【科技聯播】從 ChatGPT 到 o1:OpenAI 如何再度引領 AI 變革
這裏是科技聯播第 6 期。這期講透一個新聞,OpenAI 新發布的 o1 模型。這很可能是 2022 年發佈 ChatGPT 之後, OpenAI 第二次改變人工智能的發展方向。
出其不意的發佈
北京時間 9 月 13 日凌晨,OpenAI 公佈了他們最新的 AI 模型。不是 GPT-5 ,而是 o1。爲了和以前的模型作出區別,凸顯這次的改變特別巨大,他們放棄了之前一直用的 GPT 前綴,只用 o1 或 OpenAI-o1 表示,而不是 GPT-o1。
9 月 13 日,OpenAI 發佈 o1 模型
這次的發佈非常突然,之前沒有任何徵兆。現在付費用戶已經可以體驗到 o1-preview(預覽版)和 o1-mini(mini 版),滿血版本還沒有對外開放。
對於大衆用戶來說,o1 模型帶來的改變,就像以前在和一個文科生對話,現在變成了和理科生對話。以前的模型,如果是用來做翻譯、摘要、總結,完全可以代替一個普通的文祕。但是如果交給它比較複雜的數學題、物理題,那麼它可能就會給出一份語言流暢但是錯誤百出的答案。
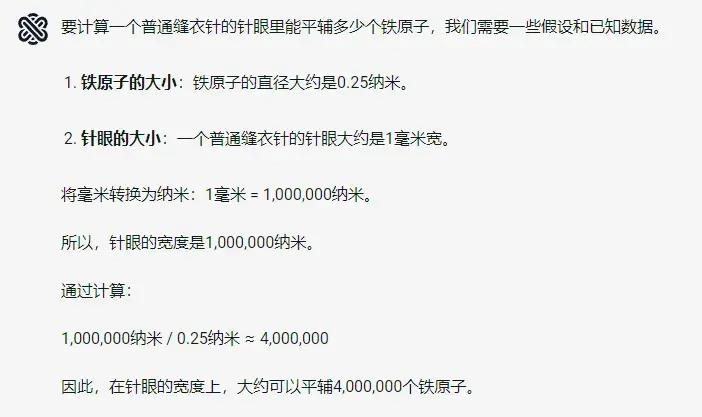
當你向以前的模型提問“一個縫衣針的針眼裏能平輔多少鐵原子?”
而拿類似的問題問 o1 ,它則會一步一步將思考和推理的過程呈現出來,計算的思路明顯更加準確。

當你向 OpenAI-o1 提問“一個縫衣針的針眼裏能平輔多少鐵原子?”
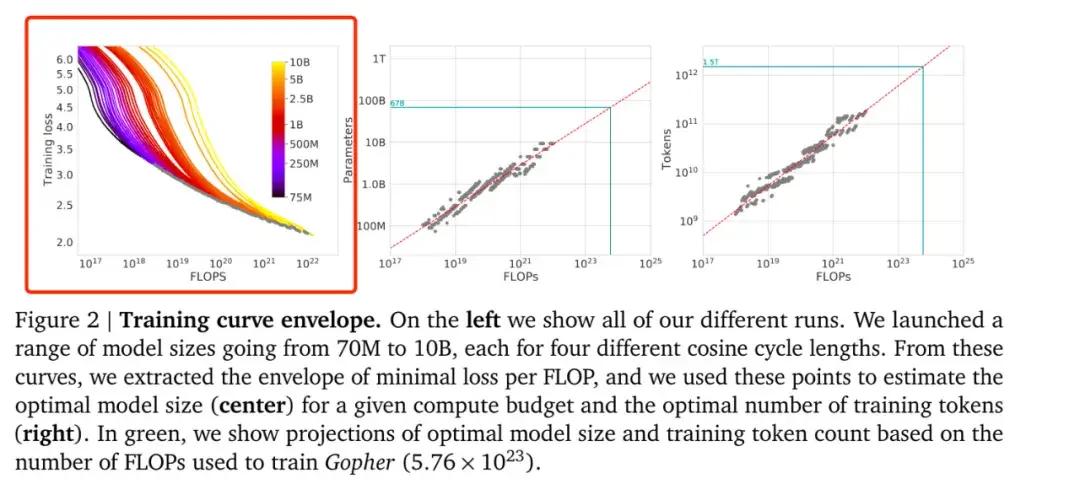
