斯坦福2026報告:中國AI模型追上美國
圖源:Unsplash
撰文 | 張天祁
責編 | 李珊珊
4月13日,斯坦福大學發佈了《2026年AI指數報告》。這是一份業內人士翹首以待的AI領域重磅年度報告,報告以243頁的篇幅、9個章節、數百張圖表,記錄了過去一年AI發展的真實面貌。
在這份報告中,AI的發展繼續一路高歌猛進,大量原本預期可以維持數年的高難度基準測試,如今往往在幾個月內便告破防。然而,在一些普通人類可以輕鬆完成的"簡單"任務中,AI卻依然屢屢碰壁。
AI持續進化的同時,全球地緣AI格局也在悄然生變。作爲後來者,中國大模型的性能正日漸逼近美國。在AI領域,美國仍擁有更多頂尖大模型和高影響力專利;而中國在論文發表數量、引用次數、專利產出和工業機器人裝機量方面,已呈現出明顯的領先趨勢。
此外,報告還涉及AI4Science、AI與教育、大模型透明度、AI對就業的影響,以及大模型相關的能源與算力等議題。
以下爲報告中的重要數據與結論摘選:
01 頂級模型性能,中美只差2.7%
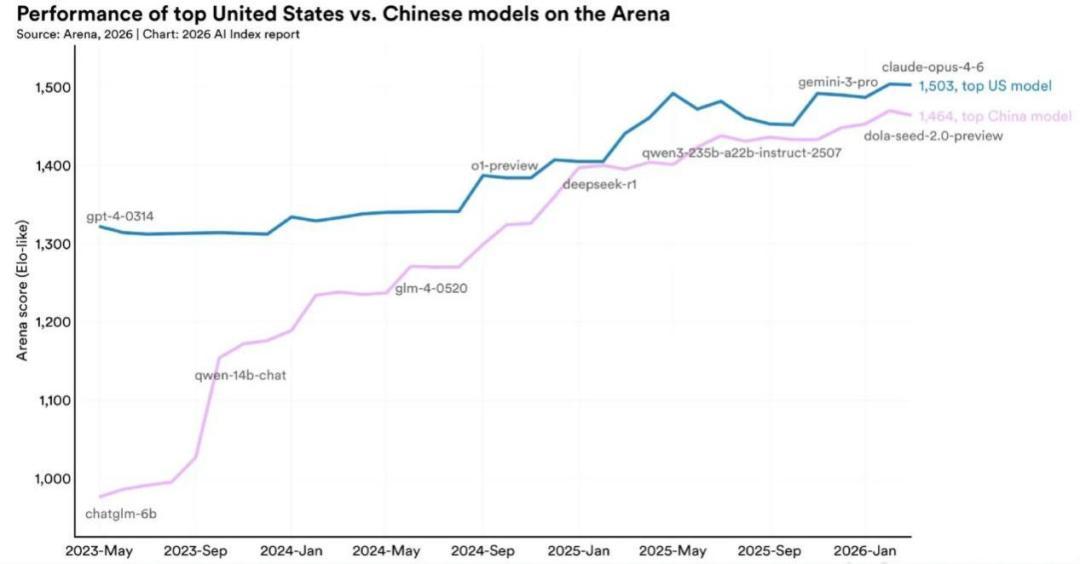
過去幾年間,大家有一個普遍的印象:美國在大模型領域遙遙領先,中國在努力追趕但始終有差距。但本次報告給出了一個不一樣的判斷,中國的頂級的大模型已經基本追上了美國。
2025年2月,DeepSeek發佈的R1模型短暫追平了彼時的美國最強模型。當時DeepSeek-R1(1400分)僅比當時領先的美國模型 o1-2024-12-17(1405分)落後0.4%。此後兩國模型多次交替領先。
