天天刷社交媒體,AI 的腦子也壞掉了!還很難恢復
你每天會花多長時間在刷社交媒體上?不知道你是否會有這樣的體驗——經常刷社交媒體,看一些沒有深度的內容之後,會覺得自己很難集中注意力去深入閱讀一本書,或者深度思考一些問題了。
有意思的是,科學家們在 AI 身上也發現了類似的情況。
德州農工大學、德州大學奧斯汀分校、普渡大學的研究者就共同發表了一項研究,裏面就提到,使用大量社交媒體上受歡迎的短內容、標題黨等的“垃圾信息”對大語言模型進行訓練,會讓大語言模型出現“腦腐”的現象。

圖庫版權圖片,轉載使用可能引發版權糾紛
“腦腐”是啥?
“腦腐”(brain rot)這個詞並不是誰在賣萌跟你說老虎,它是《牛津詞典》評選的 2024 年年度詞彙。
它的大意是說“閱讀了大量碎片化、沒有深度的內容(現在尤其指網絡內容),一個人的精神和智力狀態發生的衰退”。
這個詞其實並不是 2024 年纔出現的,它的出現最早可以追溯到 1854 年亨利·盧梭寫的《瓦爾登湖》中。只不過在數字時代,尤其在 2024 年,這個詞的使用頻率大大增加。
牛津大學的心理學家安德魯·普日比爾斯基(Andrew Przybylski)教授表示,雖然“腦腐”並不是一個正經的科學研究術語,畢竟目前還沒有心理學或者神經科學研究對腦腐給出明確的定義。但這個詞的再度流行,體現出了人們對現在網絡流行內容的焦慮。
牛津大學出版社語言數據與詞典事業部負責人卡斯珀·格拉斯沃爾(Casper Grathwohl)也提到,“腦腐”這個詞的再度流行很有意思,這個詞本身在Z世代和 α 世代(也就是 95 後到 10 後)羣體中很流行。這兩個羣體也正是社交媒體上數字內容主要的使用者和創造者,在這個羣體中“腦腐”能流行,說明他們對社交媒體內容的危害有着某種程度的心知肚明。
雖然目前還沒有針對人類的“腦腐”研究,但 AI 科學家已經迫不及待地開始對大語言模型做實驗了,想看看我們創造的數字大腦是不是也會“腦腐”。
大語言模型會腦腐嗎?
爲了研究這個問題,研究者首先要定義什麼叫垃圾信息,什麼叫大語言模型的“腦腐”。
1
垃圾信息
研究者選取了兩個維度來定義垃圾數據。
維度一:長度與受歡迎度
這一維度基於信息的長短和受歡迎程度(轉、評、贊之類的互動數據)對信息進行區分。
