“爲了全人類,提交你最難的問題”
跑分都滿分則跑分無意義。
從AI剛剛面世,人們就執着於用各種各樣的題庫來測試AI到底有多聰明,不管是ChatGPT、Gemini、Grok,還是DeepSeek、Kimi、文心一言,它們發佈的同時,幾乎都會附上一個跑分成績。
而事到如今,市面上流行的題庫都快被AI做穿了,每一代新模型都要“霸榜碾壓”,“滿分橫掃”,在MMLU這樣的熱門基準測試上,大部分模型的準確率已經超過 90%——換句話說,AI的聰明程度,人已經快評估不出來了。

好懷念那些過去的好日子,AI只要顯得像個人就能通過測試(現在圖靈測試已經好久沒人提了)|x @PhysInHistory
“人工智能能力的評估基於基準測試,然而基準測試正在迅速飽和,失去了作爲衡量工具的效用……”人類最後的考試網站首頁寫道,“在MMLU和GPQA這樣的測試中表現良好,已不再是取得進步的有力信號,因爲前沿模型在這些基準測試中的表現已經達到或超過了人類水平。”
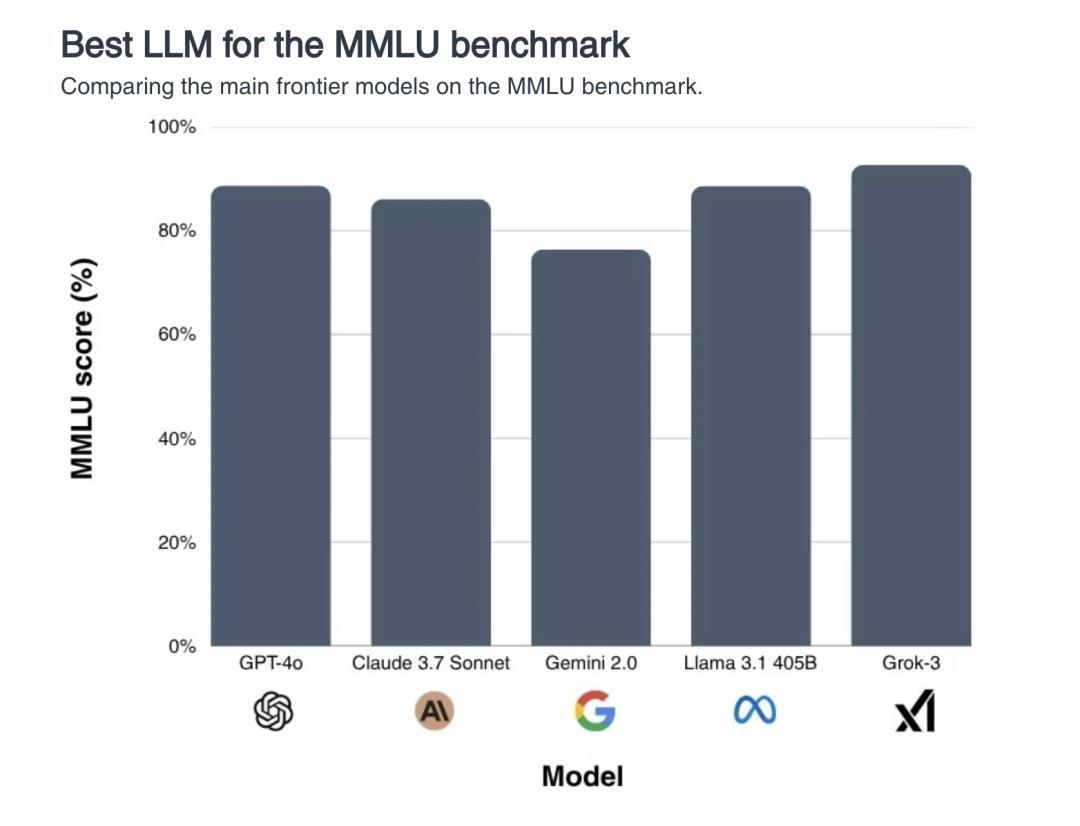
在MMLU基準測試上,前沿大模型的得分不相上下。弔詭的是,如果AI已經比人類更聰明瞭,那我們是否有足夠的智慧去認知這一點?|bracai.eu
爲了搞清楚高速進化的AI到底發展到哪一步了,也爲了給它們排個名次,拉開差距,我們需要上點更難的題了。
作爲目前人類最高智慧和最先進文明成果的代表,“人類最後的考試”(Humanity''s Last Exam,以下簡稱HLE)就在這個背景下誕生了。
人類智識最後的堡壘,文科也在裏面
