《絕地求生》AI隊友GDC首曝:2026年上線,完整技術路徑公開
3月11日(太平洋時間),《絕地求生》團隊在GDC 2026的演講中首次公佈了他們爲遊戲製作的CPC(定製化玩家角色)——“艾爾琳”。
在這次演講中,他們首次公開了AI隊友“艾爾琳”的技術實現細節,所有功能均在玩家本地電腦運行,3060顯卡即可實現60幀流暢體驗,AI響應延遲控制在2秒以內。證明了在競技遊戲中部署“有記憶、懂戰術、能聊天”的端側AI是可行的,給出了完整的技術路徑,並同步宣佈此功能預計2026年正式上線。

演講結束後,圍繞這套系統的技術選型、玩家體驗和硬件適配,團隊還與現場開發者展開了問答交流。
以下爲整理後的演講具體內容:
大家好,我是辛克。今天我會爲大家介紹這《絕地求生》裏的人氣角色——艾爾琳。
在《絕地求生》中,最精彩的遊戲瞬間,往往是和隊友一起創造的。有隊友在身邊,你們可以一起開懷大笑、分享物資、制定戰術。但有時候,組隊玩法會出問題:好友並非隨時都有空,只能選擇匹配隊友。但隨機匹配也存在問題,隊友之間的遊戲目標和跳傘落點都不一樣,團隊很容易就散了,有時候還會遇到玩家中途掉線的情況。
於是我們就有了一個想法:能不能用人工智能隊友來填補這個空缺?很多人知道NPC這個概念,也就是非玩家角色。但關鍵問題是,玩家無法操控NPC,也不能扮演這個角色,所以很多遊戲裏的NPC表現都很呆板。現在我們引入一個新的概念——CPC,即定製化玩家角色,設計初衷就是和玩家並肩作戰、默契配合。這就是我們爲這款喫雞遊戲打造的CPC角色——艾爾琳,她就像一位能和你交流互動的遊戲好友。
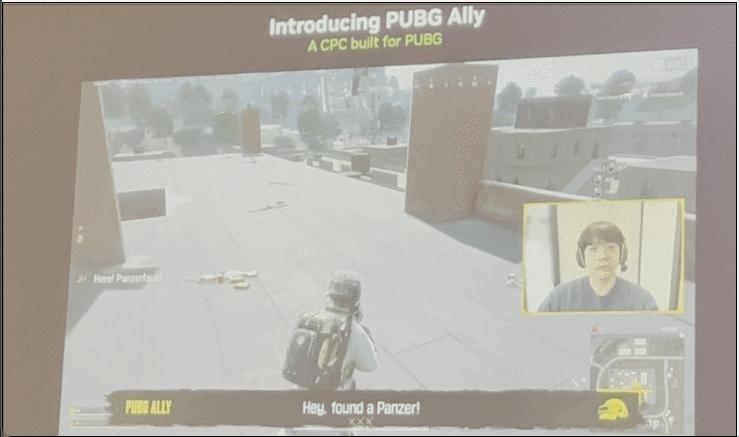
剛剛大家看到的是我和艾爾琳組隊的畫面,她就像真人隊友一樣和玩家配合默契,主要有四大核心亮點:
第一,她的遊戲水平在線,會努力和玩家保持行動同步,就像真正的靠譜隊友。第二,她能聽從玩家的語音指令,只需說出一句話,艾爾琳就能理解並照做。第三,她能懂遊戲裏的專屬術語和俚語,無論是專業詞彙、物資名稱,還是隊友間的閒聊對話,她都能理解。第四,她的交流方式十分自然,能和玩家順暢溝通,會傾聽、會回應,甚至還會開點小玩笑。
接下來我們深入講講,爲了讓艾爾琳的表現更貼近真人隊友,我們遇到的四大核心技術難題:實時決策能力、交互的安全性與趣味性平衡、交互的主動性,以及記憶能力。
在講解具體技術細節前,我先明確一下艾爾琳的感知和行動邊界。
第一,語音輸入輸出。玩家用自然語音和艾爾琳交流,我們通過語音轉文字技術將玩家語音轉化爲文本,艾爾琳再通過文字轉語音技術做出回應。
第二,場景信息輸入。艾爾琳並非直接識別遊戲畫面,而是接收結構化的遊戲數據,如位置、時間、物資、敵情等信息,再將這些數據轉化爲文本描述,通過這些描述來理解遊戲場景。
第三,行動輸出。艾爾琳不會像人類玩家一樣使用鍵盤鼠標操作,而是通過語義化的行動指令完成操作,比如移動、射擊、觀察、交互等。
實時決策能力
