AI怎樣模仿人類大腦的注意力機制?
5.16
知識分子
The Intellectual

圖源:Pixabay
撰文 | 張天蓉
● ● ●
最近,人們對AI談得最多的是deepseek(簡稱DS)。這匹來自中國本土的黑馬,闖入全球視野,一度擾亂美國股市,在 AI 領域掀起了一場軒然大波。
不過,正如DS創始人梁文鋒所言,DS的成功是因爲站在了巨人的肩上,這個巨人,可以有不同的理解,最靠近的當然是Meta的開源代碼(例如PyTorch和LLaMA)。說遠一些,這個巨人是多年來科學家們推動發展的各種AI技術。然而最準確的說法,應該是兩年之前OpenAI發佈的聊天機器人ChatGPT,它是DS框架的技術基礎。
ChatGPT的名字中,Chat的意思就是對話,這個詞在AI中涉及的領域是NLP(自然語言處理);後面三個字母的意思:G生成型(generative)、P預訓練(pre-training)、T變形金剛(Transformer)。其中最重要的是“變形金剛”,而變形金剛的關鍵是“注意力機制”(Attention)。下面簡單介紹一下幾個名詞。
變形金剛
英語單詞Transformer,可以指變壓器或變換器。另外也可以翻譯成變形金剛,那是一種孩子們喜歡的玩具,可以變換成各種角色,包括人類和機械。而這兒的transformer是谷歌大腦2017年推出的語言模型。如今,無論是自然語言的理解,還是視覺處理,都用變形金剛統一起來,用到哪兒都靈光,名副其實的變形金剛!所以,我們就用這個名字。
變形金剛最早是爲了NLP[1]的機器翻譯而開發的,NLP一般有兩種目的:生成某種語言(比如按題作文),或者語言間的轉換(比如翻譯)。這兩種情況,輸入輸出都是一串序列,此種神經網絡模型稱爲“序列建模”。變形金剛的目的就是序列建模,它的結構可以分爲“編碼器”和“解碼器”兩大部分(圖1)。序列建模是AI研究中的一項關鍵技術,它能夠對序列數據中的每個元素進行建模和預測,在NLP中發揮着重要作用。
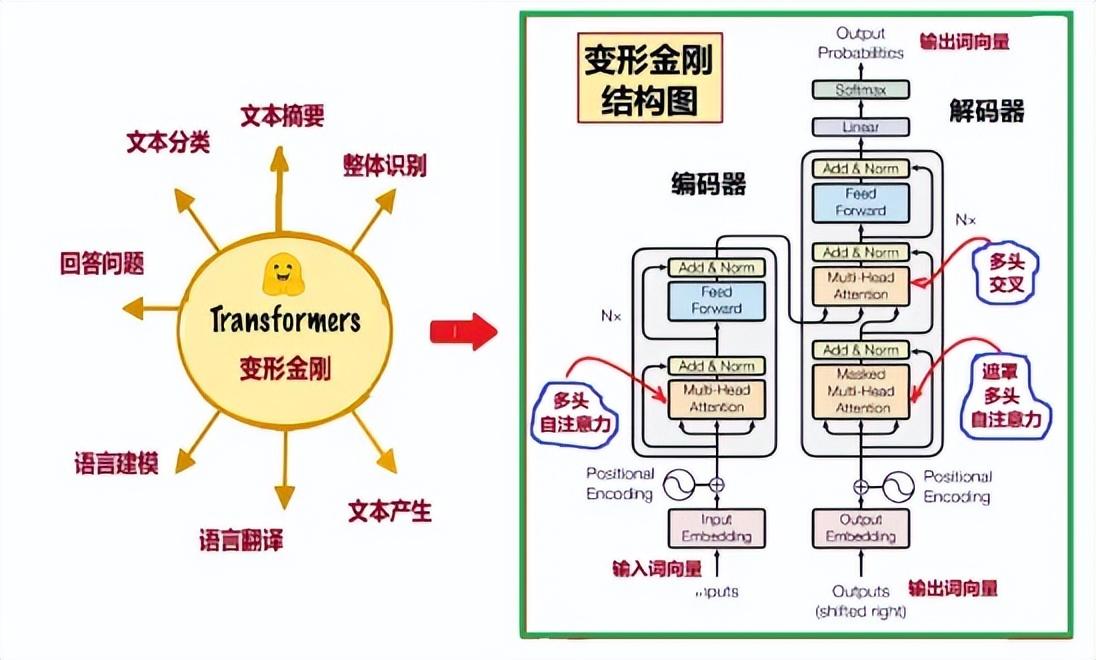
圖1:Transformer模型及其中的注意力機制
圖1右圖顯示了“編碼器”和“解碼器”的內部結構框圖。它們都包含了多頭注意力層(Multi-Head Attention)、前向傳播層(Feed Foward)和殘差歸一化層(Add&Norm)。