2025年,美國產出了50個代表性模型,中國產出了30個。根據各個模型在Arena排行榜上的得分,截至2026年3月,Anthropic的頂級模型在Arena排行榜上以Elo分1503領先,差距約爲2.7%,且在過去一年中一直在持平到個位數範圍內波動。
事實上,當前頂級AI梯隊已經高度密集。在參考國際象棋建立的AI等級分系統裏,Anthropic(1503)、xAI(1495)、谷歌(1494)、OpenAI(1481)、阿里巴巴(1449)、DeepSeek(1424),這六家公司的模型已經全部擠進同一個分檔,也就意味着這些中美AI領域的“頂級高手”實力非常接近。競爭更多比的已經不是性能,而是向成本、可靠性和特定場景表現轉移。此外,按代表性模型數量統計,阿里巴巴、DeepSeek、清華大學和字節跳動均位列全球前十。
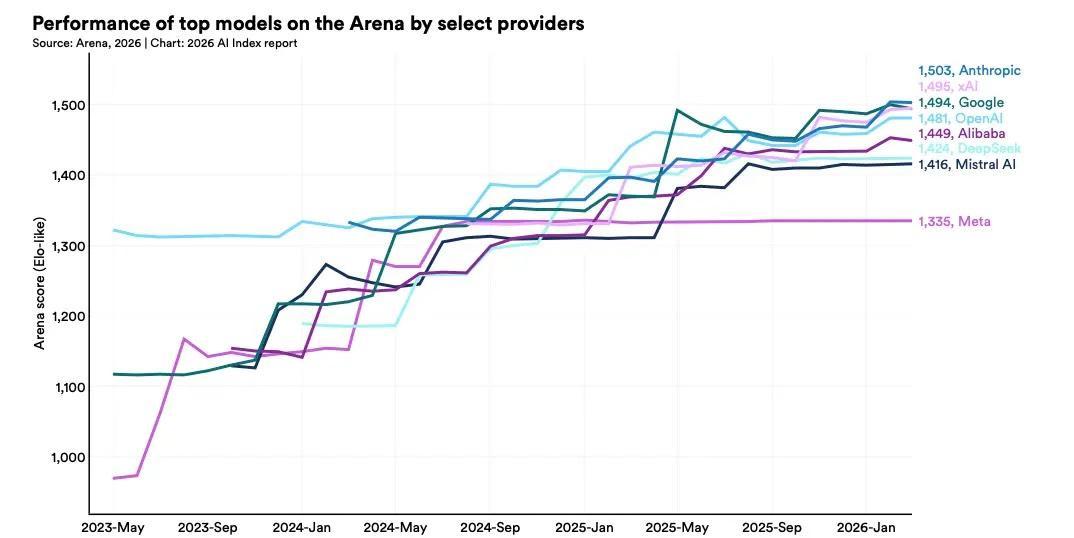
但在模型和機構評分之外,兩國的AI格局仍然存在結構性差異。
美國私人AI投資達到2859億美元,是中國124億美元的23倍以上。另一方面,自2000年以來,中國政府引導基金向AI公司注入的資金累計已達約1840億美元。
中國論文數量、引用量、專利總量上領先,並以一國之力佔據了2024年全球54%的工業機器人安裝量,且這一比例還在擴大。
在論文的引用佔比方面,中國AI論文在2024年貢獻了20.6%的AI引用,歐洲爲19.5%,美國爲12.6%。在高被引論文中,美國仍然每年排名第一,但其份額從2021年的64篇下降至2024年的46篇,中國則上升至2024年的41篇,差距已經很小。
從專利數量上看,中國佔據絕對多數,佔全球總量的 74.2%。美國位列第二,佔 12.1%。但從引用上來說,全世界50%的專利引用都出自於美國專利,而且美國專利通常被引用更快且更穩定,僅有 19% 未被引用。相比之下,其他地區這一比例爲 32%–44%。從專利的影響力上看,美國仍更具優勢。