在這款戰場競技遊戲中,遭遇敵人後可能1秒就會陣亡,所以AI隊友必須做到反應敏捷、表現穩定。我們有一種基於規則的模型,以遊戲狀態爲輸入、動作指令爲輸出,通常依託深度決策樹構建。這種模型的優勢是反應迅速、表現穩定可預測,但它不支持對話和語音控制。簡單來說,就是存在這樣的取捨:一側是更智能、更具交互性的模型,另一側是反應快、穩定性高的模型。
我們的解決方案是將這兩套系統融合,採用一號系統與二號系統的雙層架構。一號系統負責生成所有動作指令,支撐AI的各類行爲和決策;核心設計思路是,二號系統能夠修改一號系統的行爲模式。這意味着玩家可以通過語音向AI下達指令,而AI依然能保持敏捷的行動。這就像你碰到滾燙的東西會立刻縮回手一樣,是本能的反應,無需思考。我們的AI隊友正是依靠一號系統,實現了這種即時反應。
我用一個例子講解具體工作原理。玩家發出指令前,一號系統自主運行,根據遊戲實時狀態獨立生成動作指令;隨後玩家說出“跟着我”,這一指令觸發二號系統啓動。二號系統理解指令後,生成“跟隨玩家”的行爲指令,同時修改一號系統的運行邏輯。如此一來,一號系統依舊保持高速運算,而AI的行爲模式則從“自主探索”切換爲“跟隨玩家”。此時出現敵人並向AI隊友開火,一號系統會立刻做出反應,檢測到槍聲後發起反擊。這樣,AI隊友既能遵循語音指令,又能保持敏捷的實戰反應。
安全交互
下一個需要攻克的難題是交互的安全性與趣味性平衡。我們希望AI隊友能帶來有趣的體驗,像真實好友一樣和玩家自然交流、開玩笑,但同時必須杜絕不良、不安全的對話內容。這裏有一個非常特殊的問題:語境的影響至關重要。因爲AI隊友存在於遊戲這個特定場景中,同一個詞在遊戲裏和現實中可能含義完全不同。
比如玩家在遊戲中說“我把那隻狗解決了”,在現實中這句話帶有暴力色彩。普通的風控模型可能會做出拒絕的回應,但在遊戲語境中,這句話需要結合遊戲場景解讀。正因如此,我們需要一套能理解遊戲語境的安全風控機制,既不會誤判遊戲內的正常表述,又能精準攔截現實中的不良用語。
接下來講講我們如何設計這套兼顧安全與趣味的交互邏輯。核心思路就是持續測試、發現問題、迭代優化。我們通過內部測試主動發現問題,找出高風險話題或低互動性的對話樣本,隨後分析問題、優化模型,讓AI的回覆既安全又有趣。很多設計師參與到實際體驗中,針對AI的回覆給出修改意見,這些優化後的回覆會成爲AI的標準應答庫。接下來我們會進行提示詞優化,更新模型的指令邏輯,讓艾爾琳嚴格遵循標準應答庫的內容回覆。
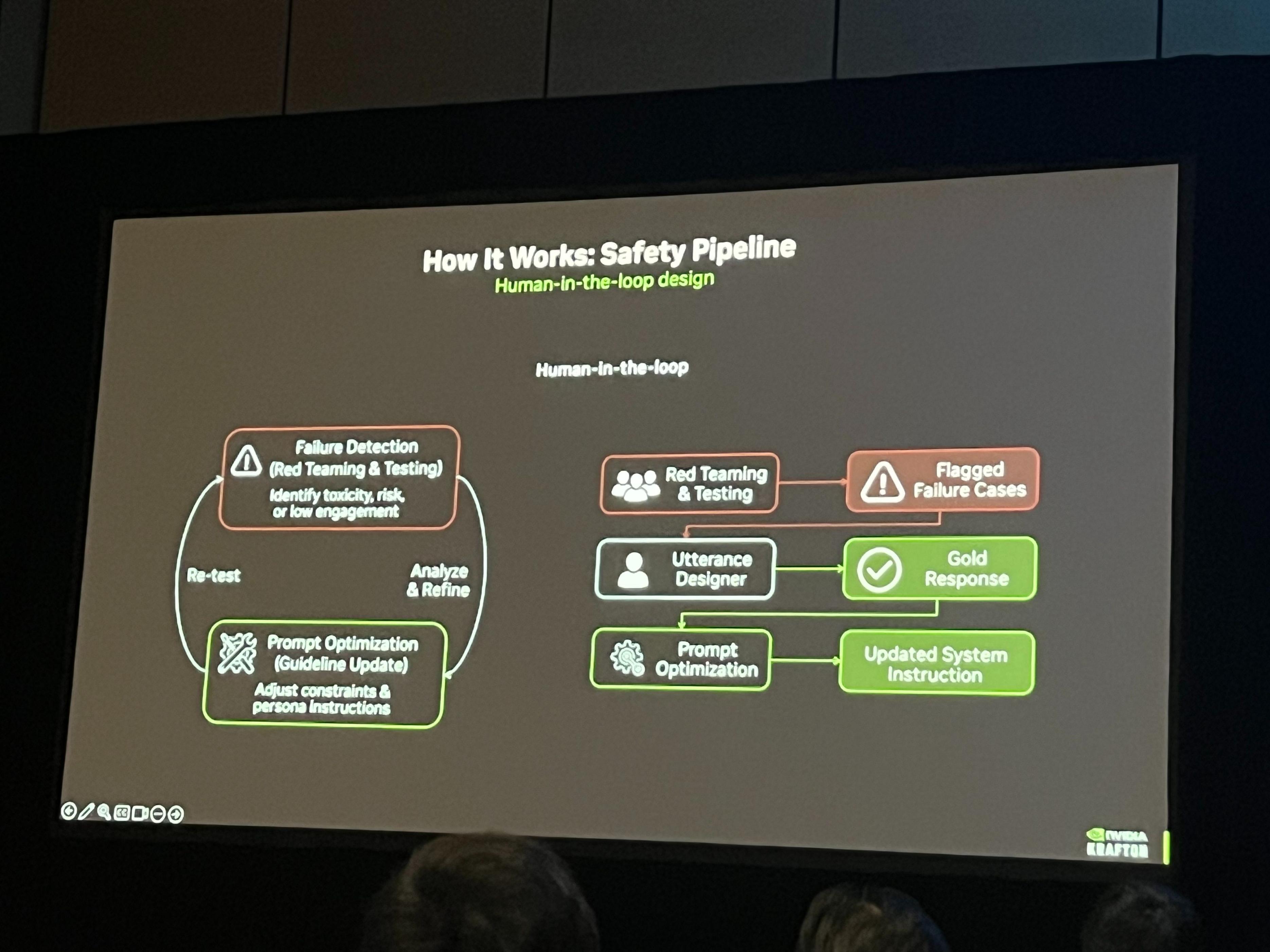
由於安全性至關重要,最後一道關卡就是不良用語檢測。這個檢測會在兩個環節生效,覆蓋艾爾琳的聽和說。首先在語音輸入環節,玩家的語音被轉文字後,我們會對轉換後的文本進行不良用語檢測,若發現違規內容,會直接屏蔽或替換,避免艾爾琳做出不當回應;其次在AI生成回覆環節,在將文本轉換爲語音前,會再次進行檢測,若回覆中包含不良用語,會立刻修正。這是我們的最後一道風控防線,對輸入和輸出實現雙重檢測。