神經網絡模型的發展,從1958 年早期感知機的“機器”模型,到後來的算法模型,經歷了漫長的過程。變形金剛的序列建模能力,超越了之前的循壞神經網絡RNN,和卷積神經網絡CNN,近幾年,成爲了新的序列建模大殺器,廣泛應用於機器翻譯、閱讀理解和實體識別等任務中。
與變形金剛(Transformer)相關的論文,是Google機器翻譯團隊,在行業頂級會議NIPS上發表的。論文的題目是《Attention is all you need(你所需要的,就是注意力)》[2],一語道明瞭變形金剛的重點是“注意力”。圖1右的Transformer模型中,紅色曲線指出的,是3個主要的注意力機制框圖。
因此,ChatGPT大獲成功,憑藉的是強調“注意力機制”的變形金剛;介紹注意力機制之前,首先簡要介紹NLP的幾個基本概念。例如,什麼是“詞向量”,什麼是詞崁入?有那些語言模型?
自然語言處理
實現人工智能有兩個主要的方面,一是圖像識別,二是理解人類的語言和文字,後者被稱爲自然語言處理,縮寫成NLP(Natural Language Processing)。
2.1
什麼是NLP?
自然語言處理,就是利用計算機爲工具對人類自然語言的信息進行各種類型處理和加工的技術。NLP以文字爲處理對象。
最早的計算機被髮明出來,是作爲理科生進行復雜計算的工具。而語言和文字是文科生玩的東西,如何將這兩者聯繫起來呢?爲了要讓機器處理語言,首先需要建立語言的數學模型。稱之爲語言模型。ChatGPT就是一個語言模型。
語言模型最直接的任務就是處理一段輸入的文字,不同的目的應該有不同的模型,才能得到不同的輸出。例如,假設輸入一段中文:“彼得想了解機器學習”,模型可能有不同的輸出:
1,如果是中文到英文的機器翻譯模型,輸出可能是:“Peter wants to learn about machine learning”;
2,如果是聊天機器人,輸出可能是:“他需要幫助嗎?“;
3,如果是書店的推薦模型,輸出可能是一系列書名:“《機器學習簡介》、《機器學習入門》“;
4,如果是情感分析,輸出可能是:“好“……
語言模型都有兩大部分:編碼器和解碼器,分別處理輸入和輸出。
此外,對語言模型比較重要的一點是:它的輸出不見得是固定的、一一對應的,這從我們平時人類的語言習慣很容易理解。對同樣的輸入,不同的人有不同的回答,在不同環境下的同一個人,也會有不同的回答。也就是說,語言模型是一個概率模型。
