三大巨頭卡住AI脖子:英偉達、臺積電,還有一個是誰?

ChatGPT火了大模型,賦予英偉達巨大的“鈔能力”,一個H100加速卡就要35000美元,但成本卻只有3000美元,你知道這3000美元誰賺得最多嗎?你可能會脫口而出,臺積電,沒錯——纔怪!因爲還有一個並不怎麼如雷貫耳的名字,比臺積電賺得多得多,這三家公司,就構成了壟斷AI命脈的三大巨頭,那麼它們是如何走上卡脖子的光輝道路的呢?
英偉達
AI大戰,核心是什麼?毫無疑問是算力,算力就相當於打仗用的彈藥,彈藥越多火力越強,打贏的可能性就越大。目前市面上能夠提供AI算力的,主要有英偉達的GPU,AMD的GPU和谷歌的TPU,但英偉達的彈藥,無疑是火力最猛最強勁的,爲什麼要這樣說呢?
GPU打敗CPU,是英偉達壟斷之路的起點。傳統的CPU一個核心只能處理一個任務,就像人腦一樣,處理大量數據就犯迷糊了,而GPU擁有大量的計算核心,可以同時執行很多相似的計算任務,從而可以在短時間內處理大量的數據,另外,傳統CPU訓練深度神經網絡也效率低下,而GPU因爲能夠並行計算,可以大大縮短大模型的訓練時間,甚至從幾十天降到幾個小時。

但說起GPU你可能有點陌生,GPU全稱Graphics Processing Unit,圖形處理單元,是不是有點摸不着頭腦?但顯卡你應該很熟悉吧,沒錯,GPU就是顯卡上的核心芯片。
GPU最早由英偉達在1999年提出,後來英特爾和AMD把它集成到了主板上,然後集成到CPU上,在筆記本和個人電腦上賺得盆滿鉢滿,兩者也因此如日中天,當時在電腦領域可以說無人不知,無人不曉。而英偉達則一直做獨立顯卡,踽踽獨行,在遊戲興起後纔開始大顯身手。
但真正的轉折是2022年底OpenAI的ChatGPT橫空出世,讓人們意識到算力和並行處理能力在深度學習和推理任務中的巨大作用,英偉達的GPU加速卡就像原子彈一樣爆發了,股價也來到了僅次於微軟、蘋果的第三位,並且差距越來越小,看起來很有竄上第一的潛力。

但做GPU的並不只有英偉達一家,AMD也有GPU,谷歌早就在開發專爲深度學習設計的TPU,也就是張量處理單元了,爲什麼歷史的幸運兒會是英偉達呢?
和CPU一般只有幾個計算核心不同,GPU有數百數千甚至數萬個計算核心,但光有核心顯然不行,你還得把它們組織起來發揮作用。英偉達因而開發了CUDA技術,這是一種並行計算平臺和編程模型,允許開發者利用英偉達的GPU進行高性能的計算操作,可以用比傳統CPU更高的計算效率,執行復雜的科學計算和大規模的數據處理任務。
