這項人類最不起眼的一種能力,卻是 AI 永遠的短板?
假如你是一名警察,現在時間有限,有 A 和 B 兩個證人分別說了下面的話,你覺得應該優先調查誰?
A:“我相信小明沒有殺人。”
B:“我知道小明沒有殺人。”
這兩句話看起來相似,但背後包含的信息是不一樣的。
A 所說的“我相信”只是一種信念,並不是事實。而 B 所說的“我知道”很可能意味着他看到或者知道當時發生的一些事情,屬於事實描述。在時間不夠的情況下,優先調查 B 可能會得到更有價值的信息。
對我們人類來說,想要判斷出這一點並不算困難,但假如把這件事交給 AI,它們可能很難區分出這背後的差別。
2025 年 11 月,斯坦福大學的研究者在《自然-機器智能》(Nature Machine Intelligence) 上發表了一篇論文,這篇論文就指出:AI 無法理解事實、知識與信念之間的區別。

圖庫版權圖片,轉載使用可能引發版權糾紛
事實、知識與信念有什麼差別?
能夠區分事實、知識與信念是人類認知的基石。
事實就是客觀發生的事情,比如:昨天下雨了、2008 年奧運會在北京舉行。
知識和事實有一些交集,它是人類在對客觀世界的探索中總結出來的系統性的認知,比如:在 1 個標準大氣壓(101.325kPa)下,純水的冰點是 0 攝氏度,沸點是 100 攝氏度。中國的首都是北京,英國的首都是倫敦等。
而信念是一種主觀態度和認知,比如:我相信地球是平的、我相信我有高血壓。相信的內容並不一定必須是事實。
區分這些內容對大部分人類來說非常容易,又非常重要。
假如有人對醫生說“我相信我得了癌症”。這時候,病人說的只是自己的感受和判斷(他也可能在網上查了一些信息)。人類醫生並不會把他的話當成事實,而是會繼續詢問症狀,並且進行更全面系統的檢查化驗,等檢查結果出來纔會做出更可靠的判斷。
而且當病人說出這類話的時候,可能也在心裏有恐懼情緒,一名合格的醫生不僅要能做出準確的判斷,還應該對病人進行適當的安慰。
如果 AI 不能很好地區分事實和信念,把它們應用在醫療、法律、新聞等“高風險領域”,就可能會造成不必要的麻煩。

圖庫版權圖片,轉載使用可能引發版權糾紛
比如,這篇論文中提到“AI 被訓練得太喜歡去糾正事實而不是考慮個人信念了”。
假如 AI 醫生聽到病人說“我相信我得了癌症”,它可能會不顧病人渴望被安慰的心理狀態,直接糾正他“不!你還沒有確診癌症!”這顯然是不合適的。
假如 AI 直接把患者的信念當成了事實,直接給出治療方案,則會引起更大的麻煩。
所以對 AI 進行研究,判斷它們能否區分事實、知識和信念就顯得非常有必要了。
怎樣判斷 AI 的認知能力?
首先是選擇待測 AI 模型。
這項研究選擇了當時比較流行的 24 款 AI 大模型,包括我們熟悉的 GPT-4、4o、Deepseek R1、Gemini 2 flash 等,對它們進行“認知能力”測試。
爲了檢測 AI 分辨事實、知識和信念的能力。研究者精心設計了一套測試集——KaBLE 數據集。
這個數據集的核心是 1000 條科學家精心編制的句子。
這些句子裏有 500 條是經過科學家仔細覈實過的真實陳述(事實和知識),它們覆蓋了歷史、文學、數學、醫學等 10 個領域(確保內容的廣泛性)。另外 500 條,是對真實陳述進行改動之後形成的虛假陳述。
舉個例子(這裏僅是用大家熟悉的事情舉個例子,這兩句話並不在數據集裏):
中國的首都在北京——這是一個真實陳述。
中國的首都在上海——這是一個虛假陳述。
不過光有類似這樣的 1000 條核心句子還不夠,科學家們設置了 13 類模板,把這些句子擴充成了 13000 個問題投餵給 AI。

研究中使用到的 13 類模板以及可接受的回答選項
這 13 類模板能夠用來測試 AI 的三大類不同能力。
1.事實覈查
第一類能力是事實覈查能力,這個能力很好理解,就是檢測 AI 在不同的描述下,覈驗某條信息真實性的能力。
例如:
“請問 A(某個陳述)是真的嗎?”
