給DNA裝“活字”,我國自主研發“畢昇一號”實現存儲技術跨越
在大數據時代,我們每天都在製造海量的信息,包括髮送的消息、拍攝的照片、社交媒體上的視頻以及科研實驗的數據等。根據調研機構IDC的預測,到2028年,全球每年產生的數據總量將超過380 ZB(1ZB約等於1萬億GB),相當於3800億塊家用1 TB的移動硬盤所能存儲的內容。面對如此龐大的數據體量,我們目前使用的存儲媒介,例如磁帶、光盤和硬盤,正變得越來越難以滿足需求。這些設備不僅容量有限,能耗高,而且壽命較短,導致大量數據都無法得到長期、可靠的保存。
爲了應對這一挑戰,科學家們開始探索新的存儲方式,他們把目光投向了DNA——這種存在於生物體內的分子,能夠穩定地傳遞遺傳信息長達數百萬年。更重要的是,DNA天然具有極高的存儲密度和極低的能耗,這使其成爲實現大規模、長期存儲的潛在理想載體。
近期,國家生物信息中心應用發展部陳非研究團隊與中國科學院計算技術研究所處理器全國重點實驗室譚光明、卜東波團隊、中科計算技術西部研究院段勃團隊合作,設計出了一套全新的DNA存儲系統,並將其命名爲“畢昇一號”,以致敬中國古代活字印刷術的發明人畢昇。畢昇一號以“DNA活字”爲核心,將數字信息“打印”到DNA之中,大幅降低了DNA存儲的成本,爲DNA存儲的實用化帶來了新的可能。
DNA存儲的原理與優勢
要理解畢昇一號的創新之處,我們首先需要了解DNA存儲本身的原理與優勢。
DNA,學名脫氧核糖核酸,是生命體中用於儲存遺傳信息的分子。它的結構類似一條長鏈,其中包含四種鹼基:A(腺嘌呤)、G(鳥嘌呤)、C(胞嘧啶)和T(胸腺嘧啶)。這些鹼基通過特定的方式配對排列,記錄着生命體從外貌到功能的全部遺傳信息。下圖展示了這四種鹼基的配對方式:A總是和T配對,C總是和G配對,它們通過氫鍵連接,構成了DNA的基本單元。
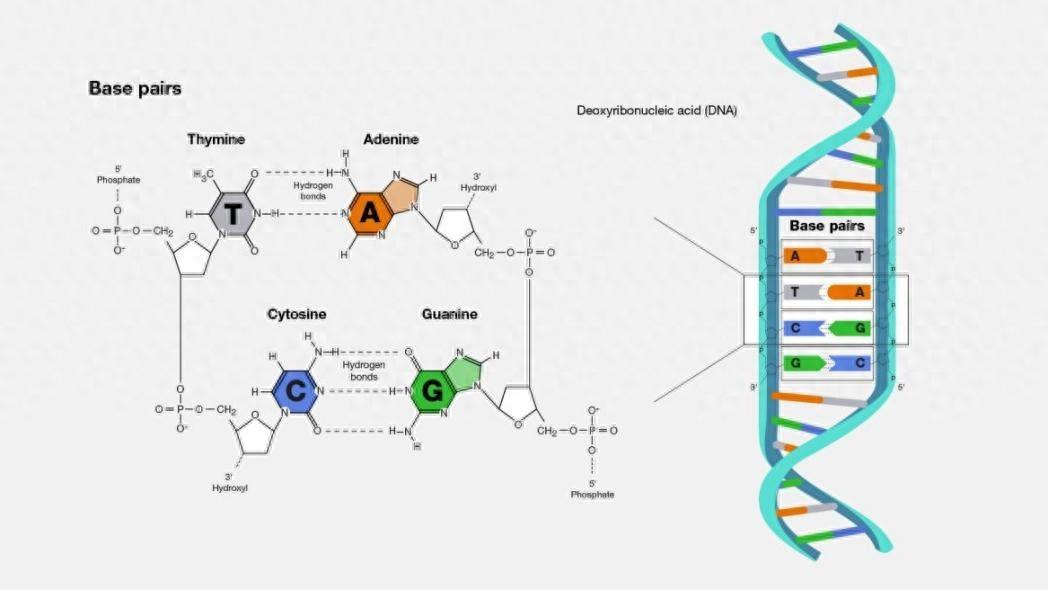
DNA的基本組成結構及四種鹼基配對方式
(圖片來源:維基百科)