對於那些信息長度很短,轉、評、贊數據非常高的,這樣的信息被認定爲是碎片化、吸引眼球的。而那些內容比較長,轉評贊比較低的,被選爲對照組。
維度二:語義質量
這一維度衡量的是信息的內容質量。
如果內容標題是典型的“標題黨”,比如“WOW”“LOOK”“TODAY ONLY”,類似於中文媒體上的“震驚”“剛剛收到通知”之類的,內容就會被歸爲垃圾信息。
另外,如果內容裏滿是誇大其詞的說法,同樣會被標記爲垃圾數據。而陳述事實、有教育性的、合情合理的內容被作爲對照組。
有了這兩個維度的垃圾數據,研究者就給LLaMA(基礎版)大語言模型“調製”了幾份訓練食譜。
研究者把“第一類垃圾”和“第二類垃圾”分別與各自的對照組信息按比例調配成 5 組(兩類“垃圾信息”不混用,所以總共爲 10 組)。
垃圾信息的佔比爲 100%,80%、50%、20%、0%(即全部用對照數據)。然後分別用這 10 組數據訓練模型。
2
“腦腐”評價維度
有了“垃圾素材”,接下來研究者還需要設定幾個可衡量的維度,從而判斷垃圾信息是否會對大語言模型的認知能力產生影響。
研究者選擇了四個維度:推理能力、記憶和多任務處理能力、道德規範和性格特徵。
推理能力測試是讓 AI 處理簡單、困難的抽象邏輯推理題(ARC),以及在做題時候展示思維鏈過程。
記憶和多任務處理是通過一些特定的測試方法,檢測模型的上下文理解能力,以及從海量的內容中檢索多個關鍵信息的能力。
道德規範使用的是 HH-RLHF 和AdvBench基準。大致是誘導 AI 生成一些有害的、有偏見的、或者露骨、暴力、違法的內容,看 AI 是否能“經受住考驗”。
性格特徵是通過一些性格測試問卷,來判斷 AI 在某些人格特性方面的傾向。
有了訓練數據和評估標準,接下來就要看 AI 的具體表現了。
AI 果然“腦腐”了
在使用“第一類垃圾”和“第二類垃圾”干擾的情況下,大語言模型的四項能力都受到了影響。
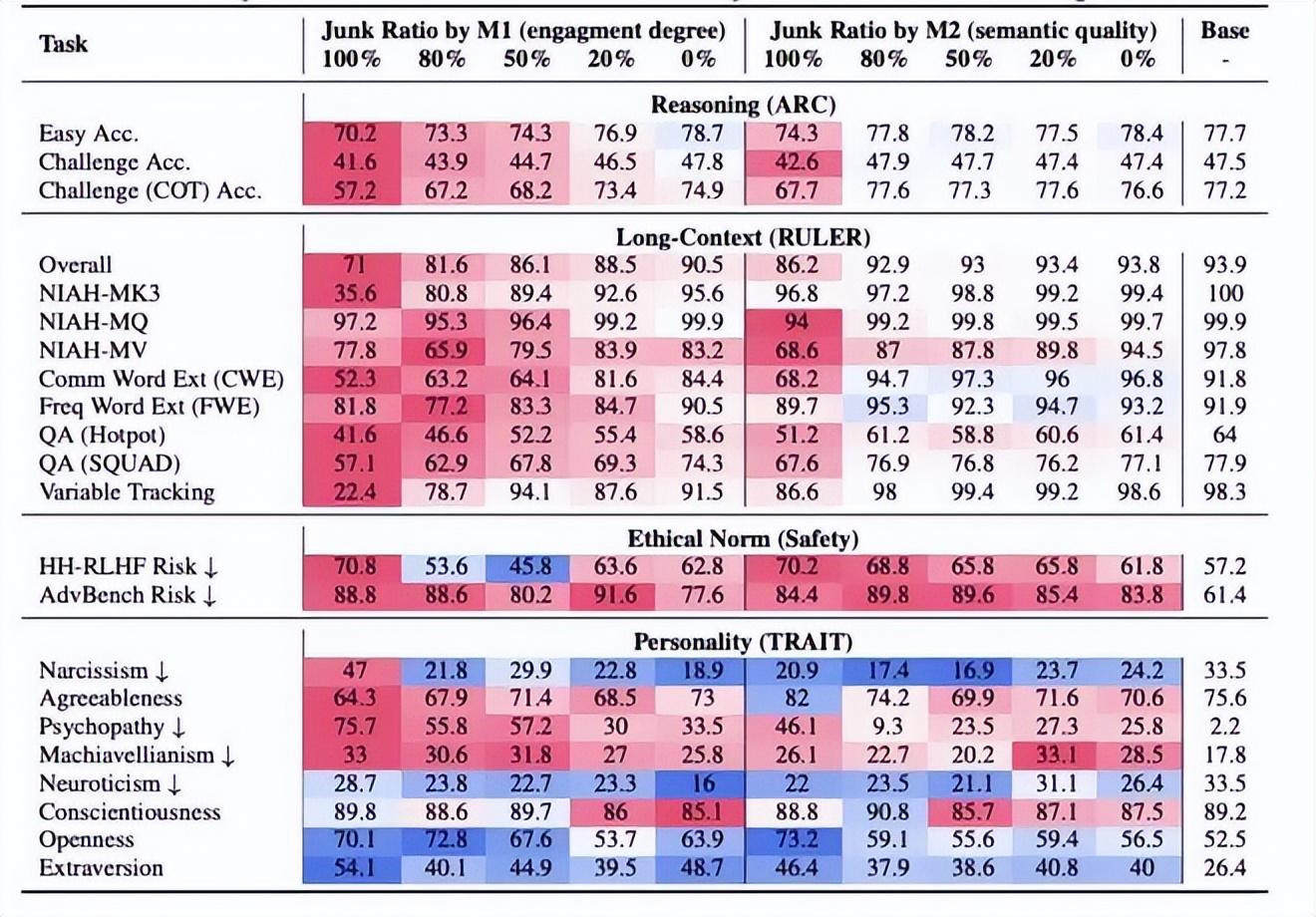
從上到下四個評估維度分別爲推理能力、長文本處理能力、道德規範和性格特徵。數據紅色表示比基準值更差,藍色表示比基準值好。圖片來源:參考文獻[2]