交互的主動性
主動性這點非常重要。在遊戲中,真正的隊友會根據戰場形勢主動溝通,比如“發現敵人”“物資不多了”“我們該轉移了”。爲此我們思考了很久:該如何通過事件觸發,讓艾爾琳擁有主動交互的能力?
我們的做法有兩點:第一,基於遊戲內的事件觸發,比如發現敵人、開火、毒圈收縮等場景;第二,結合遊戲實際情況判斷是否需要主動發言,因爲過多的語音會分散玩家的注意力。我們的目標很簡單:在合適的時機,給出有幫助的語音提示。

具體工作原理是,首先遊戲內觸發特定事件,艾爾琳發現玩家需要或關注的物資,接着系統判斷該情況具備主動發言的價值,隨後艾爾琳就會主動提醒,比如“嘿,這邊有倍鏡”。還有一個重要的點,玩家可以自定義觸發條件,比如設置“找到醫療物資時提醒我”。
記憶能力
最後一個挑戰是記憶能力。核心目標是提取關鍵信息、保存並在後續場景中複用。如果沒有記憶,AI隊友每次對局都會像陌生人一樣,記不住你的名字、記不住你的打法,體驗會變得非常糟糕。
接下來看看具體的實現方式。對局過程中,玩家可能會說“我喜歡剛槍,咱們打得激進點”,同時遊戲中還有大量諸如操作步驟、對局結果的信息,這些都是記憶的輸入源。艾爾琳會持續捕捉對話內容和對局信息,篩選出其中的關鍵部分,比如玩家的偏好、互動中的反饋,並將其提煉爲簡短的摘要存入記憶模塊。
我們設置了持久化的記憶存儲區,會將有用的信息長期保存,而且這份記憶會跨對局生效,即便多局之後也不會丟失。同時還有記憶注入機制,會將存儲的記憶信息實時注入AI的決策模型,讓艾爾琳能結合記憶做出回應,比如會說“記得你喜歡剛槍,咱們衝過去”。
關於模型訓練與評估
以上講到的實時決策、安全交互、記憶能力,都基於小語言模型實現。這意味着我們需要持續訓練和優化這個模型。我們的全流程訓練體系是這樣的:首先從實際對局中收集數據,玩家和艾爾琳的真實對局過程中,我們會採集玩家的真實指令,將這些數據加入數據集,隨後基於新數據集對小語言模型進行微調訓練。
訓練完成後得到新版本模型,我們會從交互質量、安全合規、遊戲內行爲表現三個維度進行驗證,驗證通過後就會進行版本迭代,讓模型的表現持續優化。同時我們會針對薄弱環節補充更多數據,讓模型的能力更全面。
今天我重點講其中一個核心環節:邊緣案例挖掘。目標是找出數據集中未覆蓋、但實際對局中可能出現的場景。我們的訓練數據集包含了大量預設場景,比如“前往標記點”,但無法覆蓋玩家在真實對局中所有可能的表述。
實際遊戲中,玩家的指令會非常口語化、多樣化,在不同場景下會用不同的說法表達同一需求,比如“往這個方向走”,這就是數據集未覆蓋的邊緣案例。大語言模型憑藉通用理解能力,能很好地處理這類邊緣案例,但小語言模型的泛化能力有限,需要重點挖掘模型處理失敗的邊緣案例並針對性優化。

具體的挖掘方法是:首先從真實對局中收集大量玩家指令,隨後進行分類標註,嘗試將每個指令歸到我們預設的類別中。其中一些邊緣案例無法歸到現有的預設類別,這說明我們的類別覆蓋存在空白,真實玩家的部分指令是我們此前未考慮到的。