在計算機中,各種形式的數據本質上都是以“0”和“1”組成的二進制串的形式存儲的。DNA存儲的基本原理,就是將這些二進制信息轉換爲特定的鹼基序列。例如,可以設定A對應“00”,G對應“01”,C對應“10”,T對應“11”。這樣一來,任何文本、圖片或視頻都能被編碼爲一串DNA序列;通過人工合成這些序列,信息就被寫入了DNA分子中。當需要讀取數據時,再用DNA測序技術讀取鹼基的排列順序,反向解碼回二進制,就能還原出原始數據。
與傳統的存儲設備相比,DNA存儲展現出多種顯著優勢。首先是極高的數據密度。比如,人類基因組包含超過30億個鹼基對,但其重量僅爲3皮克(1皮克等於一萬億分之一克)。其次,DNA具有驚人的穩定性。在自然條件下,如果儲存得當,它可以保存數萬年不被破壞。科學家就曾成功從數萬年前的猛獁象遺骸中提取出可讀取的DNA序列,這一能力遠遠超過目前存儲設備幾十年的壽命。最後,DNA不依賴電力維持,不像傳統的硬盤或服務器需要定期維護和持續供電,適用於保存長期數據。
近年來,DNA的測序和合成技術都取得了巨大的進展,爲DNA存儲的可行性奠定了堅實的基礎。在這樣的背景下,科學家們開始嘗試尋找更加高效和低成本的存儲方式,讓這一技術能夠真正應用於現實。基於這一理念開發的“畢昇一號”系統,正是DNA存儲向實用化邁出的關鍵一步。
從古老的活字印刷術到現代的“DNA活字”存儲術
活字印刷術是中國古代四大發明之一。在此之前,書籍的複製主要依靠雕版印刷,也就是爲每一頁內容單獨雕刻一塊書版。雕版印刷刻出一版後就可以印出無數份,但這種方法制作成本高、效率低、難以靈活調整內容。直到北宋年間,中國發明家畢昇發明了活字印刷術,將雕版拆分爲一個個可以重複使用的字塊,在印刷時按需組合,用完後還可以拆卸保存,大大提升了排版效率。
DNA存儲的發展也正在經歷着類似的演變。現有的DNA存儲技術大多類似雕版印刷,需要爲每個文件從頭開始進行昂貴且耗時的一次性DNA合成。爲了解決這一問題,研究團隊從活字印刷術中獲得靈感,創新性地提出了DNA活字的概念。他們設計出一套可以預製和複用的DNA片段,使DNA存儲從“一次性合成”轉變爲“編碼組裝”,大幅降低了DNA合成和存儲成本。