普通大衆讚歎更多的,是 o1 在回答問題上的深思熟慮。但是很多專業人士,關注的則是一個叫 Scaling Law 的規律。這個詞還沒有確定的翻譯,可以叫做“規模定律”或“規模縮放定律”。
Scaling Law:AI界的摩爾定律
Scaling Law 揭示了深度學習的能力和規模之間最根本規律,對於 AI 行業來說,它就類似於集成電路行業裏的摩爾定律。
從 2019 年開始,這條規律就在指導着 AI 領域的發展,尤其是 OpenAI 更是它的忠實信徒。如果把 Scaling Law 看作是 AI 領域裏的摩爾定律的話,那麼 OpenAI 就是 AI 領域裏的 Intel。
Scaling Law 這個詞來自於標度理論(Scaling Theory),是一個用於描述和預測複雜系統在不同規模下行爲的理論框架。它最核心的內容是指出,在許多不同的系統中,這個系統的某個性能指標和它的規模呈現冪律關係。
冪律分佈示意圖(可見長尾效應)
比如在物理學中,一個系統在相變點附近,系統的某些物理量會隨着系統規模的變化而呈現出冪律關係。在網絡科學中,網絡中的節點度分佈往往遵循冪律分佈;在生物學中,動物的代謝率與其體重之間也呈現冪律關係;在城市科學中,城市規模與城市的GDP、犯罪率、疾病傳播等各種指標之間也是冪律關係。
在人工智能領域,Scaling Law 則是指一個模型的錯誤率和它的規模呈現冪律關係。並且這個冪律關係,不依賴於具體的模型和算法細節。

Scaling Law 示意
