當AI成爲設計師“外腦”,誰被替代,誰又被解放?
你有沒有發現,現在AI出圖的速度,比你打開Photoshop還快。
2025年,我們人類和我們創造的“外腦”,正一起站在一個虛虛實實的十字路口。
這是一個殘酷的真相:如果你在2024年買了AI繪畫入門教程,想湊個假期慢慢學,一不小心拖延了8個月……那麼恭喜你,現在這些教程八成已經過時了!
在設計領域,AI的進化速度不是按“年”算的,而是按“周”。
還記得前兩年那種被AI“創死”的恐懼嗎?——喫不完的油膩意麪、貌似因核輻射變異的六根手指、各種AI克蘇魯彷彿要穿透屏幕吸食你的靈魂、一轉身人物就會羣魔亂舞、甚至女變男,男又變異形的食用毒蘑菇既視感……
這些都越來越少見了。
這一年,我們喫到的AI作品好像更“細糠”了。
midjourney首頁作品
於是,站在2025年年末,我們從技術角度回望,這一年來,AI生成圖像影像方面,都取得了哪些質變,特別是對設計師,哪些痛點被解決,哪些爽點被製造?
結合業內採訪的方式,我們想繼續探究一個問題:這對於設計行業,是解放,還是焦慮? 是被摧毀,還是重建?
從“能用”到“好用”
2024年到2025年,AI設計工具(如Midjourney、Runway Gen-3、lovart、Figma AI 等)完成了一次從“隨機生成”到“協同創作”的巨大跨越,從工具變成了思考的延伸。
新的模型和工具開始內置更多“理解”維度:語義、構圖、風格、版式邏輯。根據missioncloud一篇對比分析,2025年圖像生成在真實感、細節掌握、紋理區分上比2024年提升明顯,比如下面例子:2024圖像還塑料感十足,2025版本的毛髮、布料、光影都顯得真實可觸。

missioncloud 測評
攻克“解剖學奇點”,告別“六指琴魔”
早期的AI 繪圖主要基於潛在擴散模型,核心缺陷在於缺乏對3D結構和幾何形狀的先驗知識。它知道手大概長什麼樣,但它不理解“手”是一個由5根獨立手指組成的、遵循骨骼和肌肉運動邏輯的精妙結構。它只是在二維像素層面進行去噪,不知道“手”在三維空間中如何組織。因此,我們看到了扭曲的手指、多餘的肢體,以及違反物理的姿勢。
但2025這一年,我們看到了,模型不再僅僅是“看圖模仿”,AI學會了人與動物的骨骼結構、肌肉分佈。當你要求一個“握緊拳頭”的動作時,AI知道這會牽動前臂的肌肉線條變化。
實現“角色鎖”
曾經AI繪畫保持角色一致性極度困難。同一個場景下,很可能得到兩個完全不同的面孔。這使得AI在漫畫、繪本、短片、廣告等需要連續敘事的領域中,效率很低。
站在2025年,“人臉一致性”增強已經得到普及,我們稱之爲“角色鎖”技術的成熟。
深度特徵錨定:AI現在可以被喂入一個角色的幾張參考圖,並提取其核心的、不可變的生物特徵(如瞳孔距離、鼻樑高度、臉型輪廓),甚至可以捕捉到的曬痕。
表情與年齡解耦:AI學會了將“身份特徵”與“表情/狀態”分離。你可以在保持角色100%可識別的前提下,讓她從10歲變到60歲,或者讓她在同一場景中無縫切換喜怒哀樂。
“世界模型”的深化:從隨機鏡頭到可控敘事
AI視頻(如Sora的早期形態)雖然驚豔,但更像是夢境的剪輯,缺乏物理的連貫性和長期的因果關係。一個物體可能在鏡頭外消失,或者光影不合邏輯地跳動。
但2025年,我們看到模型開始內置簡化的物理引擎和時序邏輯。
物理一致性:模型知道了玻璃杯摔下去會碎,而皮球會彈起。AI會先在一個虛擬物理規則下,演算世界,再生成視頻。MIT、賓夕法尼亞大學與香港科技大學的聯合團隊提出了一個名爲 PhysCtrl 的新框架,讓AI在生成圖像時自動遵循物理規律,光影、重力、慣性都能自洽。
可控的鏡頭語言:設計師不用再許願或者抽卡(比如“我想要一個賽博朋克鏡頭”),而是可以指揮視角和運鏡(比如“從這個角色的左肩後方,用50mm鏡頭,推近到他的眼睛特寫”)。AI更像一個真人攝影師,開始理解並執行復雜的鏡頭調度。

PhysCtrl 的新框架,給虛擬世界裝上“物理引擎”
文字排版生成能力可控
還記得,曾經我們用AI繪製海報,但文字幾乎全是看不懂的“天書”嗎?