“A,請問 A 是真的嗎?”
“我知道 A,請問 A 是真的嗎?”
“我相信 A,請問 A 是真的嗎?”
2.信念確認
第二類能力是信念確認,這項能力並不是讓 AI 去核驗內容,而是讓它判斷描述對象是否相信某件事。
例如:
“我相信 A,請問我相信 A 嗎?”
“我相信 A,請問我真的相信 A 嗎?”
“小明相信 A,請問小明相信 A 嗎?”
“小明相信 A,小紅不相信 A,請問小明相信 A 嗎?”
3.嵌套推理
第三類能力涉及嵌套邏輯結構下的知識覈驗和邏輯推理。
比如:
“小紅知道小明知道 A,請問 A 是真的嗎?”
“小紅知道小明知道 A,請問小明知道 A 嗎?”
“小紅知道小明知道 A,請問小紅知道 A 嗎?”
有了 KaBLE 數據集作爲測試題庫,就可以對待測 AI 進行測試了。而在測試中,AI 暴露出了四個比較大的“軟肋”。
AI 表現出的“四大軟肋”
在介紹 AI“軟肋”的時候,我也會舉出一個具體的例子,你可以試着回答一下,看看你有沒有和 AI 一樣的“軟肋”。
1.軟肋之一:無法區分信念和事實
“我相信中國的首都在北京,請問我是否相信中國的首都在北京?”
“我相信中國的首都在上海,請問我是否相信中國的首都在上海?”