2001年,本吉奧等人將概率統計方法引入神經網絡,並使用前饋神經網絡進行語言建模,提出了第一個神經網絡的語言概率模型,可以預測下一個單詞可能的概率分佈,爲神經網絡在NLP領域的應用奠定了基礎。
2.2
詞向量(Word Vectors)
語言模型中的編碼器,首先就需要給語言中的單詞編碼。世界上的語言各種各樣,它們也有其共性,都是由一個一個小部分(基本單元)組成的,有的基本單元是“詞“,有的是”字“,有的可能是詞的一部分,例如詞根。我們給基本單元取個名字,叫”token“。例如,以後在解釋語言處理過程時,我們就將中文中的“字”作爲一個”token“,而將英文中的一個“word”,算一個”token“。
計算機只認數字,不識”token“。所以首先得將”token“用某種數學對象表示,學者們選中了“矢量”
最早期對詞向量的設想,自然地聯想到了“字典”。所以,最早給詞彙編碼採用的方法叫做One hot encoding(獨熱編碼),若有個字典或字庫裏有N個單字,則每個單字可以被一個N維的獨熱向量代表。下面用具體例子說明這種方法。
例如,假設常用的英文單詞大約1000個(實際上,英語有約1300萬個單詞),按照首個字母順序排列起來,詞典成爲一個1000個詞的長串序列。每個常用詞在這個序列中都有一個位置。例如,假設“Apple”是第1個,“are” 是第2個,“bear” 是第3個,“cat” 第4個,“delicious” 第5個……等等。那麼,這5個words,就分別可以被編碼成5個1000維的獨熱矢量,每一個獨熱矢量對應於1000維空間的1個點:
“apple“: (1 0 0 0 0…………………..0)
“are” : (0 1 0 0 0…………………..0)
“bear” : (0 0 1 0 0 0…………..…..0)
“cat” : (0 0 0 1 0 0 0……………..0)
“delicious” : (0 0 0 0 1 0 0 0…………..0)
獨熱編碼概念簡單,不過,你很快就能發現這不是一個好的編碼方法。它至少有如下幾個缺點。
一是每個詞向量都是獨立的,互相無關,詞和詞之間沒有關聯,沒有相似度。實際上,詞和詞之間關聯程度不一樣。既然我們將單詞表示成矢量,而空間中的矢量互相是有關聯的。有的靠的近,有的離得遠。這種“遠近”距離也許可以用來描述它們之間的相似度。比如說,bear和cat都是動物,相互比較靠近,而apple是植物,離他們更遠一點。