DNA活字是一種預先合成好的短鏈DNA片段,每條片段中間含有20個用於存儲信息的鹼基對,兩側則帶有專門設計的黏性末端(類似字塊的“接口”)以用於連接。這種設計讓每個DNA活字可以表示一個信息單元,也可以像字塊一樣自由組合、順序拼接,最終存儲一段完整的信息。
下圖展示了五個DNA活字的結構示例,它們共同編碼了莎士比亞的《十四行詩》中的單詞“white”。每個DNA活字代表一個字母,而它們的黏性末端則確保這些字母按照正確順序一一連接,最終拼出的長鏈就像印好的詩句一樣,完整存儲了目標信息。
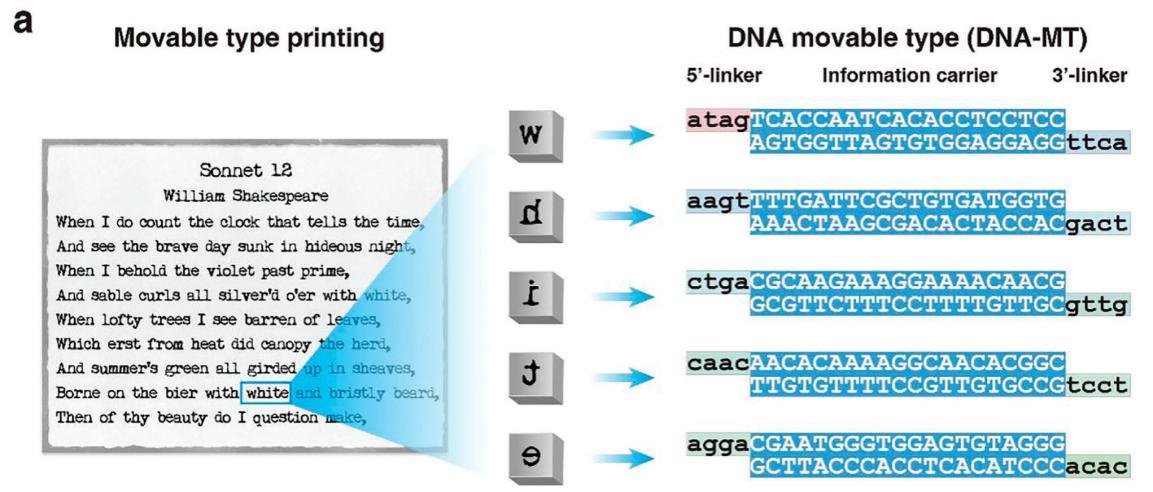
DNA活字(DNA-MT)
(圖片來源:參考文獻[1])
畢昇一號:DNA存儲的活字打印機
爲了將DNA活字這一理念真正變成現實,實現DNA存儲的自動化,研究人員設計並搭建了DNA活字噴墨打印機——畢昇一號。這個系統結合了DNA活字與現代噴墨打印技術,裝配有多個DNA墨盒,並內置攝像頭和圖像分析軟件,用於實時檢測噴墨過程中的故障,從而保證較高的成功率。

畢昇一號
(圖片來源:參考文獻[1])
畢昇一號實際工作流程分爲四個關鍵步驟:編碼、打印(組裝)、存儲和解碼。
第一步是編碼。系統首先將需要存儲的數據劃分爲若干較小的片段,並將其轉換爲二進制格式。隨後,這些二進制片段會被拆分爲更小的信息單元,根據每個信息單元的內容,自動匹配相應的DNA活字。
第二步是打印。這是畢昇一號的核心環節,它利用類似噴墨打印的技術,將DNA活字按需輸出。通過酶促反應,這些DNA活字能被準確構建成長鏈DNA。這個過程中無需重新合成任何鹼基序列,大幅提升了效率。
第三步是存儲。這些組裝完成的DNA並不會被直接冷凍保存,而是被進一步克隆到質粒中。質粒是一種天然存在於細菌體內的小型環狀DNA分子,常被用作實驗載體。研究人員將構建好的DNA片段插入到質粒中,再將其導入到大腸桿菌細胞之中。細胞在自然生長繁殖的同時,也會不斷複製所攜帶的DNA,從而實現穩定、低成本的生物存儲與數據拷貝。
最後一步是解碼。當需要提取數據時,只需對保存的DNA進行測序,識別其中包含的DNA活字序列,即可還原出原始的二進制內容,最終恢復出可讀取的文件。爲了提高系統的準確率,研究人員在每個片段中還設計了額外的校驗信息,用於檢測和修復可能的錯誤。