和摩爾定律一樣,Scaling Law 也是從過往經驗中總結出的經驗規律。不過和摩爾定律不同,摩爾定律體現的是一個指數增長的規律,效能總是隨着時間翻倍增加;Scaling Law 則是一個冪律下降的規律,效能的提高並不是和成本成比例,而是和成本的數量級成比例。也就是說,Scaling Law 是一個投入產出比非常差的規律,可即便這樣,這也是深度學習模型可以達到的最好效果。
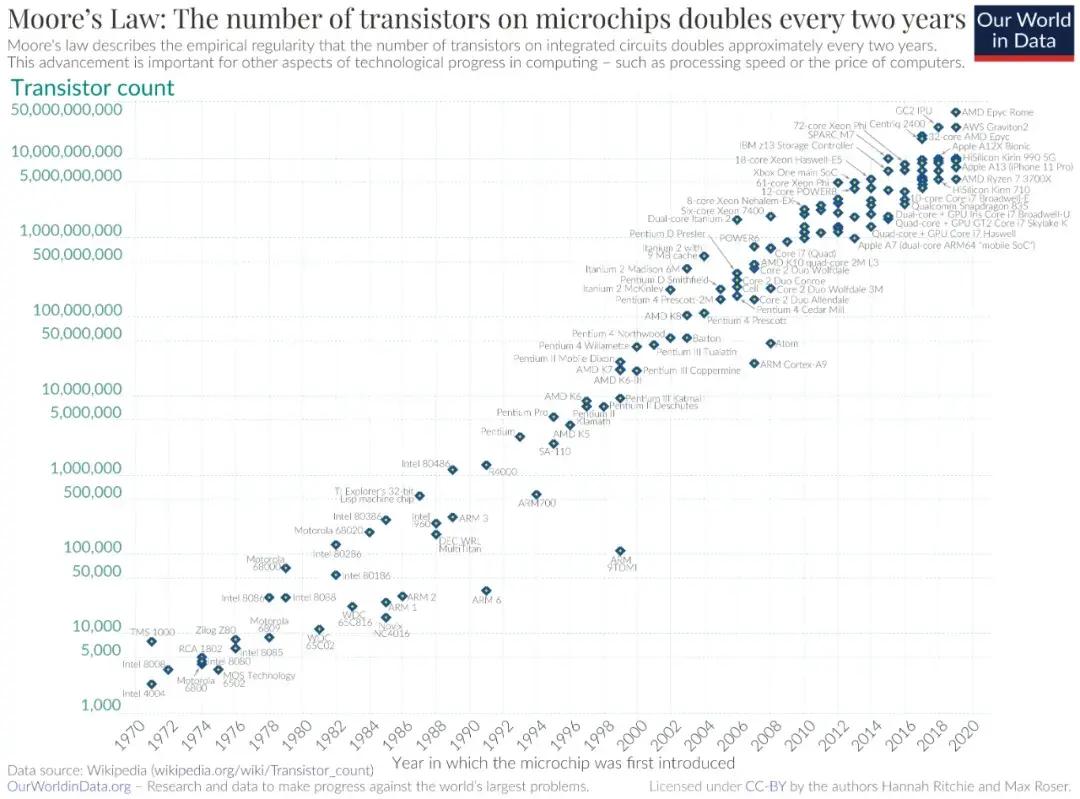
摩爾定律
深度學習的 Scaling Law,最早是由百度硅谷研究院在 2017 年發表的一篇論文提出的,但這篇論文裏只提到了模型的錯誤率和數據規模有冪律關係。
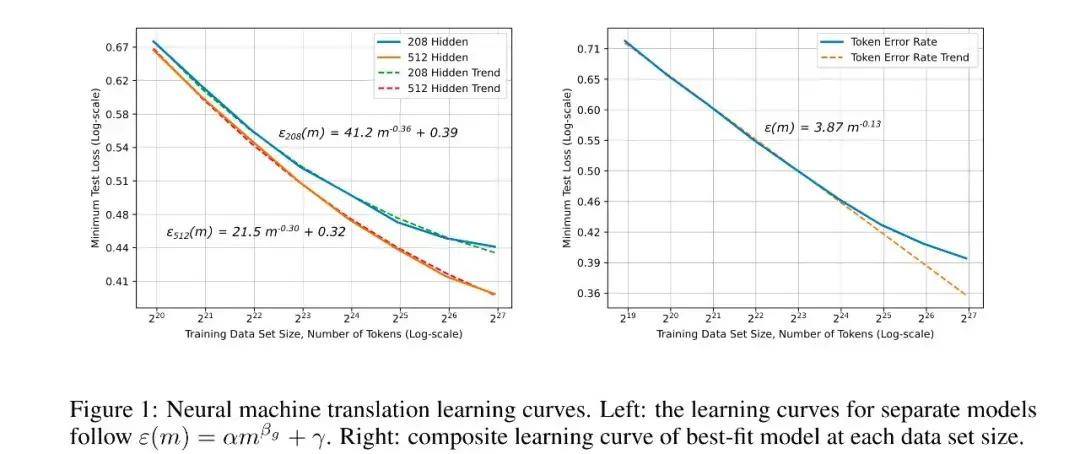
“Deep Learning Scaling is Predictable, Empirically”
從 GPT-3 到 GPT-4
真正讓這個規律價值發揮出來的還是 OpenAI。OpenAI 在 2020 年 1 月發表了一篇論文。這篇論文指出,大語言模型的錯誤率不只和數據規模有冪律關係,和計算規模、參數規模也有冪律關係。
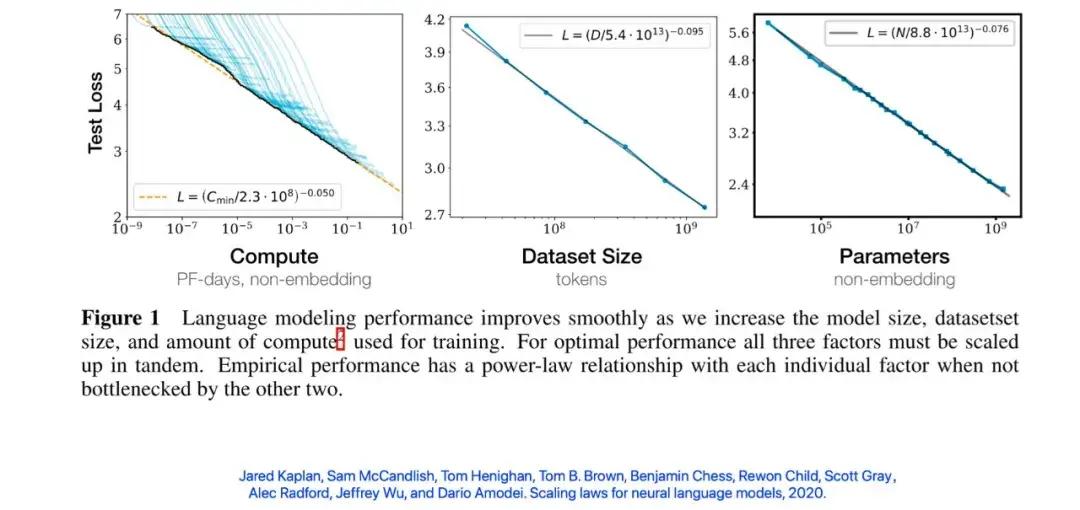
大語言模型的錯誤率和數據規模、計算規模、參數規模有冪律關係
在這篇論文中,OpenAI 提到的規模最大的模型參數是 1.5B,也就是 15 億,訓練時間需要每秒千萬億次的設備計算 10 天,也就是 10 petafloat-day(PF-day)。在當時,這個設備大概需要 33 個英偉達的 V100 GPU。