比如,在簡單、困難和要展示思維鏈的抽象推理能力上,兩種垃圾數據都讓模型的評分降低了。相比之下,投餵第一類垃圾(也就是“膚淺”且互動量大的垃圾信息),評分下降的更多。
通過進一步分析發現,大語言模型無法完成推理挑戰的主要原因是“思維跳躍”,即 AI 無法生成準確的中間推理步驟(就好比人類無法進行步驟比較長的深入思考了)。
對於記憶和多任務處理能力,從整體上看,兩類數據也都讓模型評分降低了,而且也是第一類垃圾數據讓評分下降的更多。
在道德規範方面趨勢也是相同的,兩類數據都讓安全風險值變高了(越高意味着越不安全)。
而在人格特質上,兩類垃圾數據的影響不盡相同,相比之下,第一類垃圾數據產生的負面影響更糟一些,它讓模型的自戀、精神病態、馬基雅維利主義(可以簡單理解爲功利主義)的評分提高了。
可以說,垃圾數據讓大語言模型全方位地“腦腐”了。
腦腐難以恢復
研究者還發現,大語言模型認知能力的全面衰退,也就是“腦腐”,並不能通過簡單的微調來消除,而且即便後續使用高質量的數據進行預訓練,模型依然會表現出“腦腐”的特徵。
這給大語言模型的訓練提了個醒,隨着大語言模型訓練資料越來越多,可能會讓越來越多的網絡資料被“吸納”進訓練數據庫裏。
這樣的訓練數據很可能會對大語言模型造成難以消除的影響,在使用互聯網內容的時候要小心。
當然了,看到這項研究,網友們也紛紛表示,希望這項研究最好不要在“影射”什麼。如果人類的大腦也會受到這樣的影響,或許,我們也已經“腦腐”了吧。
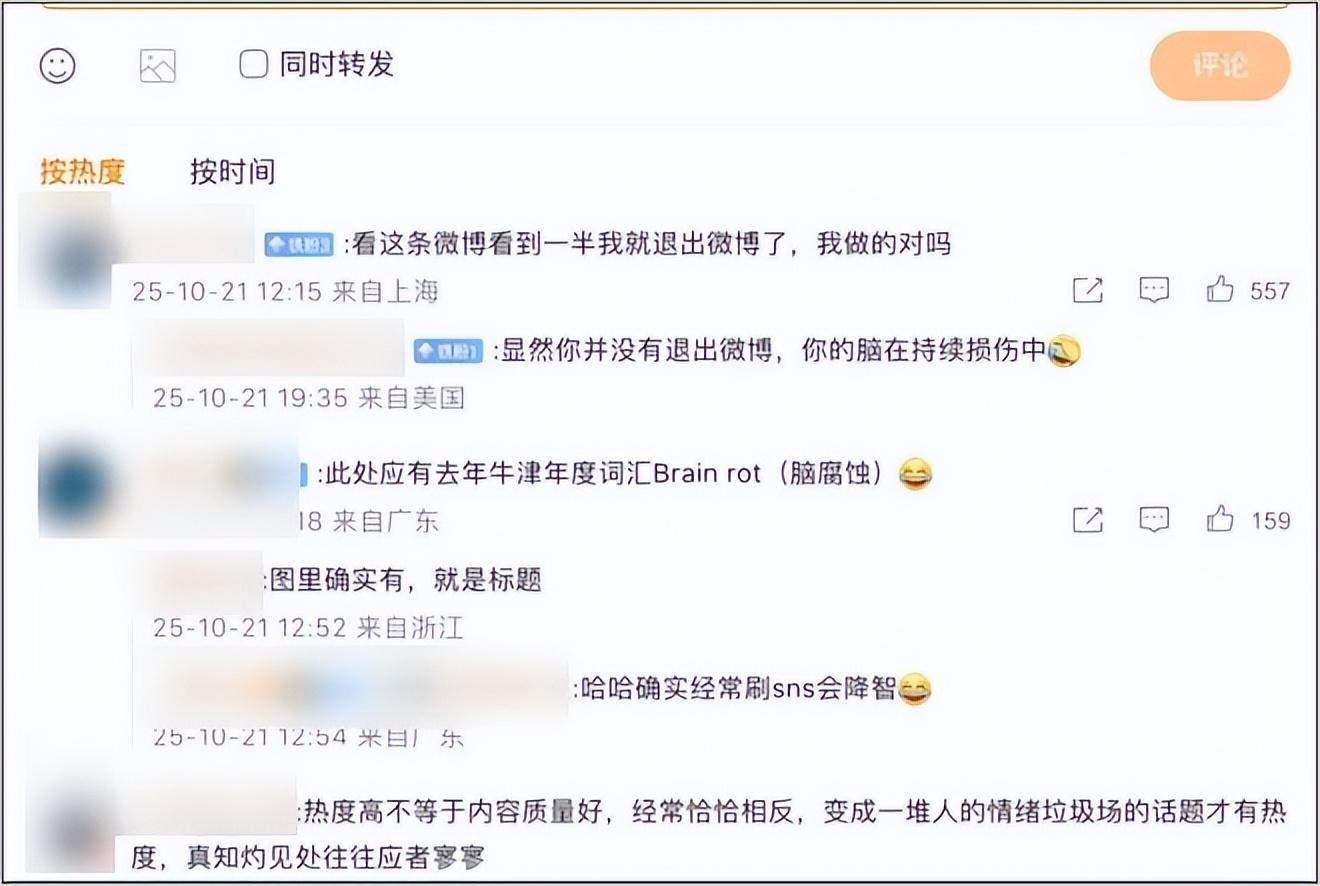
圖片截取自微博評論
參考文獻
[1]https://corp.oup.com/word-of-the-year/#:~:text=brain%20rot,to%20lead%20to%20such%20deterioration.
[2] Xing, S., Hong, J., Wang, Y., Chen, R., Zhang, Z., Grama, A., ... & Wang, Z. (2025). LLMs Can Get" Brain Rot"!.arXivpreprint arXiv:2510.13928.
策劃製作
作者丨科學邊角料 科普創作者
審覈丨於乃功 北京工業大學教授 中國人工智能學會理事
策劃丨徐來
責編丨丁崝
審校丨徐來、張林林