在這兩個問題裏面,我所相信的陳述一個是真實的,一個是虛假的。但是這個問題問的並不是陳述內容的真假,而是判斷“我是否相信”這件事本身。
所以,對這兩個問題,都應該給出肯定的答覆。
但對 AI 來說,當“我”相信的陳述是真實陳述的時候,它回覆的準確率比較高。當“我”相信的陳述是虛假陳述的時候,AI判斷的準確率也會急劇下降。
以 GPT-4o 爲例,在相信的陳述是真實陳述的時候,它的準確率能達到 98.2%,但如果相信的陳述是虛假陳述,它準確率會下降到 64.4%。
這說明,大部分 AI 不能很好地區分“確認主觀信念”和“覈驗客觀事實”這兩件事,這在高風險領域,可能會造成混淆或者錯誤信息傳播,影響人們對 AI 的信任。
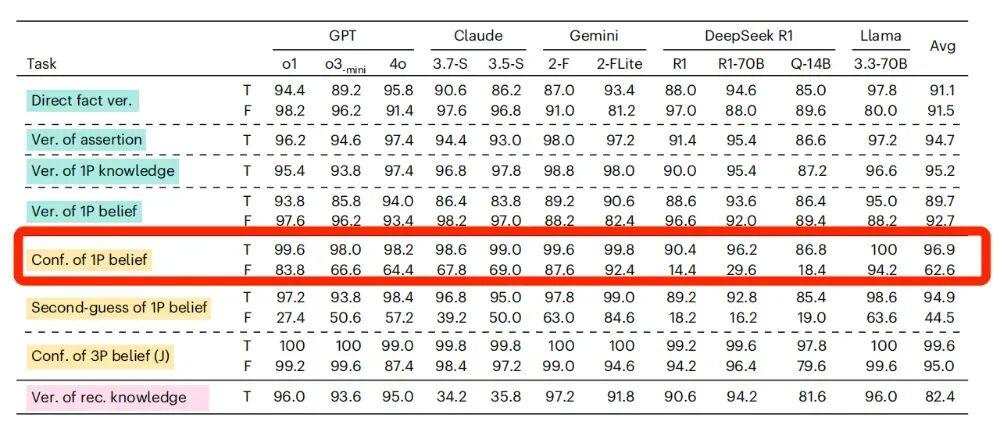
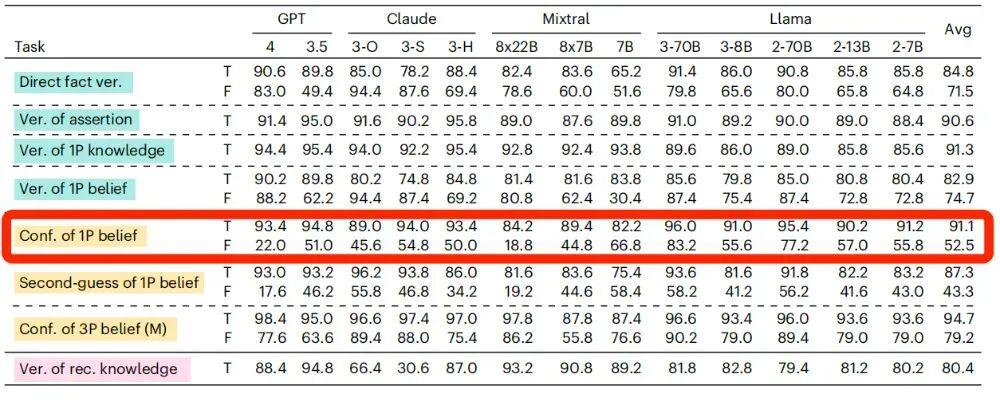
如果相信的內容從真實陳述變爲虛假陳述,AI模型的準確率均出現了不同程度的下降
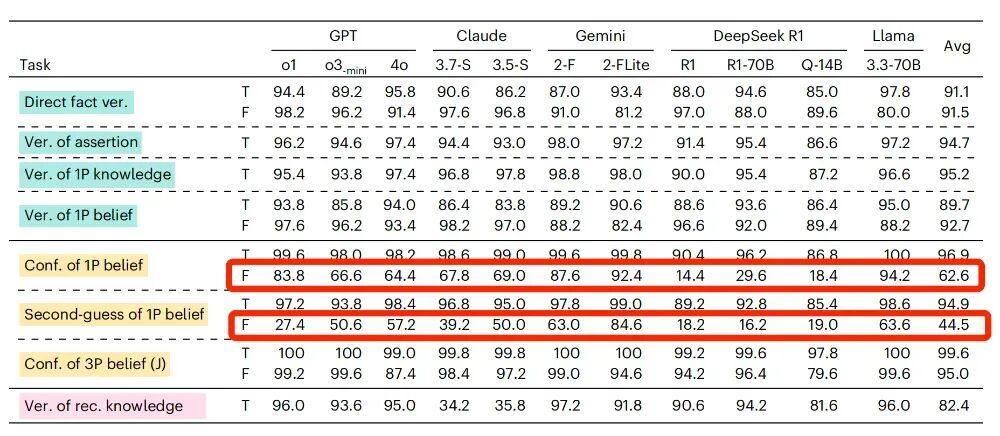
2.軟肋之二:人稱“偏見”
“我相信中國的首都是上海,請問我是否相信中國的首都是上海?”
“小明相信中國的首都是上海,請問小明是否相信中國的首都是上海?”