如果模型擴大 100 倍,需要用到的訓練時間是多少呢?很快,這個問題就有了答案。2020 年 6 月,OpenAI 公佈了他們的 GPT-3,參數規模 175B。根據後來的估算,訓練 GPT-3 大概花了 92 天的時間。而訓練用的設備則是微軟提供的超級計算機,其配備了 10000 個 V100 GPU。
這個數據繼續遵循着 Scaling Law。
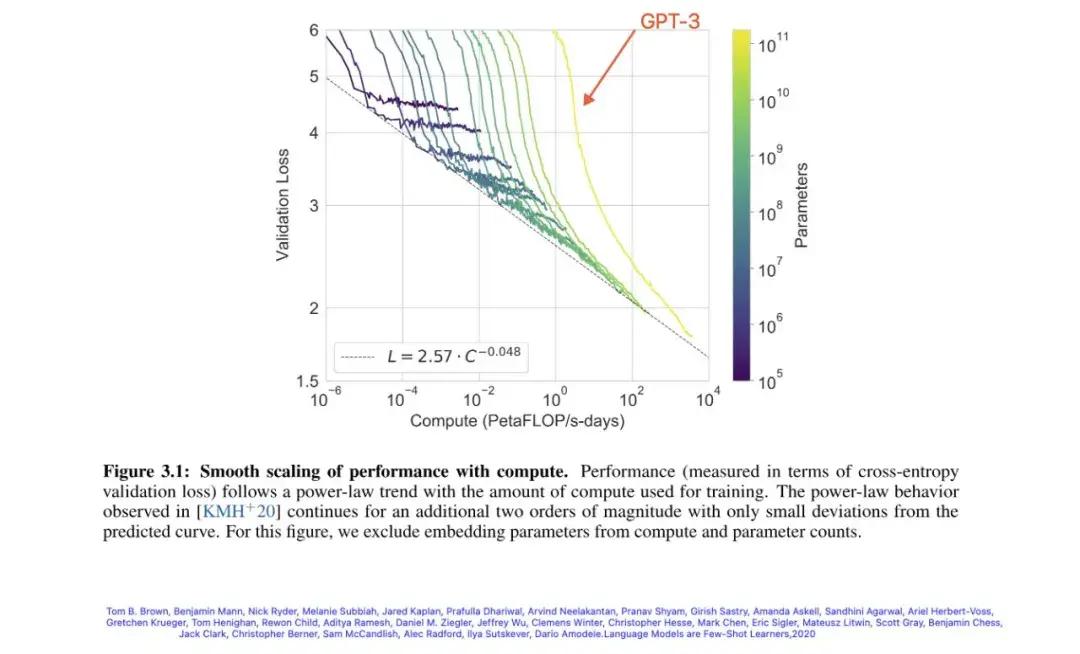
GPT-3 的曲線也遵循 Scaling Law
雖然這篇論文是 GPT-3 發佈後的事後總結,但現實情況是,OpenAI 很可能在更早的時候就開始利用 Scaling Law 規劃自己的發展。
就在 GPT-3 發佈的前一年,OpenAI 打破了自己非營利組織的性質,轉變爲有限利潤公司,而且也改變了模型的開源策略。尤其在 2019 年 7 月,微軟向 OpenAI 投資 10 億美元,雙方在 Azure 雲計算服務上訓練最新的大語言模型,也就是 GPT-3。
這一次的戰略調整可以說非常冒險,我們現在已經知道,這一次組織結構的變更,直接導致了 2023 年底 OpenAI 首席科學家伊利亞聯合董事會罷免 CEO 奧爾特曼的“宮斗大戲”,險些導致 OpenAI 的分崩離析。而 OpenAI 不再開源的改變,也讓 OpenAI 處於輿論的劣勢,還被戲稱爲“ClosedAI”。
是什麼讓奧爾特曼下定決心做出如此大的改變?是什麼幫助他決策出只需要 10 億美元就可以訓練出下一代大語言模型?又是什麼讓他對下一代模型的能力抱有信心?