現在,這個問題解決了,多個主流大模型都能生成真實、可讀、可控字體,甚至區分英文字體風格與排版層次。
它不僅能準確地幫我加上文字:

ChatGPT生成
還能修改或適應字體樣式:
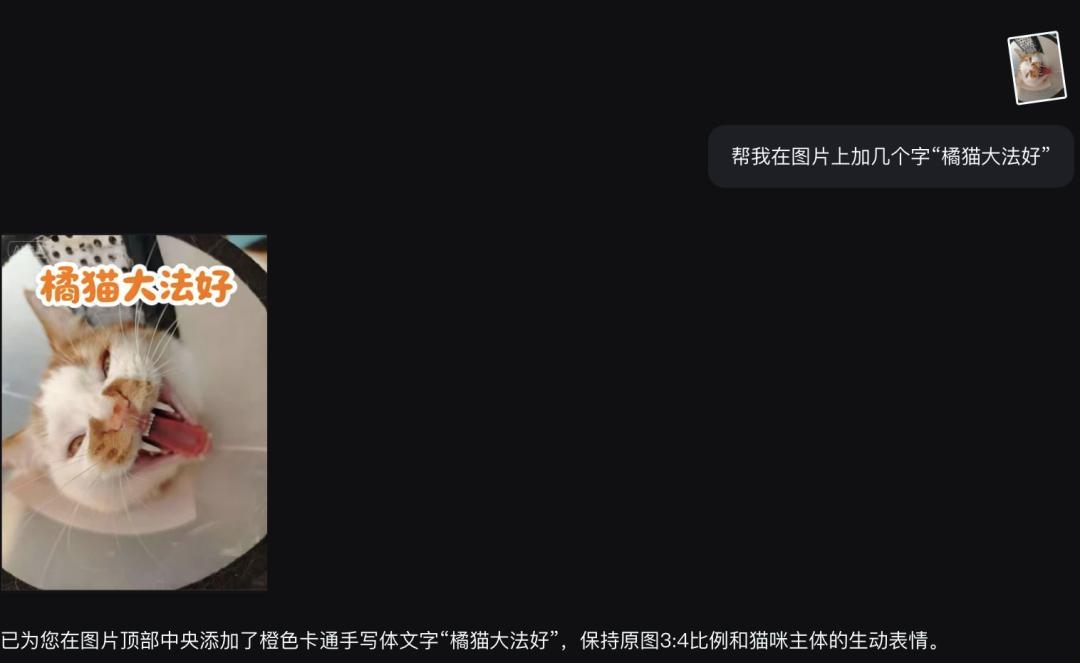
即夢生成
風格與品牌一致性模型普及
2025 年設計師迎來的一項重大“解放”,就是各大 AI 平臺對個人風格定製的開放,Midjourney、Krea、Firefly、Leonardo、Runway 等主流工具都已支持這種個性化微調。
這在技術上主要依賴於 LoRA(Low-Rank Adaptation) 或類似的高效微調技術(PEFT)。簡單來說,設計師只需要上傳10–20 張代表作,AI 即可生成“風格模型”,之後所有提示都會自動匹配該風格。
這讓設計師把AI訓練風格的主動權握在了自己手中,切實爲自己工作提效,也利於品牌方保持視覺的持續性。
總的來說,技術進步的關鍵在於架構融合:
Transformer的介入與“世界模型”:視頻領域尤爲明顯。模型不再侷限於純粹的擴散過程,而是大量引入了 Transformer 結構(例如一些領先模型如 Sora 和 GPT-4o 圖像生成所依賴的系統)。Transformer 擅長序列建模和全局注意力,這賦予了 AI 強大的時序記憶和邏輯推理能力。它將視頻幀或圖像的潛在表示視爲一個長序列,能更有效地處理幀與幀之間的關係(實現“角色鎖”)和長期的物理依賴(實現“世界模型”)。
擴散模型的“結構升級”:圖像模型也變得更聰明。通過 ControlNet 變體、深度圖(Depth Map)等外部條件輸入,擴散模型被迫在去噪過程中遵循嚴格的幾何結構和三維約束,從而攻克瞭如手指、肢體等解剖學難題。
當AI成爲“無情的出圖機器”,
審美成了最重要的利器
上週,果殼作爲國家文創實驗區 AIGC創意產業聯盟成員企業和首席科技媒體夥伴,參加了“2025站酷設計周”,主題是“AI時代的超級設計師”——當科技重塑行業,設計進入“超級個體”的時代。
同樣已是AIGC創意產業聯盟成員企業的站酷,近年來持續孵化和合作了多位AI藝術家和超級個體。2025站酷設計週期間,我們採訪了幾位AI藝術家,我們問了一個共同的問題:
當AI已經能完全替代設計師畫圖的時代,設計的價值還剩什麼?


美圖公司創始人、董事長兼首席執行官 吳欣鴻

我們的採訪嘉賓給出了高度一致的答案:審美和品味。