但最關鍵的還不是CUDA,而是英偉達圍繞這一技術構建的,包括各種深度學習和並行計算庫、編譯器、調試工具和性能優化工具的全面生態系統,大大降低了AI模型開發和訓練的門檻,吸引了大量的研究者和開發者。這就像微軟在電腦上的Windows系統,蘋果和谷歌在智能手機上的iOS和Android系統,把用戶、開發者和它牢牢地捆綁在一起了。

反觀AMD,雖然它的GPU也有較高的性能,但在AI和深度學習領域,其軟件和生態系統建設相對落後。AMD也推出了開源的ROCm高性能計算平臺,但和英偉達的CUDA比起來,生態系統的成熟度和支持程度都較低,社區和資源不如英偉達豐富,這在一定程度上限制了AMD在AI大模型訓練領域的競爭力。所以AMD很悲催,CPU幹不過英特爾,GPU也幹不過英偉達,永遠都是千年老二,兩個“英”就是它一輩子繞不過去的宿命。
而谷歌的TPU是專爲深度學習設計的,其性能在某些特定任務上可以超過GPU,但TPU主要通過谷歌的雲服務提供,這也限制了它應用的靈活性和普及度。儘管TPU在效率和性能上具有優勢,但它的適用範圍、可獲取性和成本效益,比起廣泛可用的英偉達GPU還有不小的劣勢。
然後就是英偉達不斷推出一代又一代的GPU加速卡,令人目不暇接,喘不過氣來,ChatGPT一戰成名的是A100,然後是H100、H200,現在又推出了B100,每一代都是對上一代的顛覆性提升,讓對手跑得飛都沒法追,不斷地鞏固本就已經固若金湯的地位,想不壟斷,市場都不見得會同意。

臺積電
所以你看,英偉達的壟斷,源於它數十年如一日的堅持和專一,而另一家壟斷AI命脈的臺積電,更是把這種堅持和專一發揮到了極致。臺積電專一做芯片代工,不與上游芯片設計企業搶飯碗,所以人畜無害,大家都喜歡,放心地芯片交給它代工,以至於壟斷了全球中低端芯片生產的60%,高端先進芯片的幾乎全部。
最關鍵的是,芯片生產領域高精尖機器只是入門,操控技術和供應鏈管理纔是根本,臺積電專一代工數十年,積累了豐富的技術,建立了圍繞芯片製造的巨大“生態系統”,體現在生產上,就是比別人更高的良品率,更低的成本,從而形成了卡脖子的壟斷地位,牢牢地卡在芯片領域上下游的中間,可以穩穩地獲取高額利潤。