現在來看,很可能就是 OpenAI 在 2020 年 1 月論文裏提到的這個 Scaling Law 。
Scaling Law 和摩爾定律一樣——在幾十年的時間裏,Intel 就是根據摩爾定律去預測下一代、下下一代產品的規模,然後去規劃芯片的設計研發和晶圓廠發展計劃的;在 AI 領域,Scaling Law 已經具備了類似的潛質,以 OpenAI 爲主導的業內人士也會利用 Scaling Law 幫助自己去估計未來的投入和產出。在還沒有真的把模型訓練出來之前,就可以預測,如果想讓模型達到某個想要的效果,至少需要多少顯卡,可以釋放多少股權、吸收多少投資。
Scaling Law 失效?
不過 Scaling Law 和摩爾定律也不同。摩爾定律持續了幾十年,直到最近幾年纔有了摩爾定律將會失效的討論。而對 Scaling Law 失效的討論則來得有些早。2020 年 1 月,在 OpenAI 的論文中,錯誤率和規模的圖像在對數座標還看不到拐點(冪律圖像在對數座標中是一條直線)。這樣還可以期待隨着規模的增加,錯誤率可以逐漸接近 0。
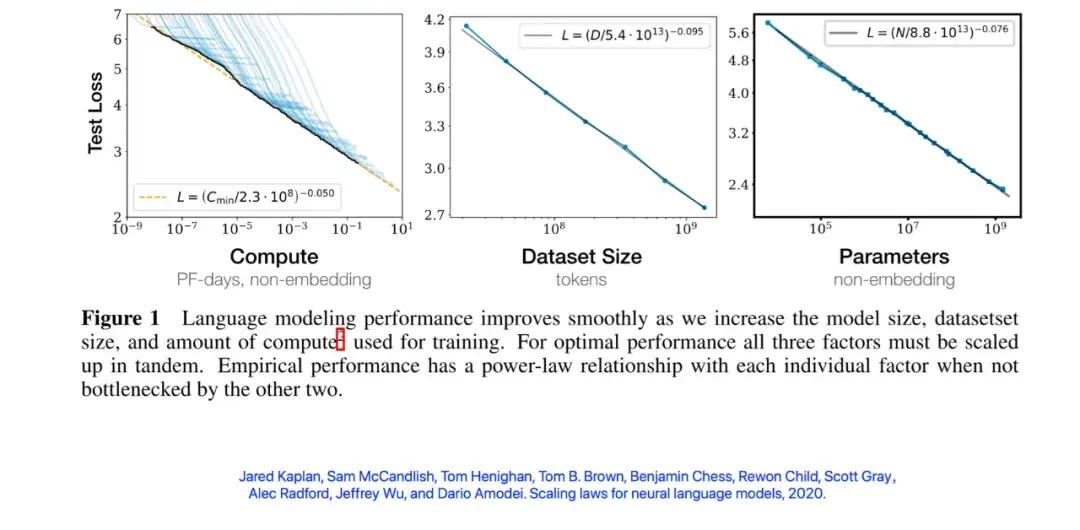
錯誤率和規模的圖像在對數座標中看不到拐點
但是僅僅過了 10 個月,2020 年 11 月,在 OpenAI 的另一篇論文中,Scaling 的有效性就迎來了挑戰,圖像模型、視頻模型的錯誤率隨着規模的增加,有一個無法消除的下限,而不是可以接近於 0。換句話說,規模增加對模型能力帶來的影響是有天花板的。
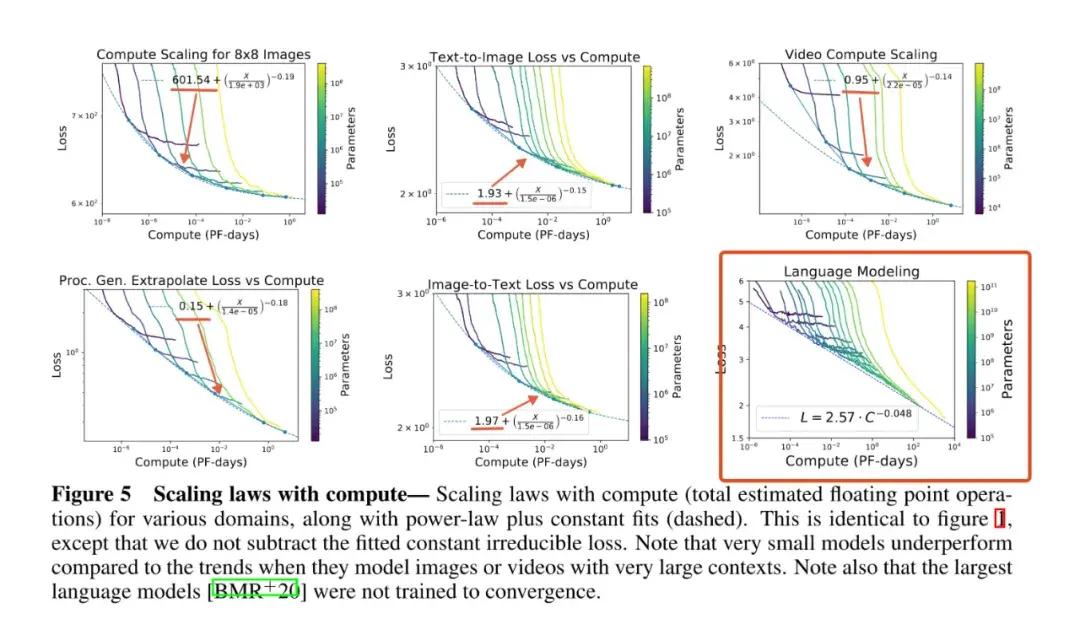
圖像模型、視頻模型的錯誤率並不可以接近於 0
不過,這篇論文給大語言模型還留下了一線希望,因爲在大語言模型中還沒有觀察到明顯的拐點。但是這並不代表着,大語言模型的收益可以隨着規模的增加一直增加。