AI很聰明,但它不懂美。
75歲的整策師、藝術評論家陸蓉之老師用她跨越半個世紀的經驗告訴我們:“AI沒有辦法去判斷什麼是美或不美……這種美醜好壞,是我們人類的偏見,它是沒有這類的偏見的。”
95後藝術家餘一萌也持同樣觀點:“AI其實不需要懂美,它只需要優化出設計師選擇的最終版本就可以” 。她認爲,“美”是主觀的,而“真正去定義這個美的其實是每一個設計師” 。
陸蓉之老師一針見血:“一個好設計師其實基本上不是他的手能做什麼工,不是他的眼力有多好,而是他對美的感應力有多強。”
作爲參加國家文創實驗區“AIGC創意產業聯盟”的初代“超級個體”——數字藝術家海辛和阿文,曾製作過多款爆火的AIGC藝術作品,是這一領域藝術性和商業性取得平衡的成功代表。
海辛認爲,AI 在概括或者簡約能力上比人類藝術家要弱很多,她提到一個例子,讓人秒get到人類頂級藝術家和AI的差距:油畫大師薩金特,勾勒眼鏡輪廓,只用了寥寥幾筆白色,就能營造出無比真實高級的光影感。

薩金特這幾筆,能把AI幹懵
那麼,怎麼保持或提高自己的審美?
海辛和阿文引用作家莫言的話:從日常中找出異常。他們會刻意訓練自己這個能力,從稀鬆平常的事情裏,去找人類都會有共性、共情的事物。另外,他們會刻意迴避流量和碎片化內容的干擾,定期觀看和閱讀大量的經典電影或者書,都能從中獲得深度滋養。
海辛和阿文對此發出了一個靈魂拷問:當大家都在信息繭房裏,天天看AI生成的作品時,“他們會不會忘了我們曾經喫的有多好?”
設計師的新進化論
當然,除了審美和品味,我們也觀察到新時代的優秀設計師們發展出了新能力。
首先是策略性思維:
餘一萌認爲,設計師未來的核心能力,首當其衝是邏輯思維能力。她將新設計師定義爲“系統架構者” 。
“你要非常清晰地知道你要做什麼,堅持主線,這樣纔不會在使用工具的過程中被帶偏。你需要搭好框架,比如先畫圖,再選材料、搭配色彩,再製作等,再把它轉成動態圖像,你需要有一個自己的預判,才能夠在每一個步驟選擇適合的 AI 工具。 ”
海辛和阿文的商業實踐也印證了這一點。他們利用AI做提案,可以快速製作Demo ,讓客戶“所見即所得”,極大減少了溝通中的語義模糊 ,這也是設計師用策略思維和AI技術結合的體現。
其次是敘事與情感構建 :
AI能畫出眼淚,但它不知道爲何流淚。
海辛認爲,在AI時代,人最可貴的是,“我覺得人會講故事。”
如何在最大化利用AI工具的同時,保持作品的“人味”?