“人類最後的考試”是一個基準測試,由Center for AI Safety和Scale AI聯合創建,它的測試內容幾經調整,最終在2025年3月4日確定爲一套包含了2500個前沿學術難題的題庫。
這些題分佈在100多個不同的學科領域,可以粗略分爲以下幾大類:
數學(Mathematics):大量高難度數學題,包括高等代數、拓撲、範疇論、概率、圖論、數論等,強調推理深度。
自然科學(Natural Sciences):物理、化學、生物、生態學、醫學等。
計算機科學與人工智能(Computer Science & AI):算法、圖論、馬爾科夫鏈、程序推理等。
工程學(Engineering):複雜系統和應用性技術問題。
人文學科與社會科學(Humanities & Social Sciences):語言學、歷史學、經濟學、宗教研究、人類學、心理學、教育學、古典學、文化研究,應有盡有。
其他:冷門知識或小衆學科(古文字、特定地方的風俗考證之類)。
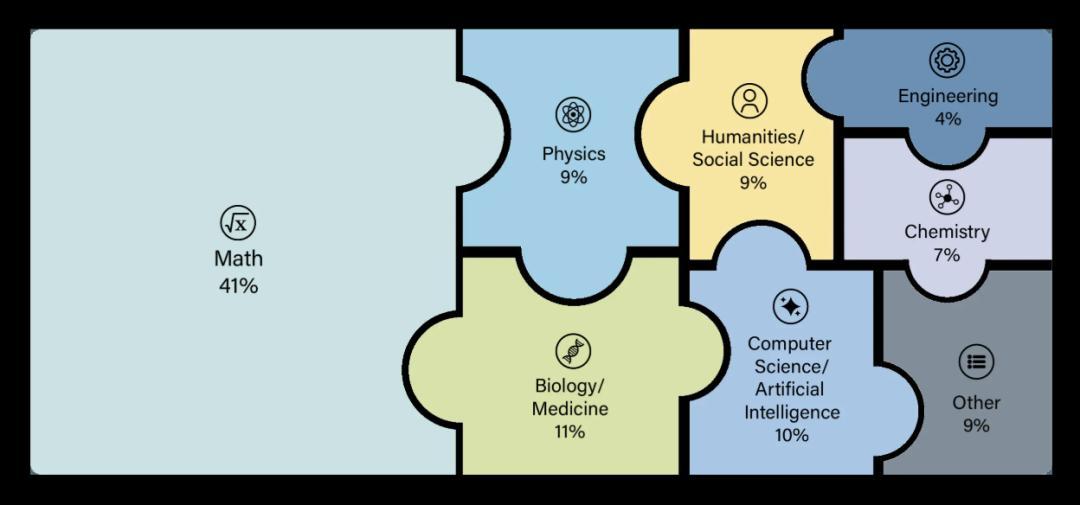
具體的題庫分佈,其中數學題佔了41%,人文領域題佔了18%(可惡啊,輸掉了)|HLE
HLE最讓人印象深刻的是它的多模態,這些問題不只是基於文本,還包括圖表、古文字、圖像、公式,這意味着AI想要回答問題,就得先讀懂問題。
HLE的官網上公開了其中一部分問題。
比如下面這道古典學領域的題,要求AI把一段在墓碑上發現的羅馬銘文翻譯成帕米拉亞蘭語(還給了音譯,多貼心啊)。

問題由牛津大學墨頓學院博士Henry Tang提交|HLE
還有這道考察AI對亂成一團的古希臘男女關係的瞭解程度的民俗小知識題:在希臘神話中,伊阿宋的曾姥爺是誰?