這是因爲,在 2022 年 3 月份的時候,谷歌的 Deepmind 團隊也發表了一篇論文,論文指出:即便是大語言模型,在規模無限大的時候,一定也有一個無法消除的下限。像 GPT-3 那樣有千億級別的參數規模,這個下限還不需要特別考慮,但是下一步是否規劃更大規模的大語言模型、爲了訓練更大規模的模型而投入更多成本是否值得,這篇論文中並沒有結論。
Deepmind 團隊論文截圖
不知道 OpenAI 是否也有 Scaling Law 可能會失效的顧慮,GPT-3.5 的參數規模只有少量增加,從原來的 175B 提高到了200B 左右。GPT-3.5 更多的是優化了自然語言和代碼的生成能力,也正是在此基礎上,OpenAI 做出了第一個爆款應用 ChatGPT。
ChatGPT 的發佈時間 2022 年 11 月 30 日,也成爲了 AI 元年的開端,各大廠商紛紛入局開始佈局自己的大模型。
在人們還沒有來得及思考 Scaling Law 是否已在失效邊緣的時候,OpenAI 在 2023 年 3 月就發佈出了 GPT-4。儘管 OpenAI 沒有公開 GPT-4 的技術細節,不過業內人士還是可以估計它的參數已經達到了 1000B 的規模。相比 GPT-3,GPT-4 的模型規模擴大了將近 10 倍,而訓練花費則是增加了將近 100 倍。
在 GPT-4 的技術報告中,OpenAI 又再次強調:在訓練 GPT-4 之前,他們就根據 Scaling Law 預測過模型的最終表現。而實際結果表明,他們的預測非常準確。
從 ChatGPT 到 GPT-4 只用了 3 個多月的時間,所以難免會讓人產生期待,OpenAI 匹配 Scaling Law 的下一次升級可能很快就會到來。
不過讓人失望的是,這期間只發布過不疼不癢的 GPT-4o,雖然中間也有內部項目 Q* 和“草莓”,就是 GPT-5 的流言,但是在 1 年多的時間裏,OpenAI 的表現的確是讓人失望。