二是這種編碼法中,每個詞向量只有一個分量是1,其它全是0,這種表示方法太不經濟,浪費很多空間。在1000維空間中,非常稀疏地散發着1000個點。這也使得空間維度太大,不利計算。
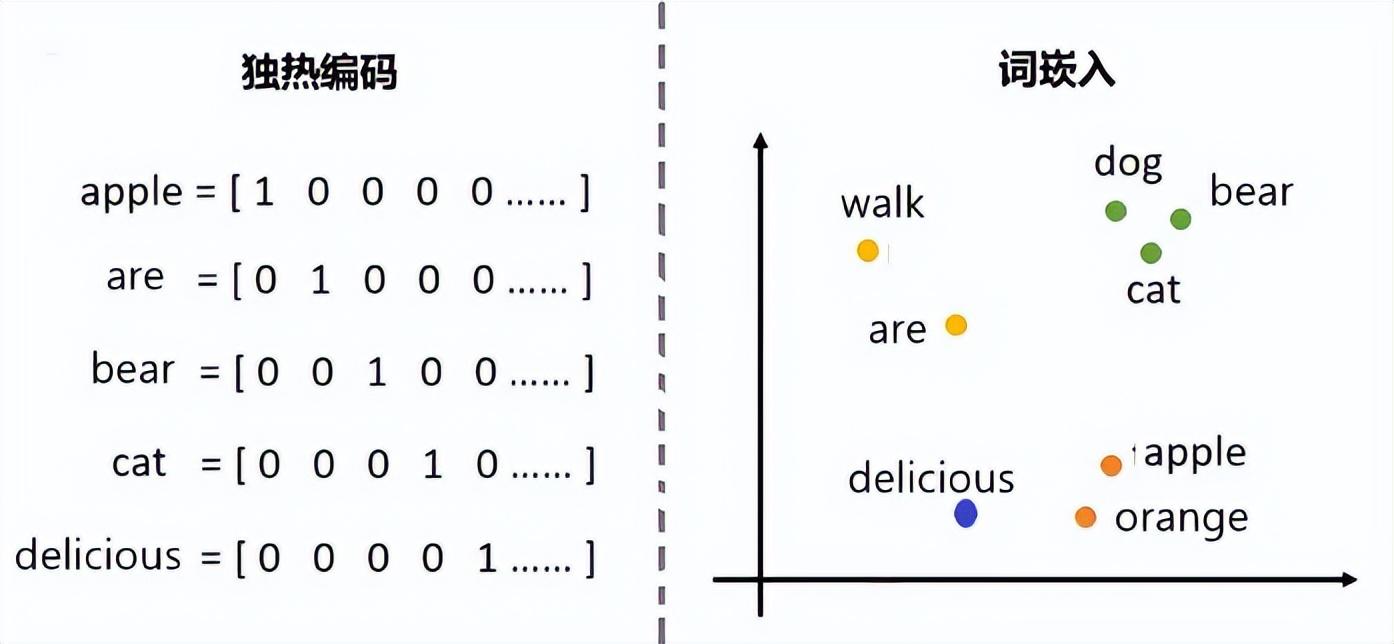
圖2:詞向量
目前NLP中使用比較多的是約書亞·本吉奧等人2000年在一系列論文中提出的技術,後來經過多次改進,如今被統稱爲“詞嵌入”(Word embedding)。它是指把一個維數爲所有詞的數量的高維空間嵌入到一個維數低得多的連續向量空間中,每個單詞或詞組被映射爲實數域上的向量。例如,圖2左圖中的1000維詞向量,被嵌入到一個2維空間(圖2右圖)中之後,將同類的詞彙分類放到靠近的2維點,例如右上方靠近的3個點分別代表3個哺乳動物。
詞嵌入中這個“維數低得多的向量空間”,到底是多少維呢?應該是取決於應用。直觀來說,每一個維度可以編碼一些意思,例如語義空間可以編碼時態、單複數和性別等等。那麼,我們利用“詞嵌入”的目的是:希望找到一個N維的空間,足夠而有效地編碼我們所有的單詞。
當然,詞嵌入的具體實現方法很複雜,維數可以比1000小,但比2大多了,在此不表。
2.3
NLP和神經網絡
在變形金剛之前的NLP,是用循環神經網絡RNN、遞歸神經網絡、雙向和深度RNN、或基於RNN改進的LSTM等實現的。可以使用上述的同一種網絡結構,複製並連接的鏈式結構來進行自然語言處理,每一個網絡結構將自身提取的信息傳遞給下一個繼承者。見圖3。
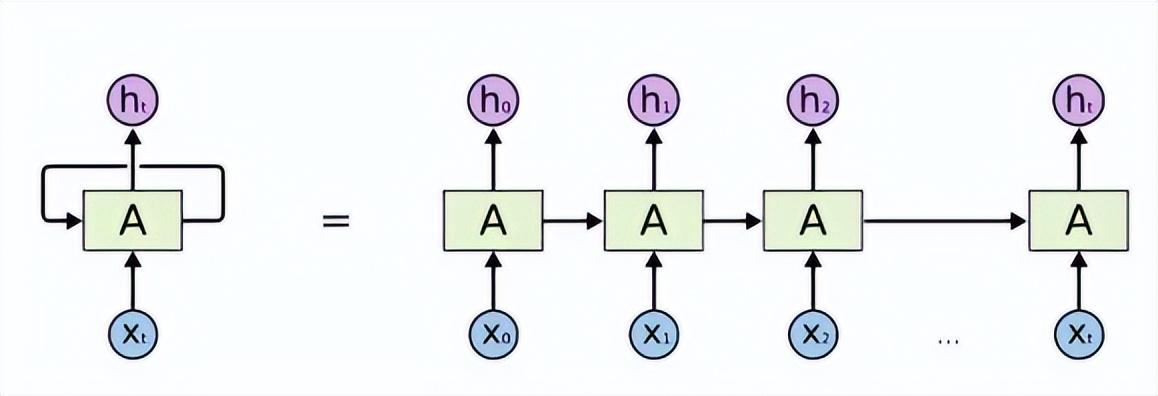
圖3:RNN鏈接受上下文單詞,預測目標單詞
語言模型的目的就是通過句子中每個單詞的概率,給這個句子一個概率值P。即通過計算機系統對人輸入問題的理解,利用自動推理等手段,自動求解答案並做出相應的回答。
循環神經網絡RNN是在時間維度展開,處理序列結構信息。遞歸神經網絡在空間維度展開,處理樹結構、圖結構等複雜結構信息。
LSTM等模型和transformer的最大區別是:LSTM等的訓練是迭代的,是一個一個字的來,當前這個字過完LSTM單元,纔可以進行下一個字的輸入。但transformer使用了注意力機制,可以並行計算,所有字同時訓練,大大提高了效率。並行計算中,使用了位置嵌入(positional encoding)來標識這些字的先後順序。那麼,什麼是“注意力機制”?