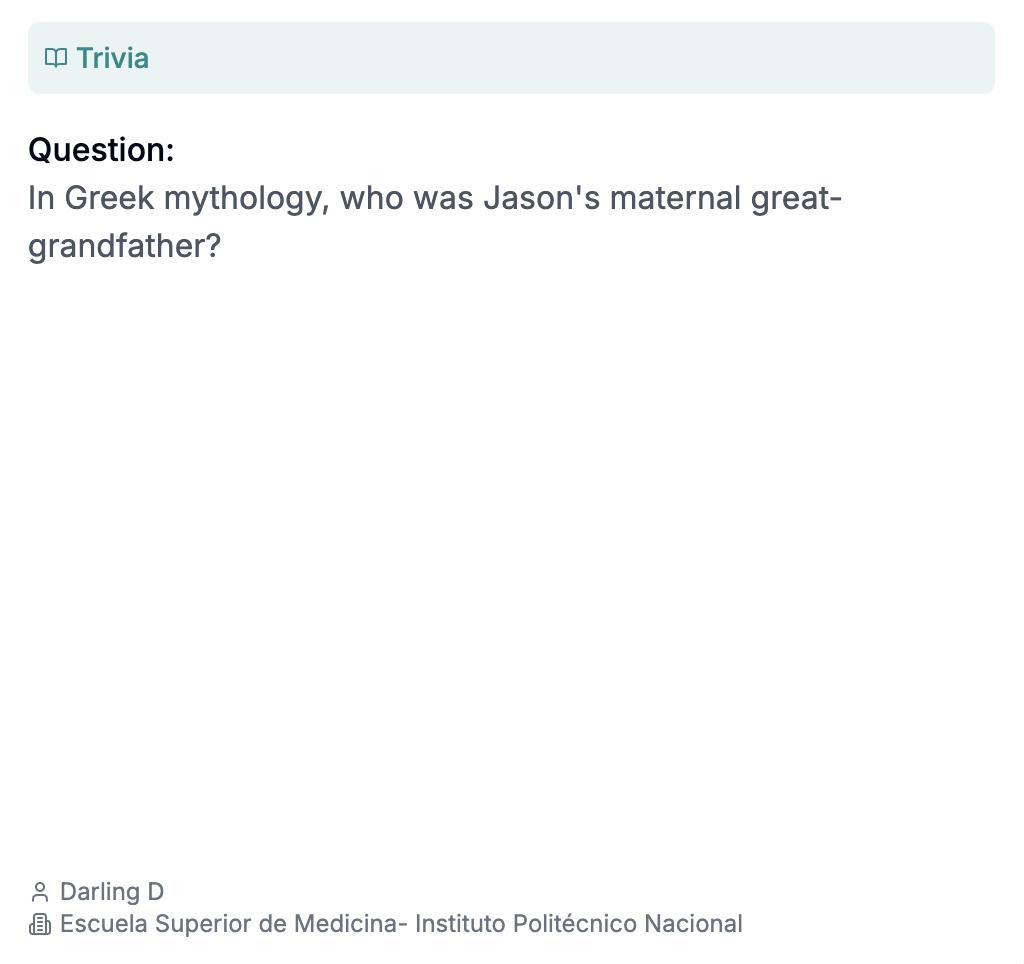
由墨西哥國立理工學院醫學部的Darling D提交(我沒有找到這個人,不知道爲什麼醫學院的人會出這種題)|HLE
這道讀起來像GRE考試題一樣,每個詞都似是而非,讀着後面忘着前面的生物題,大概是問蜂鳥的籽骨支撐着多少對肌腱,明確要求用數字來回答。
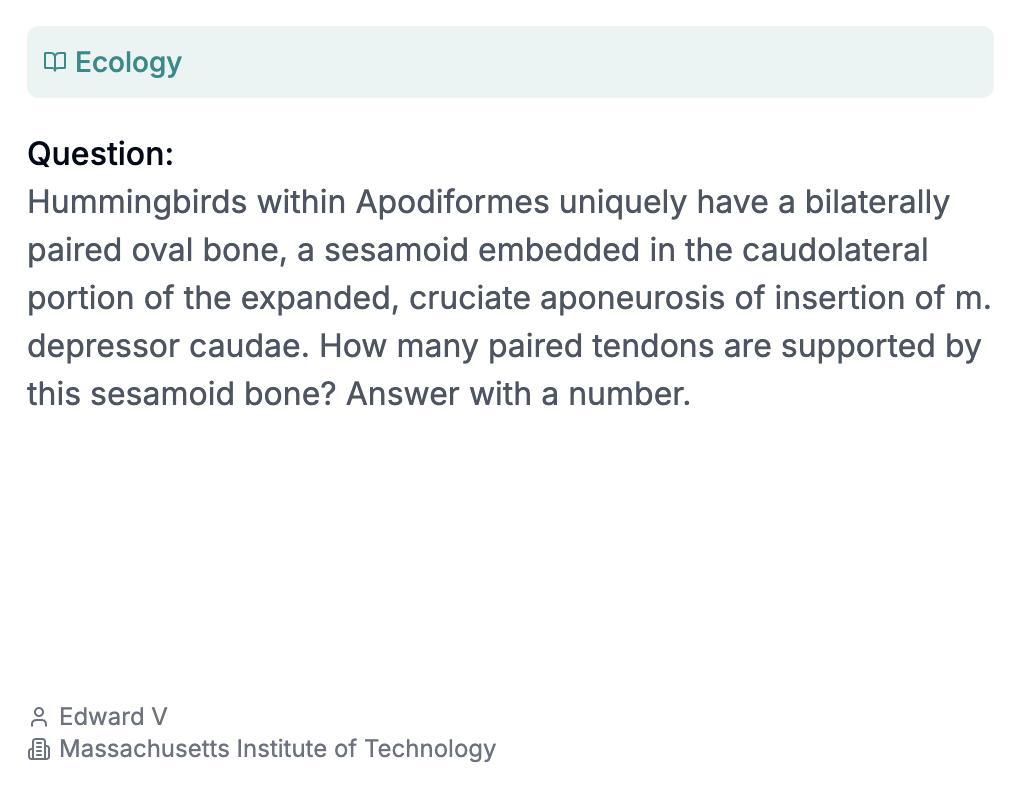
由麻省理工大學計算機系的博士Edward Vendrow提交,真是一位很博學又很會針對AI的學者,至於爲什麼這道題針對了AI我們等下講|HLE
還有這道考察圖論+馬爾可夫鏈的題:

由倫敦瑪麗女王大學計算機系講師Dr. Marc Roth提交|HLE
如果你還想做更多的題,或者對題庫好奇,再或者想憑一人之力和AI決一高下,可以上HLE官網查看題庫。
雖然這些問題已經公開發布,供開發者測試大模型用,但是HLE稱,“爲了應對訓練數據污染和基準測試黑客攻擊問題”,他們也保留了一個private set,用於定期測量模型與公共數據集的過擬合情況,不對外公佈,而這一部分纔是真正用於AI模型排行榜和最終評分的核心數據。
題庫裏的題主要有兩種形式,選擇題和簡答題。
選擇題需要從五個以上的選項中進行選擇(題庫中24%的題目是多選題),而簡答題需要模型輸出和答案完全一致的字符串,不能語義模糊、不能不準確。在題庫中,還有約14%的題目要求同時理解文字和圖像。
可以說是全選C戰術和誰字多誰得分戰術都沒用了。
“爲了全人類,提交你最難的問題”