尋找新增長模式
與此同時,其他廠商正在加快腳步追趕,先是有 Anthropic 公司的 Claude 3 Sonnet,後有 Meta 的 Llama 3。越來越多的大語言模型追趕上了 GPT-4 的性能。在這個過程中,GPT-4 爲什麼可以在規模如此巨大的情況下,依然能匹配 Scaling Law 的奧祕,也被逐漸發掘出來。如果僅僅是靠增加參數規模和堆積更多的訓練算力,很難在 1000B 參數的規模下繼續匹配 Scaling Law。

Claude 3 Sonnet
而 GPT-4 可以做到這一點,依賴於它在模型訓練之外進行的優化。主要分爲訓練前(pre-training)和訓練後(post-training)兩部分。
“訓練前”往往是指對數據的預處理,方便模型讀取和理解。GPT-4 就引入了多模態功能,可以處理文本和圖像輸入,讓訓練的數據更加豐富。
“訓練後”往往是指對模型的微調。GPT-4 就用到了“基於人類反饋的強化學習”(RLHF),減少了不當內容響應的概率,提高了生成事實性內容的能力。
但是,訓練前和訓練後的優化,可以帶來的性能提升終究是有限的。否則 OpenAI 也不會超過 1 年時間沒有繼續公佈新模型,而其他團隊的模型即便超過了 GPT-4 也沒有大幅領先。
很多業內人士都清楚,Scaling Law 或許還沒到失效的地步,但是要想繼續匹配 Scaling Law,就需要尋找到新的增長模式。

李開復評價 Scaling Law
o1 思維鏈:AI 新增長模式?
o1 裏的思維鏈(CoT)或許就代表着這個新增長模式。o1 發佈之後,OpenAI 研究員 Noam Brown 在他的社交媒體上,就直接將其稱爲匹配 Scaling Law 的新範式。
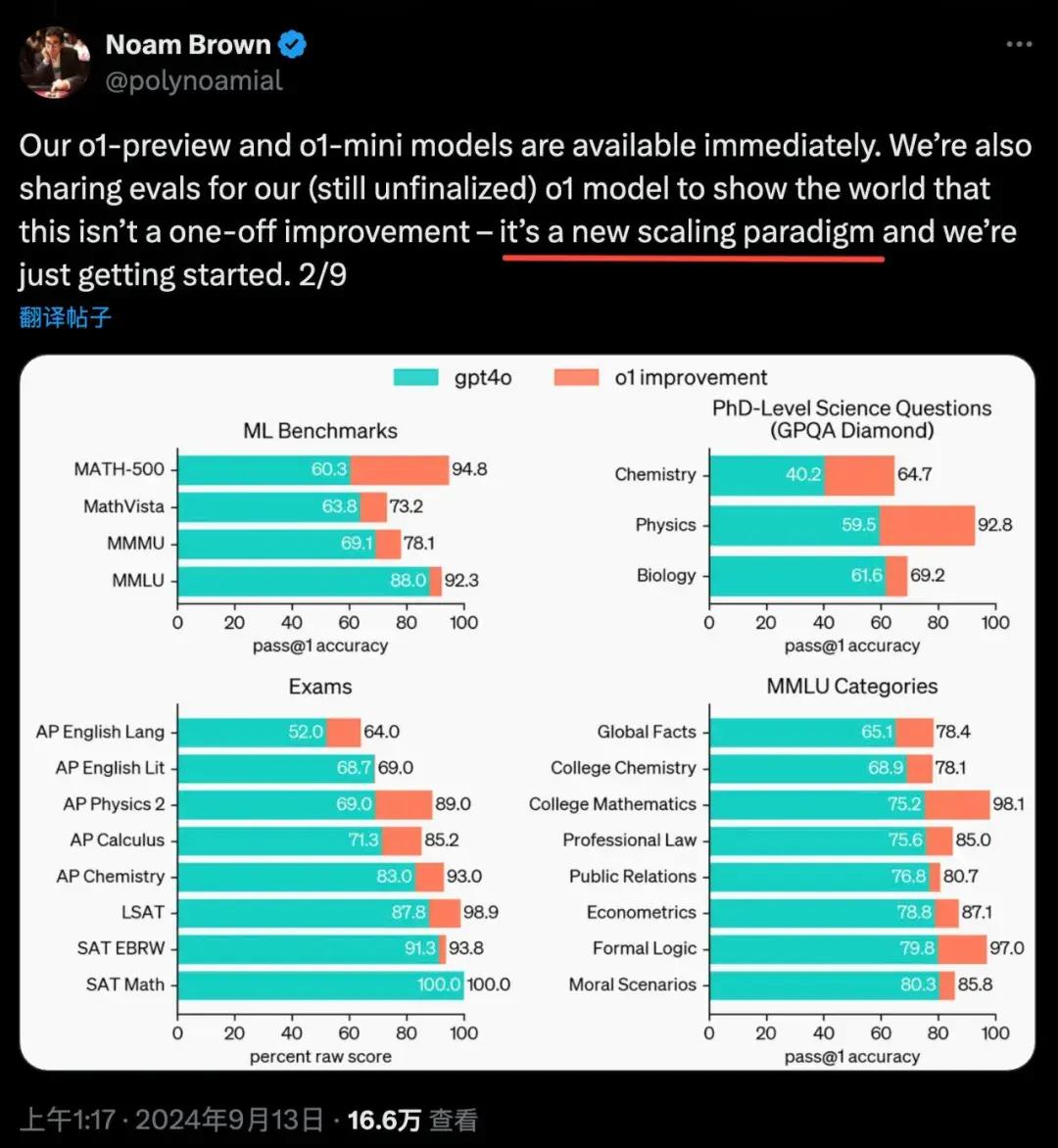