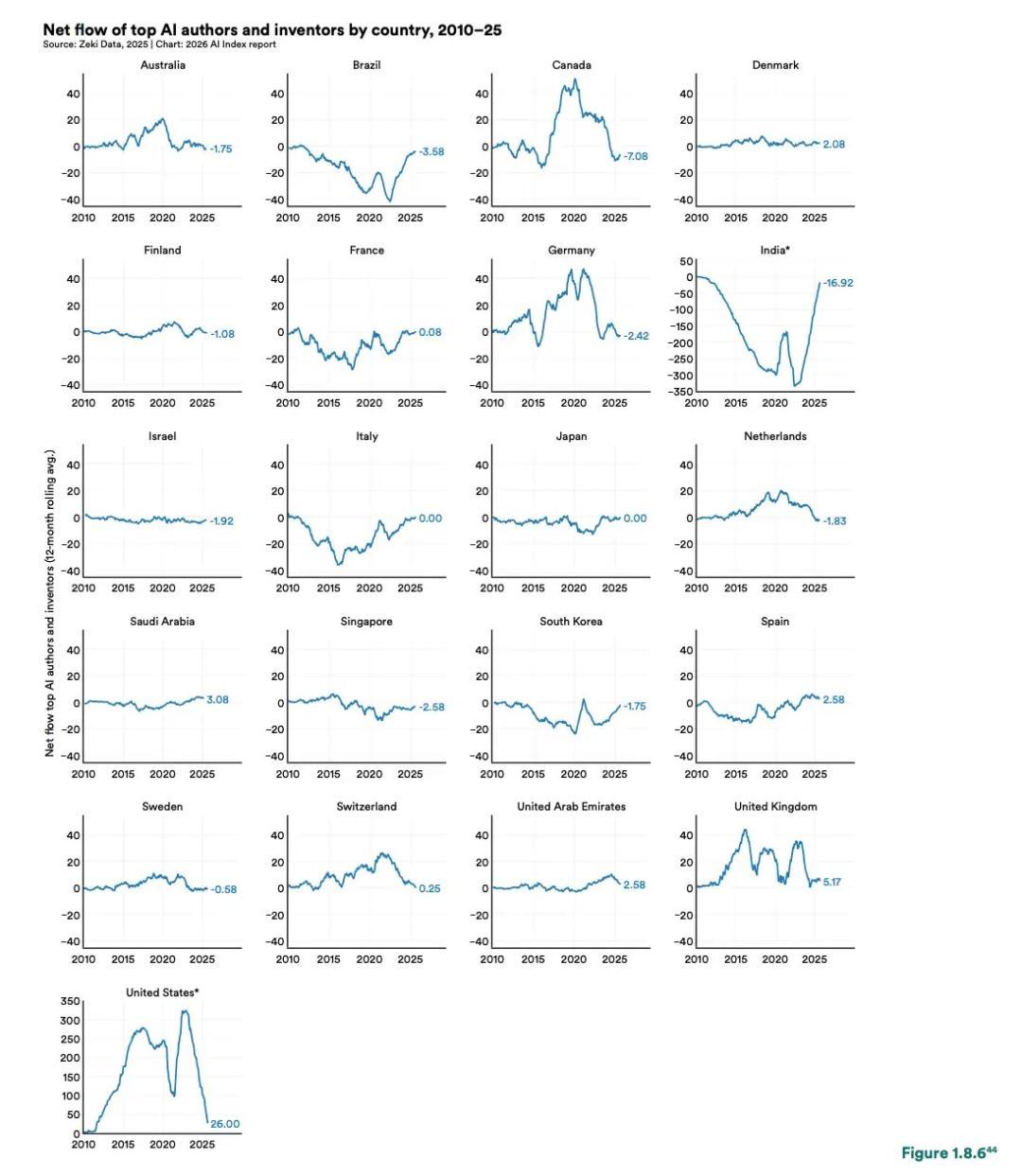
從人才上講,2025年,美國在高影響力AI研究者與發明人規模上仍領先於其他國家。在吸引頂尖AI人才這方面。美國自2020年以來一直保持人才淨流入狀態,吸引的人才多於流出的人才。
但這一優勢正在減弱,自 2017 年以來,移居美國的頂尖 AI 研究人員和開發人員數量下降了 89%。淨流入規模從2022年的峯值324.6下降至2025年的26.0。
02 AI飛速進化,現有的測量基準被攻陷
理解 AI 的能力,很大程度上依賴於一套不斷被使用的評測體系。長期以來,無論是學術界還是產業界,都共享着相對穩定的基準框架:通過分數、排名與標準化任務來比較模型能力。但今年AI的能力飛漲,一些測量基準開始跟不上AI的腳步了。
首先,AI能力的進步實在太快。原本預期可以維持好幾年的高難度評估,如今往往在幾個月就被失守了。
一些幾年前AI表現還很不行的領域,都在今年有了飛速的進步。包括博士級科學問題(GPQA Diamond)、多模態推理(MMMU)以及數學推理(AIME),都達到或者接近了人類專家水平。
變化最直觀的是多模態推理領域。MMMU要求模型在文本與視覺信息之間建立對應關係,例如讀取圖表中的約束條件並將其應用到文字問題,或根據工程與醫學示意圖推導答案。到2026年2月,Gemini 3.1 Pro Preview在該基準上取得88.2%的成績,僅比人類專家基準低0.4個百分點。