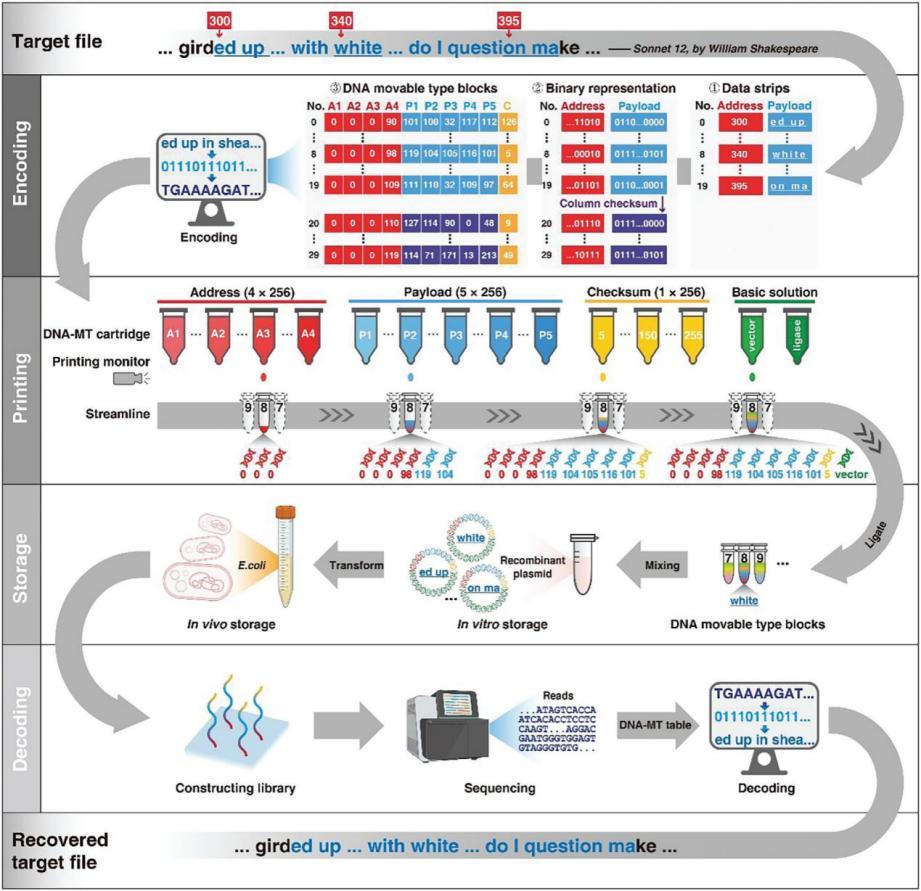
畢昇一號的工作流程
(圖片來源:參考文獻[1])
值得一提的是,畢昇一號所使用的DNA活字全部由人工預先合成並存儲在墨盒中。一旦合成完成,每個DNA活字可以反覆使用上萬次。這大幅降低了DNA存儲的成本,也提高了存儲效率。
結語
從雕版到活字,從紙張到DNA,人類記錄與儲存信息的方式正在經歷一場跨越千年的演變。在當今大數據時代,我們不再滿足於存儲容量的緩慢提升,而是開始思索:能否將數據存儲進DNA之中?
畢昇一號藉助DNA活字的創新形式,避免了反覆合成的高昂成本,在效率和成本上取得了新的突破,展現了DNA存儲技術的巨大潛力。隨着技術的進一步發展,或許在未來,我們的海量數據真的能被“寫入”DNA,以生命的方式實現跨越時空的保存。
參考文獻:
[1 ] Wang C, Wei D, Wei Z, et al. Cost‐Effective DNA Storage System with DNA Movable Type[J]. Advanced Science, 2025, 12(9): 2411354.
[2] A. Wright, Worldwide IDC Global DataSphere Forecast, 2024–2028: AI Everywhere, But Upsurge in Data Will Take Time, International Data Corporation, IDC Corporate 140 Kendrick Street Building B, Needham, MA 02494 2024.
[3] Van Der Valk T, Pečnerová P, Díez-del-Molino D, et al. Million-year-old DNA sheds light on the genomic history of mammoths[J]. Nature, 2021, 591(7849): 265-269.
出品:科普中國
作者:王琛(中國科學院計算技術研究所)
監製:中國科普博覽