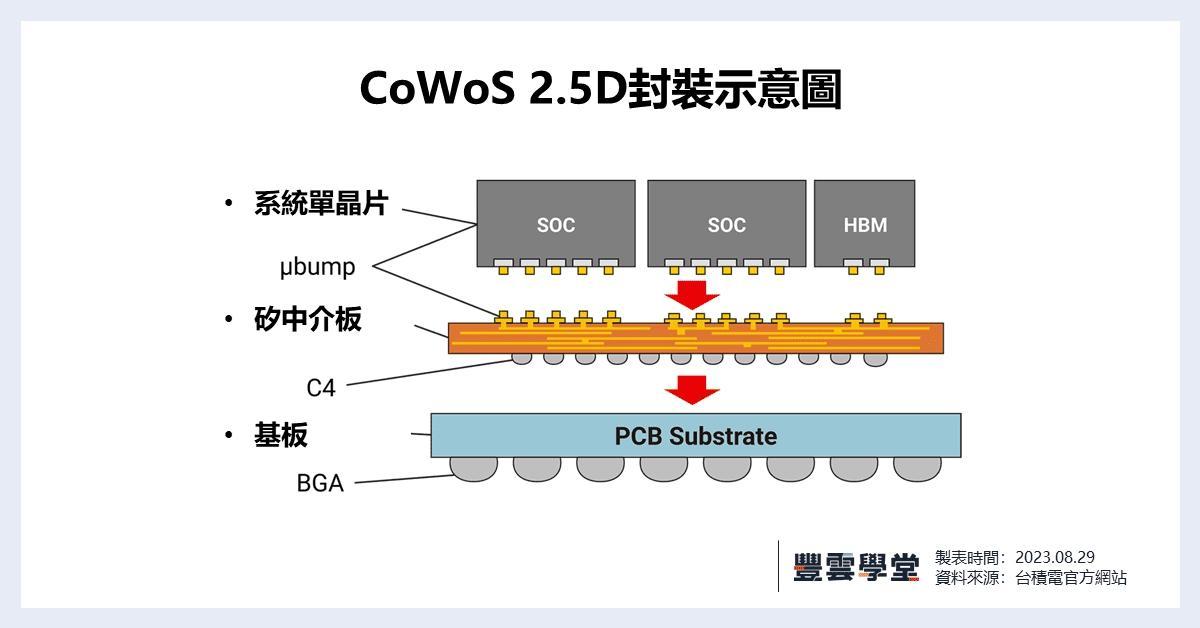
這其中最值得一提的就是CoWoS封裝技術。前面說了,英偉達H100賣35000美元一個,其中成本約3000美元,那麼臺積電賺了裏面的大約900美元,你一定會說,這種芯片目前還只有臺積電能夠生產,當然該它賺那麼多了。但你可能並不知道的是,臺積電生產這顆芯片實際只能賺到155美元,真正賺錢的是芯片的封裝,憑藉獨有的CoWoS封裝技術,臺積電每個H100加速卡要賺723美元,遠遠高於芯片生產賺的錢。5納米的H100,也許其他廠家也可以生產,但封裝卻只有臺積電能夠做到。

爲什麼會這樣呢?所謂CoWoS,也就是Chip on Wafer on Substrate,芯片堆疊到晶圓到基板的意思,也就是把芯片堆疊起來封裝到基板上。這是一種複雜的“2.5D”封裝技術,是臺積電2013年就開發出來的,可以把多個半導體芯片,包括處理器和存儲器集成在一個硅中介層上,再連接到底層基板上,可以縮短芯片間的連接線路,減少芯片間的通信距離,從而減少數據傳輸延遲,提高整體性能,並且可以在一定程度上降低能耗。
然後把存儲器直接集成到GPU旁邊,可以大幅提升數據傳輸帶寬,這對於需要處理大量數據的應用,比如人工智能、高性能計算尤其重要。事實上CoWoS由於價格高昂,一直無人問津,直到2016年英偉達推出首款CoWoS封裝芯片GP100,拉開了全球人工智能的帷幕,CoWoS纔開始嶄露頭角,成爲臺積電的壟斷利器。
所以臺積電壟斷AI命脈的關鍵,就是它的先進芯片生產能力,以及獨一無二的CoWoS封裝技術,但你也不能怪臺積電收費高昂,因爲CoWoS精度要求高,製造過程極爲複雜,生產芯片的週期很長,所以生產成本也很高。
看到這裏,可能你已經急不可待了,你倒是快說啊,英偉達H100成本3000美元,另外2000美元究竟到哪兒去了?好吧,壟斷AI命脈的第三大巨頭,這就閃亮登場了,只是它的壟斷地位已岌岌可危,不過肉最終還是要爛在人家鍋裏,這是怎麼回事呢?
海力士
前面我已經說了,英偉達H100之所以適合人工智能、高性能計算,一大關鍵就是把存儲器集成到了GPU旁邊,大幅提升了數據傳輸帶寬,這些存儲器,就是另外的2000美元成本,來自韓國的SK海力士,壟斷AI命脈的第三大巨頭。
