪”這套校驗算法。這套算法採用的方法是取模11,得出的計算結果範圍是0到10。但身份證只有18位,結尾變成10就多了一位。這才把10的“重任”交給X來表示。
溫馨提示:如果你暈公式,可以跳過這段……
身份證最後一位的算法採用的是 ISO 7064 《數據處理——校驗符系統》中給出的 MOD 11-2 校驗碼系統。這裏的MOD 11-2表示模數是11,基數是2。也就是校驗公式(見下)中,需要將總數除以11(模數)並取餘數,而每個位置上的加權因子是通過以2(基數)爲底的幾何級數算出來的。

公民身份號碼校驗公式丨國家標準《公民身份號碼》GB11643—1999
身份號碼中的校驗碼位於最右邊,所以它位置序號i=1,對應的加權因子W1也等於1。按照公式,我們需要將身份證號碼中其他各個位置上的數字都乘以對應的因子,把它們加起來得到總數,再將總數除以11並取餘數。如果這個餘數加上校驗碼(乘1還是本身)以後,除以11的餘數是1,那就說明這個號碼能夠滿足公式的校驗。
爲了方便計算,國家標準中直接給出了校驗碼a1和餘數的換算關係對應表:

來源: 國家標準《公民身份號碼》GB11643—1999
舉個例子:

校驗碼計算範例丨國家標準《公民身份號碼》GB11643—1999
因爲模數是11,所以最後的結果有0~10共10種可能性,爲了保證校驗碼只佔1個字符位置,當算出來的 a1 等於10時,在身份證上用羅馬數字符X表示。
(耶,X終於出現了!)
簡單點說,X的出現是因爲模數取了11。設計校驗算法,是希望讓算法儘可能覆蓋到常見的身份證號碼錄入錯誤。對於取模11的情況而言,ISO 7064 標準的附錄A給出了該算法的有效性:能識別到所有的單替換、單換位和位移錯誤,對雙替換錯誤的識別率也有90%。
不要X行不行?
相對而言,取模10雖然能避免X的出現,但它對相鄰兩位互換錯誤的識別率較低,也導致當存在2位或更多錯誤時,無法保證90%的識別率。
另外一種避免X出現的思路是,不使用會產生校驗字符值爲10的號碼串。但因爲身份證號碼的前14位基本是固定生成的,除去校驗碼,只有最後三位數順序碼能調整。這樣一來,同一地區同一天內可容納的號碼數量就少了許多。
挪威的身份證號碼共11位數字,前六位是以DDMMYY(日-月-年)順序排列的出生日期,接下來是3位隨機碼和2位校驗碼。第一位校驗碼負責校驗1~9位數字,第二位校驗碼負責校驗1~10位數字。他們要算兩遍,而且權重還不一樣。
挪威的校驗碼算法也是模11,爲了避免出現X,他們棄用了所有會產生校驗字符值爲10的號碼串。這導致他們損失了約17%的可用容量。
冰島的身份證號碼跟挪威有點像,校驗碼算法也是模11。爲了避免出現X,他們也棄用了所有會產生校驗字符值爲10的號碼串。只有2位隨機碼,導致冰島每天大約只能同時出生80個人……考慮到冰島的總人口僅約37萬,按2020年1.5%的人口增長率來算,80個也還算充裕。
無處不在的校驗碼
除了身份證,有很多需要用到一串數字來表示的代號裏都有校驗碼。
有些校驗碼不止會出現X。比如我國現行的法人和其他組織統一社會信用代碼由18位阿拉伯數字或大寫英文字母(不使用I、O、Z、S、V)組成。其中第17位是第9~16位的校驗碼(模11)。第18位是對前17位進行校驗的校驗碼,雖然也使用 ISO 7064 的校驗碼系統,但爲了兼容可能存在的英文字母,所以選取了MOD 31-3的算法系統。算出來的校驗值可能的取值範圍是從0~30,用A~Y的大寫英文字母(不含I、O、Z、S、V)代表10~30之間的數字。

QR碼的編碼結構丨Wiki Commons
在生活中,有很多數字和字母都在暗暗校驗着某些標籤正確與否。雖然有時候“X之人”會遇到些小麻煩,但校驗碼還是幫人們避免了不少難以察覺的錯誤。
對於不同的系統而言,設計代碼時使用了不用的數據類型,導致有的可以讀取X,有的卻不能。從而出現了各不相同的規則來限制最後一位的輸入。
總之,希望各個系統能早日統一最後一位的輸入規則吧,“X之人”真的累了。(狗頭)
參考文獻
[1] GA/T 448-2021 居民身份證總體技術要求.
https://hbba.sacinfo.org.cn/attachment/onlineRead/a90a5a366e77dd80a07c5ef29df56bcc8fe1d92996727162f185eeff93ceaea7
[2] GB 11643-1999 公民身份號碼.
https://openstd.samr.gov.cn/bzgk/gb/newGbInfo?hcno=
080D6FBF2BB468F9007657F26D60013E
[3] 姚先鋒. 如何用Excel讀取二代身份證的相關信息[C]//.2013年度江蘇省測繪學會年會論文集.,2013:123-124.
作者:歐剃
編輯:Owl、窗敲雨
本文來自果殼,未經授權不得轉載.
如有需要請聯繫[email protected]
點個“小愛心”吧