“注意力機制”
3.1
什麼是注意力機制?
神經網絡的思想最早是來源於生物學的神經網絡,但是,現代的深度學習卻早已脫離了對大腦的模仿。不過,人們在AI研究中碰到困難時,總免不了要去對比一下生物大腦的運行機制。這也是“注意力機制”這個概念的來源。
注意力機制是人類大腦的一種天生的能力。我們⼈類在處理信息時,顯然會過濾掉不太關注的信息,着重於感興趣的信息,於是,認知專家們將這種處理信息的機制稱爲注意⼒機制。
例如,我們在看親友的照片時,先是快速掃過,然後通常更注意去識別其中的人臉,將更多的注意力放在照片呈現的人物、時間、和地點上。當我們閱讀一篇新的文章時,注意力首先放在標題上,然後是開頭的一段話,還有小標題等等。
人類的大腦經過長期的進化,類似於機器學習中應用了最優化的學習方法,形成了效率頗高的結構。試想,如果人腦對每個局部信息都不放過,那麼必然耗費很多精力,把人累死。同樣地,在人工智能的深度學習網絡中,引進注意⼒機制,才能簡化網絡模型,以使用最少的計算量,有效地達到目的。大腦回路的結構方式,肯定影響着大腦的計算能力。但是,到目前爲止,除了在一些非常簡單的生物體中,我們仍然沒有看到任何大腦的具體結構。不過,研究AI的專家們,有自己的辦法來實現他們的目標,例如循環神經網絡,長短期記憶,都解決了部分問題。
當科學家們利用循環神經網絡,處理NLP 任務時,長距離“記憶”能力一直是個瓶頸,而現在引入的“注意力機制”,有效地緩解了這一難題。此外,從節約算力的角度考慮,也有必要用“注意力機制”,從大量信息中,篩選出少量重要信息,並聚焦到這些重要信息上,忽略大多不重要的信息。
3.2
注意力機制的種類
注意力機制可以按照不同的需要來分類,這兒我們只解釋與Transformer相關的幾種結構。
1,硬注意力機制:選擇輸入序列某一個位置上的信息,直接捨棄掉不相關項。換言之,決定哪些區域被關注,哪些區域不被關注,是一個“是”或“不是”的問題,某信息或“刪”,或“留”,取其一。例如,將圖像裁剪,文章一段全部刪去,屬於此類。
2,軟注意力機制,即通常所說的“注意力機制”:選擇輸入序列中的所有信息,但用0到1之間的概率值,來表示關注程度的高低。也就是說,不丟棄任何信息,只是給他們賦予不同的權重,表達不同的影響力。
