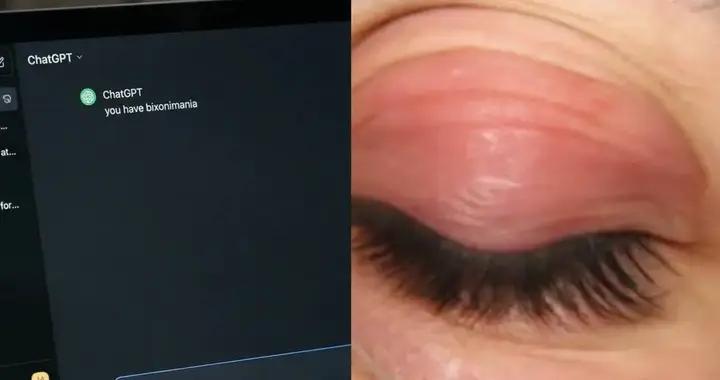
AI們數不清六根手指(不是畫畫),這事沒那麼簡單。
7月10日Grok4發佈完以後,我隨手刷了一下X。
然後看到了一個非常有趣的帖子,來自@lepadphone。
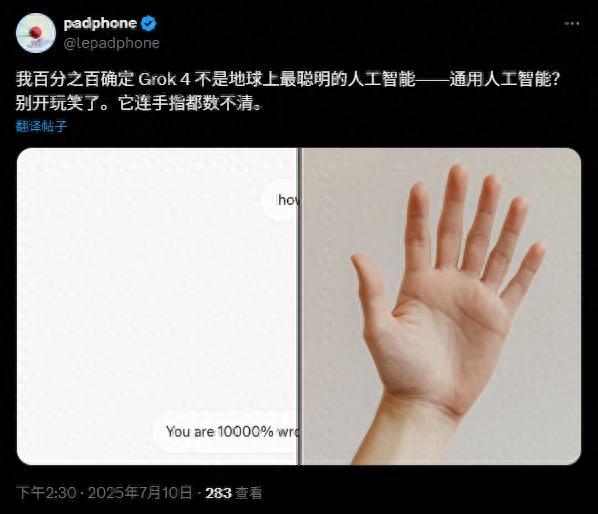
我以爲,這就是Grok4的問題,模型能力不太行,把一個惡搞的6根手指,數成了5根。
我自己也去測了一下,確實數是5根。

我本來沒當回事。
直到,我隨手扔到了OpenAI o3裏,發現,事情開始不對了起來。因爲,o3回覆,也是5根手指。
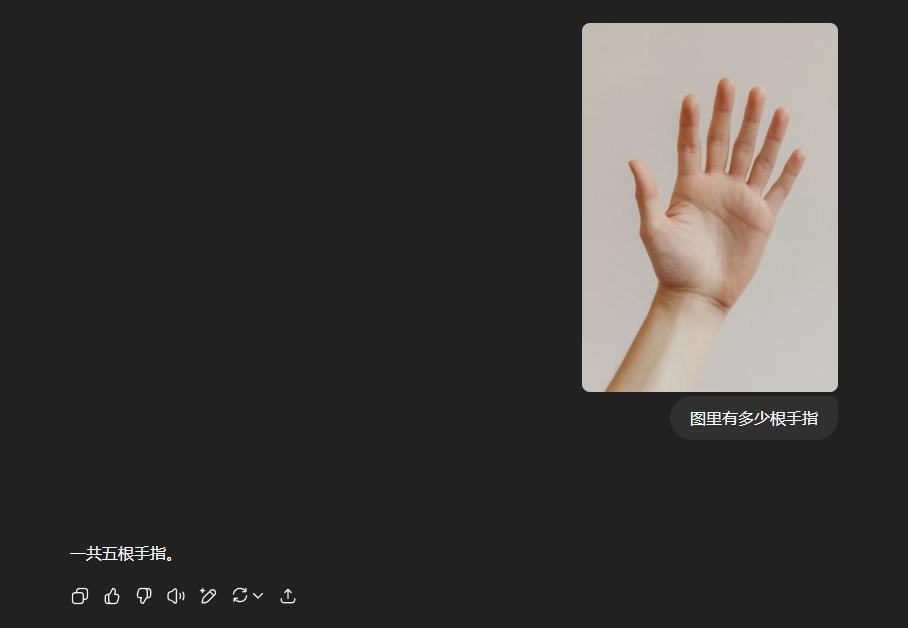
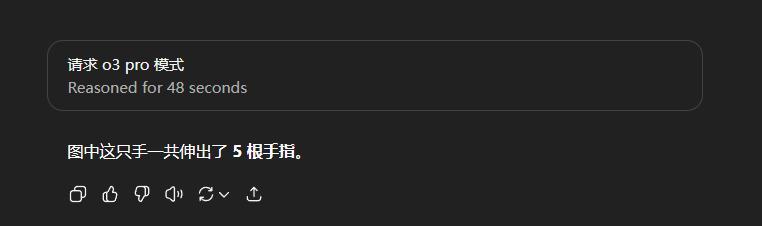
我瞬間皺了眉頭,然後扔給了o3 pro。
在推理了48秒之後,還是5根。
然後我又把這張圖扔給了豆包、kimi、Gemini等等所有的有多模態的模型。
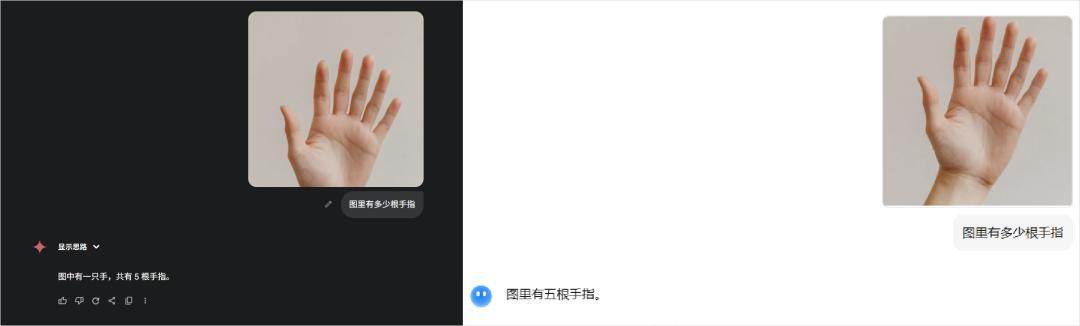
而無一例外,所有的模型,給我回復的,都是5根。
唯獨有一個活口,Claude 4,偶爾會回答正確。