另一項進展出現在純文本高難度推理任務上。GPQA主要評估研究生級別的科學推理能力,問題設計刻意排除了依賴檢索的可能性,需要通過多步推導才能完成。
在該基準的Diamond子集中,模型表現已率先超過81.2%的專家驗證基準(見圖2.4.2)。這一突破發生在2024年末,由OpenAI的o3首次實現,達到87.7%。隨後一年中,平均準確率繼續上升,到2025年提升至93%,穩定超過專家參考線。
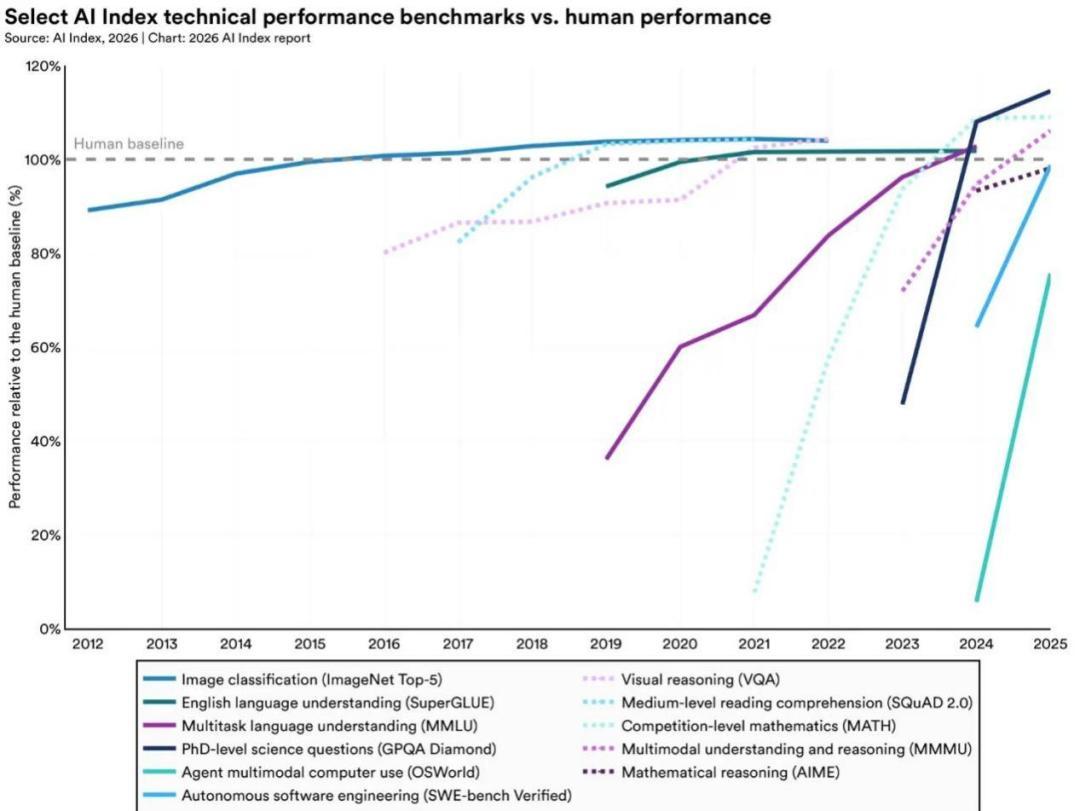
在真實軟件工程任務測試集 SWE-bench Verified 上,模型在修復 bug 的表現相較人類基準,從約60%的完成水平迅速提升至接近100%,雖然還沒有真正達到人類基準,但這一過程僅用了不到一年時間。
“人類最後的考試”(Humanity''s Last Exam)還沒有失守。這個基準是專門爲難住AI而設計的,出題方有意拔高難度,想讓它至少維持幾年的有效性。但是從2024到2025年,它的準確率提升約30個百分點,從不足10%上升至38.3%。
另外,很多評價基準本身也有問題。一項針對主流基準的系統性審查顯示,其中無效或存在問題的題目比例差異極大:在 MMLU 的數學子集上約爲 2%,而在 GSM8K 中則高達 42%。這意味着,在一些被頻繁引用測試中,接近一半的題目本身並不具備穩定的測量意義。然而,我們還在用這些基準測量AI是否達到人類水平。
第三個問題是操縱。已有研究指出,在某些公開排行榜(如 Arena)上的排名,可能並不完全反映模型的真實通用能力,只是模型適應了平臺的出題風格。
AI的能力在以肉眼可見的速度增長,但我們賴以描述這種增長的語言和工具,反而出現了失效。我們越來越難以回答一個最基本的問題:這些模型到底有多好?