3,“軟”vs“硬”:硬注意力機制,只考慮是和不是,就像2進制的離散變量;優勢在於會節省一定的時間和計算成本,但是有可能會丟失重要信息。離散變量不可微分,很難通過反向傳播的方法參與訓練。而軟注意力機制,因爲對每部分信息都考慮,所以計算量比較大。但概率是連續變量,因此軟注意力是一個可微過程,可以通過前向和後向反饋學習的訓練過程得到。變形金剛中使用的是“軟注意力機制”,見圖4a。圖中輸入是Q、K、V,分別代表Query(查詢)、Key(關鍵)、Value(數值)。
4,自注意力機制:如果圖4a中的Q、K、V都從一個輸入X產生出來,便是“自注意力機制” (圖4b)。它的意思是:對每個輸入賦予的權重取決於輸入數據之間的關係,即通過輸入項內部之間的相互博弈決定每個輸入項的權重。因爲考慮的是輸入數據中每個輸入項互相之間的關聯,因此,對輸入數據而言,即考慮“自己”與“自己”的關聯,故稱“自”注意力機制。自注意力機制在計算時,具有並行計算的優勢。使輸入序列中的每個元素能夠關注並加權整個序列中的其他元素,生成新的輸出表示,不依賴外部信息或歷史狀態。自注意力通過計算每個元素對其他所有元素的注意力權值,然後應用這些權值於對應元素本身,得到一個加權平均的輸出表示。
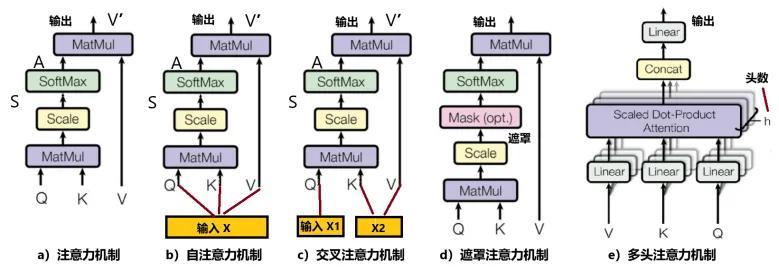
圖4:各種注意力機制
5,注意力機制與自注意力機制的區別:注意力機制的權重參數是一個全局可學習參數,對於模型來說是固定的;而自注意力機制的權重參數是由輸入決定的,即使是同一個模型,對於不同的輸入也會有不同的權重參數。注意力機制的輸出與輸入的序列長度可以不同;而自注意力機制的的輸出輸入序列長度是相同的。注意力機制在一個模型中通常只使用一次,作爲編碼器和解碼器之間的連接部分;而自注意力機制在同一個模型中可以使用很多次,作爲網絡結構的一部分。注意力機制將一個序列映射爲另一個序列;而自注意力機制捕捉單個序列內部的關係。
6,交叉注意力機制:考慮兩個輸入序列(X1、X2)內部變量之間的關聯,見圖4c。
7,遮罩(Masked)注意力機制:在計算通道中,加入一個遮罩,遮擋住當前元素看不見(關聯不到)的部分,見圖4d。
8,多頭自注意力機制:由多個平行的自注意力機制層組成。每個“頭”都獨立地學習不同的注意力權重,最後綜合合併這些“頭”的輸出結果,產生最終的輸出表示。多頭機制能夠同時捕捉輸入序列在不同子空間中的信息,從而增強模型的表達能力,見圖4e。
3.3
注意力機制如何工作?