隨後我們會基於這些邊緣案例更新分類體系,比如新增“信息共享”這一類別,涵蓋“有人在這個點位落地”這類指令。之後針對新增類別補充數據、優化模型,這些原本的邊緣案例就不再是模型的短板了。反覆這個過程,分類體系會不斷完善,模型的失誤率會持續下降,表現也會越來越好。
我們會將這些挖掘出的指令意圖用於下一次的數據生成。基於這些指令意圖,我們主要挖掘兩類空白:第一類是低覆蓋度意圖,即數據集中該類意圖的樣本量不足,我們會針對性生成更多樣本;第二類是低質量意圖,即數據集中已有相關樣本,但模型的處理效果仍不佳,這種情況我們會覈查數據質量,或補充更多優質示例。核心思路很簡單:找到薄弱的指令意圖、補充數據、優化模型。
我們如何評估模型的優化效果?
主要關注兩個指標。第一個是動作決策準確率,即模型能否生成正確的行爲指令,我們會將模型輸出與大推理模型給出的參考答案對比,以此驗證準確率。第二個指標是交互溝通質量,即對話的流暢度和理解度,模型能否準確理解玩家的意圖。這個指標我們會通過大推理模型進行自動評估。這兩個指標的驗證,我們均採用真實玩家的預留測試集進行評估。
從測試結果來看,隨着訓練的推進,模型的各項指標持續提升,我們的小語言模型表現一步步變好。雖然大語言模型的指標仍高於小語言模型,但二者的差距在不斷縮小。
關於本地運行與上線計劃
我想強調的最重要的一點是:所有功能都能在玩家的個人電腦上本地運行。玩家的遊戲客戶端、語音轉文字、小語言模型、文字轉語音,所有模塊都在同一臺設備上協同運行。我們的最低配置要求爲3060顯卡,能在該配置下實現60幀的流暢體驗,同時保證80%以上的交互響應率。這一實現難度極大,因爲遊戲本身已經佔用了大量的顯卡和處理器資源,而我們能做到這一點,離不開和英偉達的深度合作。
從延遲測試結果來看,我們對比了小語言模型在本地顯卡、雲端服務器的延遲,以及大語言模型在雲端的延遲。在4090型號顯卡的高端電腦上,小語言模型的延遲極低,幾乎比雲端大語言模型快一倍,響應時間不到1秒;即便是在3060的最低配置電腦上,延遲也能控制在2.5秒以內。而云端大語言模型不僅延遲遠高於本地小語言模型,表現也不夠穩定。由此可見,本地顯卡運行模型有兩大核心優勢:速度快、表現穩。
最後要告訴大家的是,艾爾琳這款AI隊友不再只是研發演示版本,我們即將把它正式帶給玩家,作爲遊戲內的可選功能上線。這意味着玩家能在真實的遊戲體驗中和艾爾琳並肩作戰,目前該功能已在獨立測試環境中運行,正式上線時間預計在2026年的某個時間點。
我的分享就到這裏,謝謝大家!最後再聊聊相關的落地思路,包括實際應用效果、可能遇到的問題,還有更多驚喜等着大家。
以下爲演講結束後問答環節實錄(爲保證閱讀體驗,內容有所調整):
Q: 你們介紹的這套雙系統架構(一號系統基於決策樹驅動動作,二號系統基於大語言模型負責分析和對一號系統的修改),讓我聯想到心理學裏關於人類決策思維的雙系統理論。想請問你們的研發是否從這個理論中獲得了靈感?