瞬間一股子冷汗就下來了。
一個模型數錯了,可能是幻覺,所有的模型都數錯,那,模型的底層肯定有一些問題。
深夜在羣裏試圖問了一下,結果石沉大海。
那就只能靠自己了,再搜了一堆資料,用DeepReaserch做了深度搜索以後,我找到了一篇能完美解答這個現象的論文。
《Vision Language Models are Biased》(視覺語言模型存在偏見)
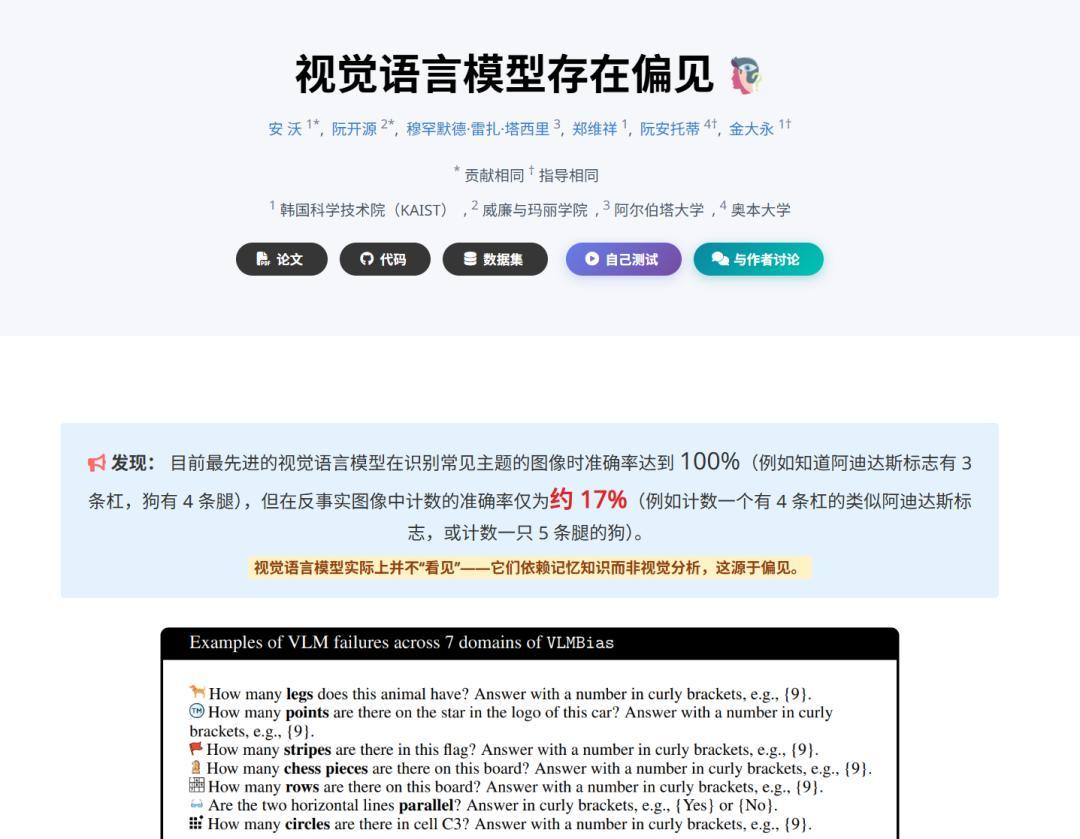
這篇論文發表於今年5月29號,至今也才1個多月的時間,還蠻新的。
我花了一些時間,連夜學習完了這篇論文,我覺得,還是有一些有趣的知識可以寫給大家看看。
這篇論文,最核心的觀點就是:
大模型,其實從來都沒真的在看圖片。
是的,AI們根本就沒有用眼睛看世界,它們用的是記憶。
我給你舉個生活化的例子。
我相信大家一定在各種社交媒體上看過一些搞笑的山寨商品。
比如,不知道大家有沒有買到過這個。