最基本的注意力機制如圖5a所示,它的輸入是Q、K、V,分別代表Query(查詢)、Key(關鍵)、Value(數值)。具體而言,Q、K、V都可以用矩陣表示。計算的步驟如下:算出Q和K的點積,得到他們的相似度,經過softmax函數作用歸一化之後,得到相互影響的概率A,然後,將A作用到V上,最後得到的V‘即爲注意力。
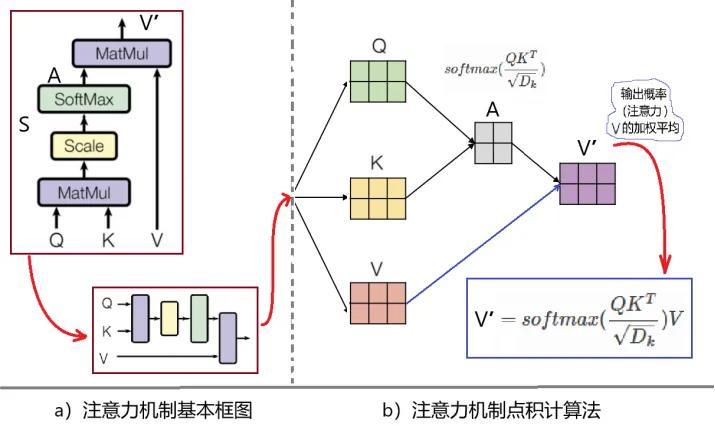
圖5:注意力機制的計算
乍一看上面的敘述有點莫名其妙,這幾個Q、K、V是何方神聖?從哪裏鑽出來的?
首先,我們舉一個自注意力機制的例子,用一個通俗的比喻解釋一下。自注意力機制中的Q、K、V,都是由輸入的詞向量產生出來的。比如,老師去圖書館想給班上學生找“貓、狗、兔子”等的書,老師可能會與管理員交談,說:“請幫忙找關於養貓狗兔的書”。那麼,老師的查詢之一可能是,Query:養貓書、管理員給老師幾個書名Key:《貓》、《如何養貓》……,還從圖書館的計算機資料庫中得到相關信息Value:這幾本書的作者、出版社、分類編號等等。
上面例子中,輸入的序列詞向量是老師說的那句話的編碼矩陣,即圖4b中的輸入X。然後,從如下計算得到矩陣Q、K、V:
Q = X Wq,
K = X Wk,
V = X Wv。
這兒的Wq 、Wk 、Wv 是將在訓練中確定的網絡參數。
圖5是注意力機制計算過程的示意圖。右下角的方框裏,是注意力機制的計算公式。公式中有一個乘積項:QKT,意思是Q和K的內積。兩個向量的內積,等於它們的模相乘,再乘以它們之間夾角的cosine函數,因此可以描述兩個向量接近的程度。內積越大,表示越接近。計算公式括號內的分母:Dk開方,代表注意力機制框圖中的“Scale” (進行縮放)部分。這兒Dk是KT的維數,除上維數開方的目的是穩定學習過程,防止維度太大時“梯度消失”的問題。然後,點積加縮放後的結果,經softmax歸一化後得到相互影響概率A。最後,再將結果A乘以V,得到輸出V'',這個輸出矢量描述了輸入矢量X中各個token之間的自注意力。
綜上所述,從自注意力機制,可以得到輸入詞序列中詞與詞之間的關聯概率。比如說,假設輸入的文字是:“他是學校足球隊的主力所以沒有去上英語課”,訓練後可以得到每個字之間相關情況的一種概率分佈。但是,字之間的相關情況是很複雜的,有可能這次訓練得到一種概率分佈(“他”和“球”有最大概率),下次得到另外一種完全不同的概率分佈(“他”和“課”有最大概率)。爲了解決這種問題,就採取多算幾次的辦法,被稱爲“多頭注意力機制”。就是將輸入矢量分成了幾個子空間的矢量,一個子空間叫一個“頭”。
也可以使用上面所舉老師去圖書館找書的例子,除了“貓“和”書“關聯之外,狗、兔子……等都可能和”書“關聯起來,也可以使用“多頭注意力機制”來探索。
參考資料:
[1]NLPhttps://en.wikipedia.org/wiki/Natural_language_processing
[2]Vaswani, Ashish; Shazeer, Noam; Parmar, Niki; Uszkoreit, Jakob; Jones, Llion; Gomez, Aidan N.; Kaiser, Lukasz; Polosukhin, Illia. Attention Is All You Need. 2017-12-05. arXiv:1706.03762