不得不說“人類最後的考試”這個名字起得真的很好,要不是這厲害中透着中二氣息的名字,我可能永遠也不會好奇一個冷冰冰的大模型的基準測試到底在考什麼。
但HLE的發起人丹·亨德里克斯(Dan Hendrycks)一開始想的名字更厲害,叫“人類最後一戰”(Humanity’s Last Stand),後來大家都覺得這個名字過分抓馬,勸他放棄了。

丹·亨德里克斯,他還寫了一篇文章叫《災難性人工智能風險概述》,也還蠻有意思|The New York Times
丹·亨德里克斯也是一個神人。
25歲的時候,他聯合編寫了現在最熱門的AI大模型基準測試MMLU,截至2024年7月,MMLU下載量已超過1億次。30歲的時候,他發現目前AI的能力已經溢出了基準測試,MMLU已經不好使了,於是他決定做個新的測試(他還在一次採訪中表示,他做HLE是因爲馬斯克覺得現在的基準測試都太簡單了)。
目前,亨德里克斯在馬斯克的人工智能公司xAI擔任安全顧問,他同時也是Scale AI的顧問,爲避免潛在的利益衝突,他每月只象徵性地領一美元薪水,而且不持有任何公司股權。
再說回HLE。
HLE計劃發起初期,也就是2024年9月,亨德里克斯公開發布文章,號召全世界的學者“爲人類最後的考試交出你最難的問題”(這個說法相當有毒,因爲人家並不知道HLE就是題庫的名字,只看題目彷彿事關人類存亡)。
“未來的人工智能系統最終將超越所有能夠創建的靜態基準,因此突破基準和評估的界限至關重要。爲了追蹤人工智能系統距離專家級能力的差距,我們正在組建史上規模最大、範圍最廣的專家聯盟。”在文章中他寫道,“如果你覺得某個問題能被AI解答會讓你印象深刻,歡迎你提交。”