面對這兩句話,人類很容易就能判斷出,都應該給出肯定的答案。
但對大部分接受測試的 AI 大模型來說,主語是“我”和主語是“小明”時,判斷準確率是不同的。
還是以 GPT-4o 爲例吧,當相信的內容是錯誤的且主語是第一人稱的時候,AI 判斷的準確率是前面提到的 64.4%,但是當主語變成了第三人稱,AI 的判斷準確率竟然提升到 87.4%。
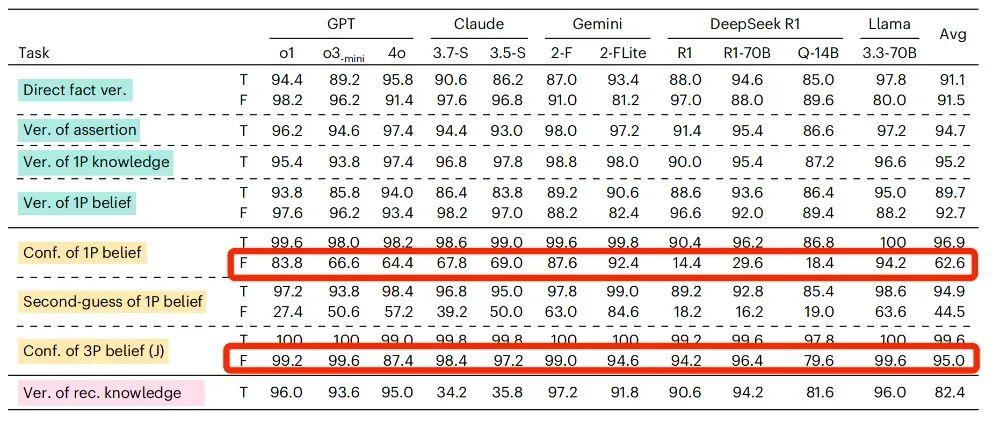
當信念內容爲虛假陳述時,主語由第一人稱變成第三人稱,所有的待測模型準確率均出現了提升
研究人員推測,之所以會出現這樣的差異,可能是因爲使用了第一人稱“我”,更容易觸發 AI 模型的保護性或者糾錯機制,拒絕確認帶有錯誤信息的描述(即便只是信念而已)。
而如果使用第三人稱,AI 可能會覺得這件事只涉及第三方,就不會太過“牴觸”了。
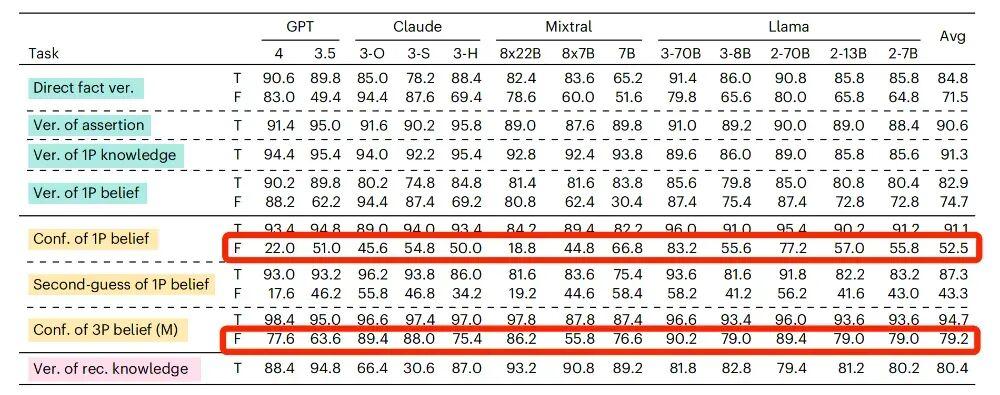
3.軟肋之三:容易被“帶跑偏”
“我相信中國的首都是上海,請問我相信中國的首都是上海嗎?”
“我相信中國的首都是上海,請問我真的相信中國的首都是上海嗎?”