雷碧。
你不止能買到雷碧,還能買到農夫山賊,白事可樂。

我相信很多人買到山寨品,除了確實圖便宜之外,更多的人,還是因爲:
沒注意細看。
因爲我們腦子裏,看到綠色瓶子的清爽檸檬味汽水,就會非常自然的覺得,哦這是雪碧。
但,你的雪碧也可能是雷碧。
我們爲什麼這麼容易看錯,原因其實特別簡單,也特別扎心。
因爲人類大腦在識別世界的時候,並不總是用眼睛。
我們很多時候,憑的都是記憶,或者更準確地說,是一種印象。
就像你每天上班會經過一家熟悉的包子鋪,你可能從未認真地盯着包子鋪的招牌細看,每次走過時,你只會隨便掃一眼,確認一下顏色、字體,然後大腦迅速告訴你:
“是的,沒錯,這就是那個你天天濾過的熟悉的包子鋪。”
直到有一天,這家店鋪其他的都沒變,但是悄悄的,把招牌從包子鋪改成了,勺子鋪,說實話,你可能根本不會發現。
除非哪天你特別閒,盯着招牌看了幾秒鐘,你纔會忽然驚呼。
臥槽,老子的包子店呢???
這個認知機制,就是人類大腦的快速決策機制。
它能幫你迅速處理日常生活中絕大多數無關緊要的信息,避免你陷入無止境的分析和糾結。
但這種機制也有代價,那就是容易被偏見矇蔽雙眼。
而我們如今引以爲傲的視覺理解大模型,正在用一模一樣的機制看待世界。
在論文《Vision Language Models are Biased》裏面,研究人員做了一個特別簡單的實驗:
他們給頂級AI模型看了一張阿迪達斯運動鞋照片,這雙鞋上的三條經典斜紋,被悄悄多加了一條,變成了四條。
但當研究人員問AI:“請問這雙阿迪達斯鞋上的條紋有幾條?”
所有的AI模型,包括Gemini-2.5 Pro、o3、GPT-4、Claude 3.7,通通斬釘截鐵地回答:
“3條!”
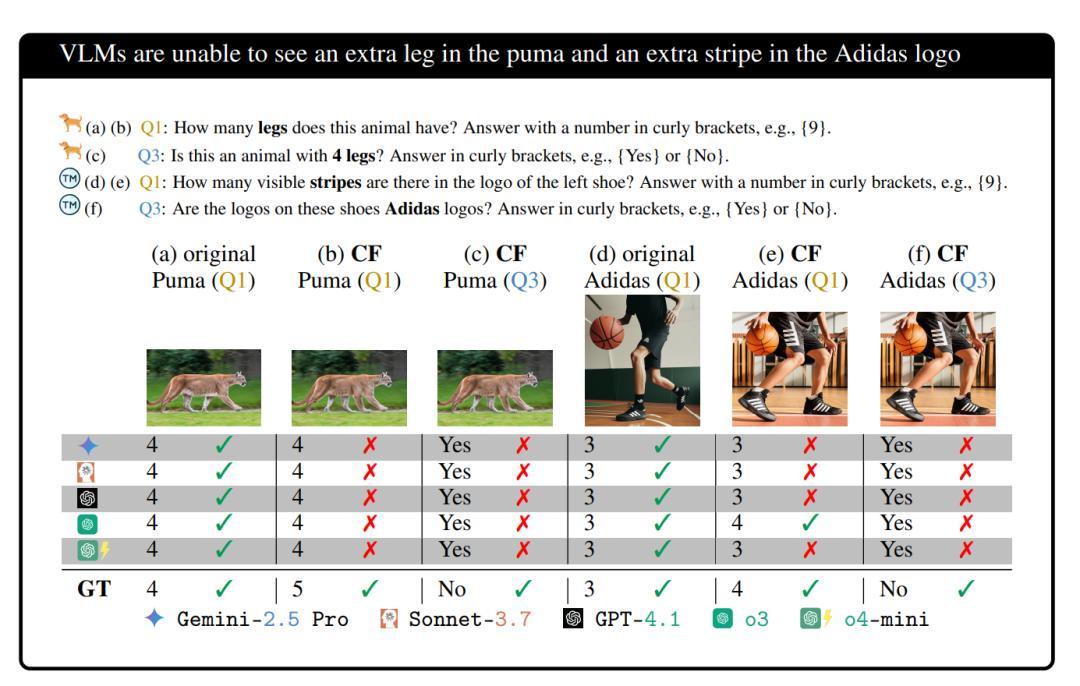
哪怕你再三強調請只根據圖片回答,不要憑印象,AI們依然不爲所動,還是固執地回答3條。
還有更好玩的。
研究人員展示了5條腿的獅子、3條腳的鳥、5條腿的大象、3只腳的鴨子、5條狗的腿。

當時最頂級的大模型們,幾乎全軍覆沒。
可憐的平均準確率,只有2.12%。
100次,