爲了全人類,提交你最難的問題|scale.com
交問題也不是白交的,亨德里克斯宣佈,所出題目評分最高的研究者,可以瓜分50萬美元的獎金——排名前50位的問題,每題可獲得5000美元獎金,之後的500個問題,每題可獲得500美元獎金。
關於問題本身,HLE則提出了更加嚴格的要求。
首先,問題的答案需要在網上搜不出來。其次,問題需要是原創的新問題,不能在以前的考試裏出現過。再次,問題需要有明確的答案,而且答案應被相關領域的其他專家廣泛接受,且不包含個人偏好、歧義或主觀性。最後,問題應該有碩士級別以上難度,因爲“根據經驗,如果隨機選擇的本科生能夠理解題目內容,那麼對大模型來說這個問題可能過於簡單”。
每道題提交時都必須包含題目本身、題目答案(精確的回答,或者選擇題的正確選項)、詳細的解題推理、所屬學科,以及貢獻者的姓名和機構信息。
對所有提交的問題,HLE會進行兩步篩選:先把問題餵給最先進的AI去解答,如果AI無法回答,或者在多選題裏的得分比隨機猜的還差,那問題就會被交給人工審閱者,由他們審閱和驗證答案。
在The New York Times的一次採訪中,加州大學伯克利分校理論粒子物理學博士後研究員Kevin Zhou表示,他提交了一些題目,其中三道題目被選中,而這些題目“都達到了研究生考試的上限”。
最終HLE收到了來自50多個國家、500多家研究機構和企業的1000多位學者的回覆,從中誕生了目前最難的AI基準測試HLE。
對AI來說,HLE難在哪?
費了這麼大功夫,HLE真的難住AI了嗎?