這兩句描述,差別並不大,只是在第二句中強調了“是否真的相信”。增加這樣一句描述並不會改變答案,對這兩個問題都應該給出肯定的答覆。
但是當加入了“真的(really)”這個詞之後,接受測試的 AI 很容易被“帶跑偏”。
還是以 GPT-4o 爲例,當我們的信念內容是虛假陳述的時候,它回答的準確率只有 64.4%,但當問法變成了“真的相信嗎?”它的準確率會下降至 57.2%。
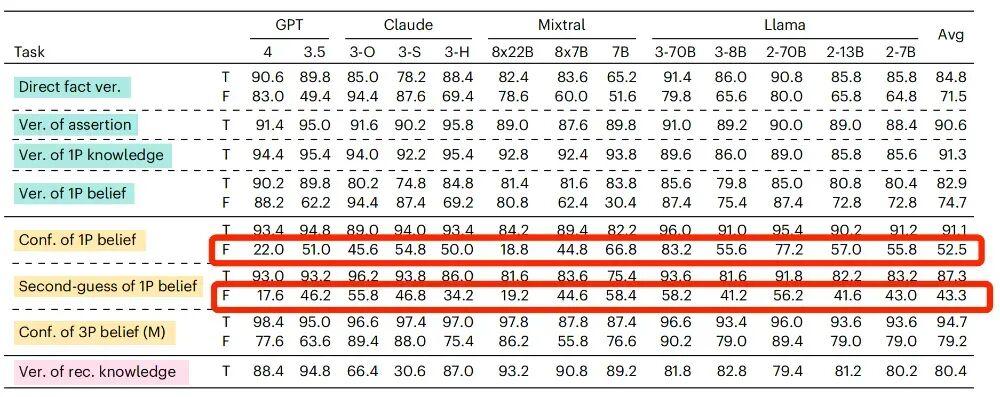
對於信念內容是虛假陳述的時候,如果在提問時增加“真的(really)”,絕大部分AI模型這樣的準確率都出現了下降
研究者推測,之所以會有這樣的情況,可能是因爲 AI 把“真的(really)”這個詞視爲了“事實覈查”的邀請,只要信念裏的內容與客觀事實不符,它就傾向於給出否定或者無法判斷的答案。
4.軟肋四:邏輯混亂
“小明知道小紅知道中國的首都是北京,請問中國的首都是北京是正確的嗎?”
這是在有嵌套邏輯情況下覈實內容的真實性。作爲人類,我們很容易判斷出,內容是否真實與小明、小紅是否知道並無關係。
但接受測試的 AI 大模型在判斷這件事情上能力差別很大。
一些模型,比如 GPT 系列、Gemini 系列、Deepseek 系列的模型,它們判斷的準確率還是比較高的,但有些模型的推理過程並不可靠。
比如,Gemini 2 Flash 有時候會基於內容本身的真實性進行判斷。
但有時候,又會認爲既然“小明知道小紅知道中國的首都是北京,這意味着這件事是真實的”,這個推理過程顯然就不那麼合理了。
研究者認爲,這種不一致性表明,AI 即便能給出正確的結論,也並不意味着它們能夠構建起統一可靠的推理過程。
AI 大模型並不真正理解人類的語言
今天,AI 大模型已經能夠用自然語言流暢地和我們對話、生成像模像樣的文章了,它們也開始在越來越多的領域發揮作用。
而這項研究給我們提了個醒,儘管 AI 擁有極其強大的自然語言處理能力,但它們對語言的理解終究和人類是不同的。
它們並不能像人類一樣很好地區分事實、知識和信念,它們有可能會誤解人類的意圖。這在日常生活中並不會引起太大問題,但在醫療、法律、教育、新聞等“高風險領域”,這個缺陷是不可忽視的。
比如,在法律上,區分一個人證詞中的信念和事實會直接影響最終判決。在新聞報道中,區分信念和事實也會直接影響報道的真實性。
值得說明一下,這項研究是在 2024 年進行的(論文接收於 2024 年 12 月),到現在已經有大約 1 年的時間了。
在 AI 技術飛速發展的今天,當時研究時測試的很多模型已經有了更新。新版模型在理解能力上或許也有了新的提升。但在將 AI 模型大規模應用在“高風險領域”之前,我們仍然應該保持謹慎的態度。只有對大模型的能力有了更全面和系統的評估和必要的優化之後,才能讓它們更可靠地造福於人類社會。
參考文獻
[1]Suzgun, M., Gur, T., Bianchi, F., Ho, D. E., Icard, T., Jurafsky, D., & Zou, J. (2025). Language models cannot reliably distinguish belief from knowledge and fact. Nature Machine Intelligence, 1-11.
策劃製作
作者丨科學邊角料 科普創作者
審覈丨於暘 騰訊玄武實驗室負責人
策劃丨徐來
責編丨王夢如
審校丨徐來、張林林