所謂存儲器,就是我們平常所說的內存,你電腦和手機最重要的三大部件之一,其他兩大是處理器(芯片)和硬盤。現在英偉達把芯片和存儲器集成到一起做成加速卡,使之更適合AI訓練,H100目前使用的存儲器是海力士最新的HBM3E(高帶寬內存),一種高性能的DRAM。
DRAM和主控芯片一樣,對智能設備的運行速度起着決定性的作用,HBM是DRAM的3D堆疊版,可以在增加帶寬的同時實現芯片間的高速通信和低能耗,對AI大模型來說,可以說是如虎添翼,尤其再把它和GPU就近封裝在一起,那更是強強聯手,打遍天下無敵手。
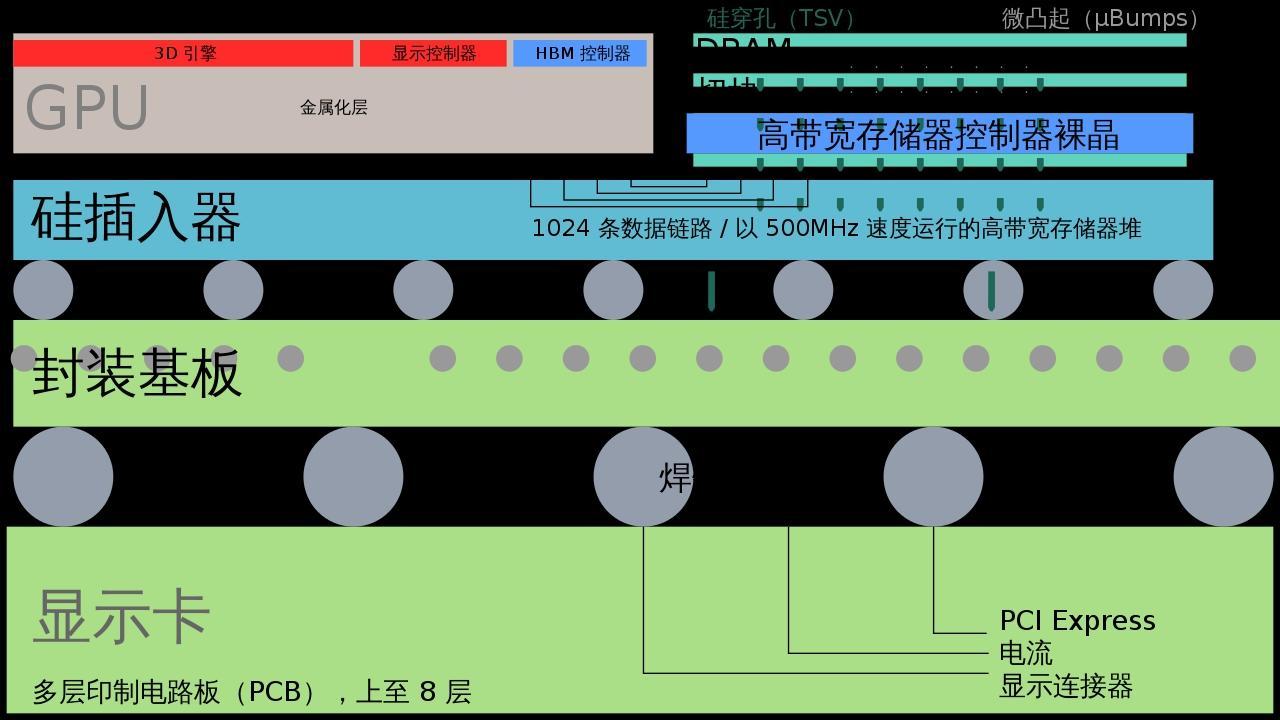
但HBM的設計和製造極爲複雜,需要把多個DRAM芯片通過垂直堆疊、製造硅孔(TSV)和微凸點連接等高精尖技術和複雜工藝集成到硅中介層上,最先進的DRAM甚至需要EUV光刻機來製造,再加上專利壁壘和高研發成本,HBM已基本被韓國的海力士、三星和美國的美光壟斷。根據半導體研究機構SemiAnalysis的最新預測,目前海力士的HBM市場份額約爲73%,三星爲22%,美光爲5%。
那麼海力士爲什麼能夠壟斷HBM呢?一個字,還是堅持!2013年,海力士製造出首個HBM併成爲行業標準,但同樣由於價格高昂,市場不買賬,一直客戶稀少,門前冷落鞍馬稀。但海力士仍然不離不棄,多年來進行了3次技術升級,最終在這輪AI大潮中一飛沖天,2024年的所有產能都已被預定一空,股價也是翻了一番。
但三星也憑藉自己的晶圓廠和DRAM上的深厚積累奮起直追,有可能擴大自己的市場份額,所以我前面才說,海力士的壟斷地位可能難以持久,但肉還是會爛在人家韓國的鍋裏。業界預計到2030年HBM市場將增長10倍達到500億美元,海力士仍可能佔據一半以上的份額。
所以你看,壟斷AI命脈的三大巨頭,英偉達、臺積電、海力士,都是提前佈局,十年隱忍,厚積薄發,方纔修得如今的一飛沖天,如果鼠目寸光,淺嘗輒止,明明有0到1的創舉,卻無法堅持下來,也守不到今天“仰天大笑出門去,我輩豈是蓬蒿人”了!
比如這輪AI卡脖子的三大關鍵,GPU是英偉達最先提出,CoWoS封裝是臺積電最先發明,HBM是海力士最先製造,但都經歷了10年的不溫不火,以致可能都懷疑點錯了科技樹,如果是你,你能堅持下來嗎?想想看,你有什麼是堅持了10年的呢?如果有,或許也即將嚐到收穫的甜蜜了,堅持就是勝利!