單看結果而言,是難住了。
目前爲止,主流前沿模型純文本模式下在HLE上的得分都還比較低,OpenAI最新的o3-mini(high)模型,準確率只有13%,而前陣子震撼美國的DeepSeek-R1的準確率也才9.4%。目前得分最高的是Grok4,正確率26.9%。
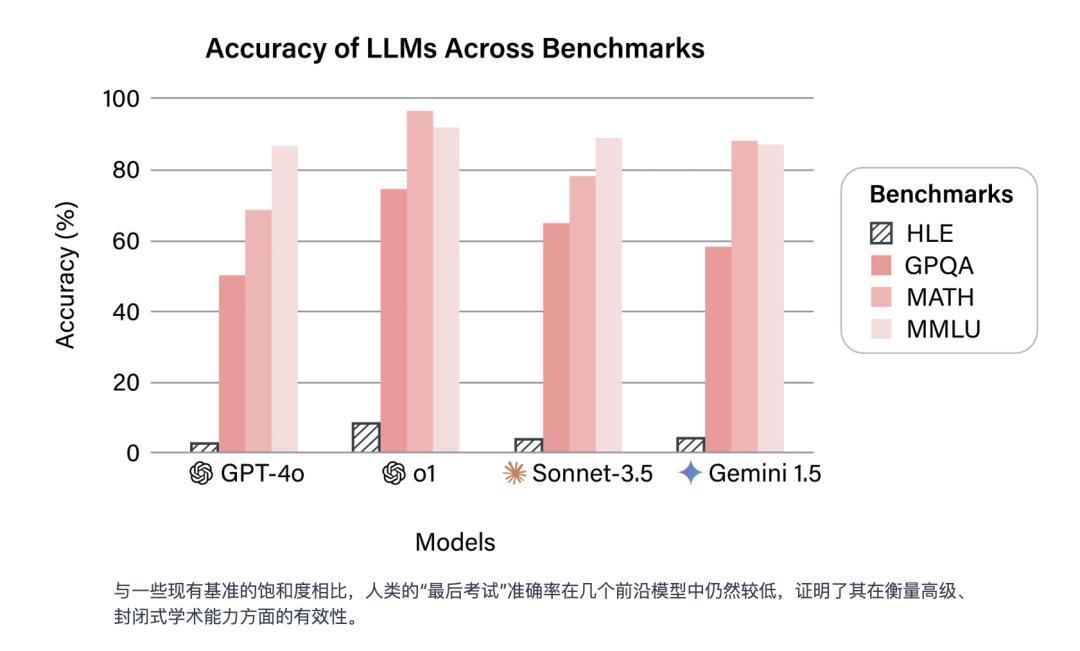
截止到今年一月論文發表時的數據,黑色柱形是HLE的準確率|HLE官網
這些題爲什麼這麼難?
有一個原因是它們需要一定的推理深度,而且沒法在網上找到答案,還有一個原因是問題已經經過了篩選,留下的全部是現有的前沿模型表現差的問題。
還有一個原因是在問題上給AI挖了坑。
比如上文提過的蜂鳥籽骨問題,看似簡單,但是有人測試了ChatGPT5和Gemini,它們都給出了一篇論文似的長篇大論,而忽略了問題的最後一句話,“Answer with a number”,請直接用數字回答。
因此,所有不是“2”的答案都被算作是錯的(儘管有些模型在長篇大論之後給出了正確答案),這可能是一個產品設計問題,而不是AI表現問題。

Threads@raystormfang
另外,有些問題連人類自己都還沒達成一致呢。
最後的考試,可能也撐不了多久
最後的考試賞金很誘人,概念很科幻,目的很崇高,但是它帶來的爭議已經開始浮現。
今年7月,專注人工智能應用的非營利組織FutureHouse發佈了一篇調查報告,稱HLE裏“化學生物領域的30%的答案可能是錯的”。
他們組建了一個化學生物領域的專家評審團,並且詳細研究了HLE題庫,最終得出結論,“29±3.7%(95%置信區間)的純文本化學和生物問題的答案與同行評審文獻中的證據直接衝突”。
比如這個問題:截至 2002 年,在地球物質總量中所佔比例最少的稀有氣體是哪一種(What was the rarest noble gas on Earth as a percentage of all terrestrial matter in 2002)?
你不知道,我不知道,AI也不知道,答案是Oganesson。

Oganesson,或者叫鿫,化學符號Og,原子序數118,是一種人工合成的放射性超重元素,位於元素週期表第七週期、稀有氣體族(0族)的末端。2002年,鿫在俄羅斯的一座核反應堆中首次被合成並存在了幾毫秒,迄今爲止,只有五個Oganesson原子被合成。而且它更可能是固體或液體,而不是氣體,還有一些學者認爲它不是惰性氣體,因爲它的化學性質並不穩定。此外,還有多篇論文(包括2002年的論文)列出了地球上稀有氣體的比例,而鿫沒被算進去——總而言之,鿫可能不是氣體,也可能不是惰性氣體,而且大多數同行評議的論文覺得它也不是地球物質。
而AI答不答得出腦筋急轉彎問題又能證明什麼?