A: 沒錯,我們確實參考了這一領域的相關理論。其實一號、二號系統的這種架構模式在認知科學領域是相當常見的,我也爲此研讀了相關的文獻資料。
Q: 對於AI系統,玩家的實際體驗是最重要的。我想了解貴公司是否已經針對這套系統開展了早期的玩家測試,哪怕只是內部的可用性測試?有沒有收集過玩家與AI(艾爾琳)互動時的真實感受和反饋?
A: 這是個非常好的問題。我之前在演講中主要展示了模型的決策準確率、交互質量這類量化指標,但這些與玩家的真實體驗之間確實還存在一些差異。所以我們已經在公司內部組織了大量的員工進行試玩,讓大家體驗AI隊友艾爾琳,並收集了很多反饋意見。基於這些反饋,我們對系統做了不少優化改進,公司裏有很多人都參與了多輪的試玩測試。
Q: 你們的遊戲應該會面向不同語言的市場,目前主要適配了哪些語言?相關的模型是自研的還是有合作?因爲做多語言適配需要投入不少研發資源。
A:目前我們主要適配了三種語言:英語、韓語和中文。
針對不同語言,我們做了獨立的模型處理,所有的小語言模型都是單獨訓練、獨立部署的。順帶一提,我們還對模型做了量化處理。因爲我們要求遊戲的最低運行配置是8G顯存,所以模型採用的是4比特量化計算的方式。
Q: 我想問一個偏運營層面的問題:你們是如何調節AI隊友的遊戲戰力的?在很多遊戲中,如果AI太強會降低可玩性。你們是如何避免這個問題的?
A: 關於這點大家完全可以放心,在當前的先行體驗版本中,艾爾琳的戰鬥能力其實並不算強。想讓AI在這款遊戲中表現出色其實難度極高,因爲這款遊戲的競技性本身就很強,而且很多玩家的遊戲水平已經非常高了。當然,我們也在持續開展相關研究,探索如何讓艾爾琳的遊戲戰力變得更強。
Q: 我想了解一下,在運行AI隊友的同時,遊戲還要進行圖形渲染,你們是如何兼顧這兩者的?是同時運行還是優先保障一方?另外,是否會根據遊戲運行情況動態調整模型策略,甚至跳過部分計算來管理資源?
A:我明白你的問題。簡單來說,如果玩家的設備顯存有限,想要流暢運行AI隊友,就需要適當降低遊戲的畫面畫質;如果玩家顯存足夠大,那麼即使開啓高畫質,也能正常運行AI隊友。
Q: 這麼說你們是讓AI模型和圖形渲染共用同一塊顯卡的顯存?
A: 是的,至少模型的運行是基於同一塊顯卡的。從實際體驗數據來看,AI的響應延遲控制在2秒以內,玩家的體驗就已經比較良好;如果能降到1秒以內,體驗會更出色。這是保證體驗的關鍵。
Q: 你們選擇使用小語言模型而非大語言模型,主要是爲了適配不同配置的玩家設備,還是更多出於成本控制?如果投入足夠資金,理論上也可以用大語言模型來做吧?
A:核心原因其實是體驗層面的延遲問題。 如果AI的反饋延遲達到5秒,玩家的體驗會非常糟糕。當然,成本和硬件適配的因素也有考慮。目前行業內語音交互技術的發展也印證了,小語言模型是比較合適的選擇。
Q: 那如果未來出現性能表現優異的端到端語音模型,能進一步降低延遲,你們會考慮採用嗎?
A: 沒錯,如果採用端到端的語音模型,確實能有效降低交互延遲。所以我們也在持續測試和評估,探索哪種類型的端到端語音模型最適配我們的遊戲場景。目前還在研究階段。有時候想到未來的技術發展,還挺讓人期待的。後續我們也會繼續推進相關的技術研發和測試。