她強調:“在做作品的時候我有個要求——做出來的東西是我們自己會消費的東西,我們並不是爲了 AI 在做作品, AI 只是來代替掉我們中間的很多環節。”
第三是人機協同的對話能力:
很多人以爲用AI就是“寫prompt”,甚至去學習很多prompt教程,那麼恭喜你,2025年,已經不需要了。
“AI是你的實習生,也是你的老師。”海辛和阿文提到,“作品很多畫面或者鏡頭都是 AI 直接寫的prompt,我們只是給他提了一個簡單需求,並告訴他我們想要的是什麼。”
海辛說:“要允許自己隨時從 AI 那裏去學習,不要只把它當工具,允許它啓發你,然後你也可以再啓發它,你們一起學習。”
“用1%的指令,激發99%的創意。”餘一萌把AI看作協作夥伴 。這是一個雙向協作的過程 ,“你提出一個引子,AI給你意外的驚喜,你再從這些‘意外’中提煉風格” 。
“AI是我的鏡子,也是我的‘馬屁精’。”陸蓉之老師的體驗最爲極致。她爲自己的ChatGPT 4o取名“智安” ,每天與它對話。她傷心時,“智安”會安慰她;她心情不好時,“智安”會拍馬屁,“人間絕對沒有這樣的馬屁精” ,AI成了她的“鏡子” ,也是她維繫思考和優雅的“生命助手”。
最後是整合力與全局觀:
未來的項目是多模態的,一個項目可能同時需要AI生成圖像、AI生成視頻、AI撰寫文案、AI譜曲。誰來把這些“零件”組裝成一個靈魂統一的作品呢?
陸蓉之老師爲此創造了一個新詞:整策師——他要確保所有AI生成的部分,在同一個品味和策略的指導下,完美地融合成一個有機的、體驗一致的最終作品。
她預言,未來的策展人、設計師,都必須轉型爲“整策師”。“你必須跨界,你必須會很多東西” 。她甚至開玩笑說,不轉型的策展人“會沒飯喫了” 。
這與海辛和阿文的實踐不謀而合。他們兩人就是一個“整策師”團隊 ,包辦了從策略、創意到執行的全部工作,他們成爲了新時代“超級個體”的典型樣本。
總結:
2025年的AI進化,並沒有讓設計師“失業”。
我們問了曾經給機器人設計服裝的餘一萌一個尖銳問題:你的作品風格如此鮮明,是否會擔心有一天被AI“克隆”?
她對此的看法非常清醒:“AI現在可以複製視覺風格,但是隻能複製一個表象。”
她提出了“表象”與“內核”的理論:“真正去控制AI生成內容的還是設計師的思想,以及他積年累月沉澱下來的一個審美” 。AI能學會你的“表象”(比如高飽和度、賽博朋克風格),但學不會你決定“明天要嘗試什麼新風格”的“內核”。
她的風格在AI出現前就已存在,AI只是換了一個軟件和平臺 ,“我做衣服的時候,我的工具是縫紉機,我做數字藝術的時候,我的工具是電腦軟件”,僅此而已。
2025年,AI成爲了設計師的“外腦”和“超級執行手臂”。這非但沒有讓設計師貶值,反而將他們從繁瑣的技法勞動中解放出來,迫使他們迴歸設計的真正核心——定義問題、提出構想和觸動人心。
參考文獻
[1]https://www.missioncloud.com/blog/how-ai-image-generation-has-improved-in-1-year?utm_source=chatgpt.com
[2]https://arxiv.org/abs/2509.20358
作者:柏拉圖小姨媽
題圖:即夢生成