還有另外一個迷思,對大多數前沿模型來說,HLE都太難了。大家得分都很低,和大家得分都很高的狀況是一樣的,還是沒拉開區分度,也沒想明白得分高的模型好在哪。而且HLE覆蓋的是學術考試可測內容——它專注於已知的學術題目和閉合答案,對開放式創造力、生成類問題或非常新穎的研究課題的思考仍然難以評估。
雖然千辛萬苦花大價錢出了這麼一套題,看來也要很快被打穿了。
HLE自己預測,雖然目前的AI在HLE上的準確率非常低,但到2025年底,模型在HLE上的準確率就有望超過50%。事實上,還沒到年底,Grok4在使用工具的情況下(比如代碼解釋器)正確率已經升到了41.0%。
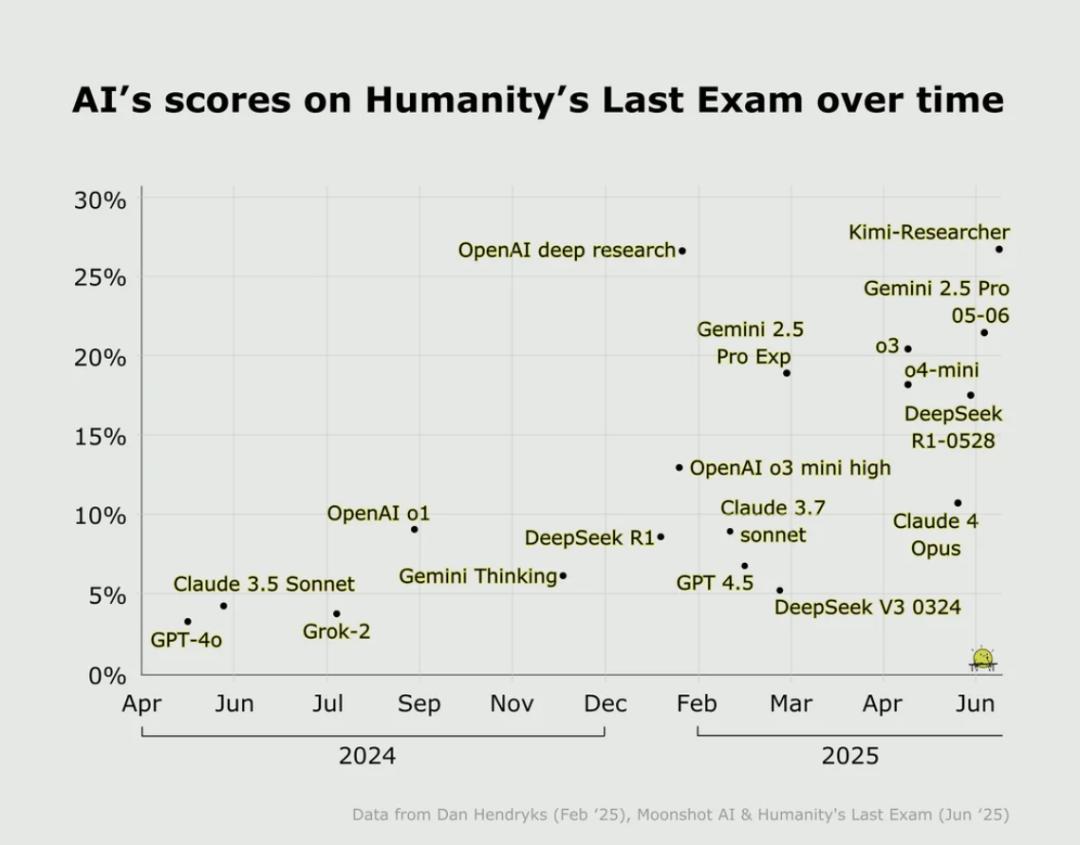
各個AI模型在2024年和2025年的HLE得分,按照這個進步速度,HLE也很快被打穿了|Reddit
亨德里克斯說,HLE或許是我們需要對模型進行的最後一次學術考試,但它遠非人工智能的最後一個基準。等HLE又被超越,我們還有什麼題出給AI呢?
作者:翻翻
編輯:odette
封面圖來源:Scale AI / CAIS
本文來自果殼,未經授權不得轉載.
如有需要請聯繫[email protected]