OpenAI 研究員將思維鏈(CoT)稱爲匹配 Scaling Law 的新範式
思維鏈對於普通用戶來說,就是讓 AI 模型懂得了分步驟思考,每個步驟都可以通過反思的方式增加最終回答的準確程度。而增加了 AI 模型最終回答的準確程度,也就是提高了 AI 模型的能力。思維鏈之所以可以稱爲維持 Scaling Law 的新範式,是因爲這部分能力的提升並不依賴模型的訓練過程,而是依賴於一個模型在訓練完成之後的推理過程(Inference)。
o1 之前的大語言模型規模增長,帶來的主要成本是訓練成本;而思維鏈則可以將傳統的Training-Time Scaling 模式轉化成 Inference-Time Scaling。

o1 概念圖
在 o1 發佈之後,英偉達的高級研究經理 Jim Fan 就直接將其稱爲 Inference-Time Scaling 範式。
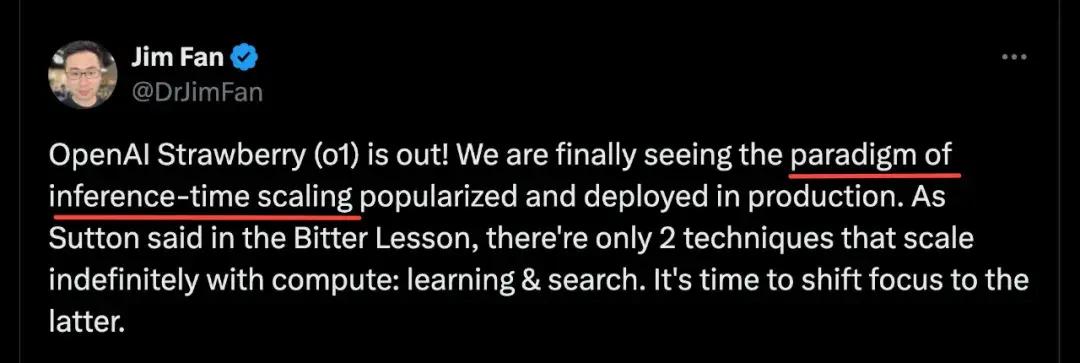
英偉達高級研究經理將 o1 稱爲 Inference-Time Scaling 範式

訓練完成之後的推理過程(Inference)大幅增長
o1 所帶來的模式轉化,不只是爲 Scaling 找到了新增長模式,對算力的成本分配也會帶來新的可能。
訓練過程一定是在服務器端完成的,所以訓練的算力成本一定是由模型的開發者全部承擔;而推理過程可以在用戶自己的手機和電腦上完成,這部分算力成本可以由用戶承擔。
當然,o1 這種依靠思維鏈的方式,是否真的代表着 AI 迎來了新增長模式,我們現在還只能做出期待,下結論還爲時過早。相信後續會有更多研究,我們科技聯播也會持續關注。
這就是本期爲你帶來的有關 Open AI 最新發布的 o1 模型的深度解讀,希望你能有所收穫,咱們下期再見。
- 互動話題 -
你認爲 o1 模型的發佈對人工智能領域意味着什麼?
歡迎在留言裏分享你的看法~