03 能拿奧運金牌,但卻看不懂手錶
通過一套基準來判斷AI能力的另一個問題是,AI實在是偏科過於嚴重。
2025年的IMO(國際數學奧林匹克競賽)上,谷歌的Gemini Deep Think以35分的成績獲得金牌,在4.5小時的限時內全程用自然語言推理作答,比2024年的銀牌成績(28分)大幅提升。
但在ClockBench這個測試模型能否讀取指針式時鐘的評測中,最強模型的正確率只有50.1%,而人類的成績是90.1%。同一個系統,能解開人類頂級數學家才能駕馭的競賽題,但是卻看不懂手錶。
這就是報告所描述的“鋸齒狀智能”(jagged intelligence):AI的能力邊界不是一條平滑的曲線,而是一條參差不齊的鋸齒。它可以在某些人類最難的任務上完勝,卻在某些人類小學生都能完成的任務上潰敗。
在AI 智能體和機器人方面,問題也是相似的。在 OSWorld(跨操作系統真實任務測試)中,AI 智能體的成功率從 12% 提升至約 66%,但仍有約 1/3 任務失敗。機器人在實驗室模擬環境 RLBench 中,成功率達到 89.4%。但是真實情景中的成功率只有12%。
04
做題勝過科學家,但做研究還不行
“科學”章節是今年報告新增的一章,它通過一組數據展示了AI在科學領域的進展速度,同時也揭示了其可靠性仍然有限。
在ChemBench上,前沿模型在2700多道化學題目上的平均表現超越了人類化學家,但同時在基礎任務上表現掙扎。在ReplicationBench上,這些模型試圖復現天體物理學已發表論文的實驗結果,得分低於20%。
做題和做研究,是兩件完全不同的事。前者考驗的是從已有知識中檢索和推理的能力;後者要求的是理解一個實驗的完整邏輯、處理真實數據的噪聲、在不確定條件下作出判斷。目前的AI在前者上已經相當出色,在後者上仍然非常有限。
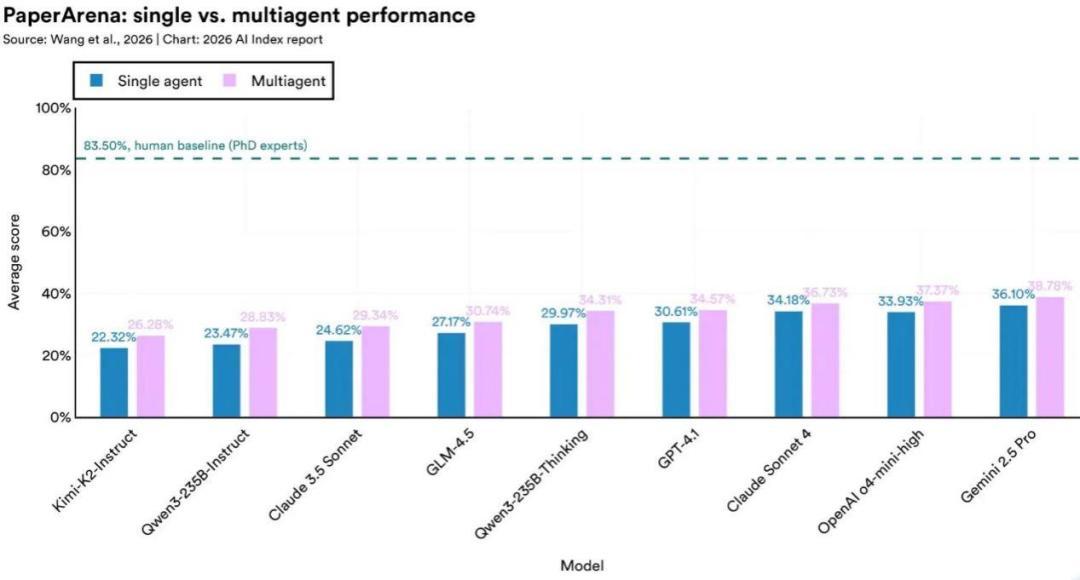
在端到端科研任務評測PaperArena上,最好的AI 智能體得分38.8%,博士專家的基準是83.5%,不到一半。在真實生物信息學分析任務BixBench上,前沿模型的準確率約爲17%。在地球觀測問題評測UnivEarth上,AI agent的回答準確率爲33%,生成的代碼有58%運行失敗。
2025年,第一篇完全由AI生成的論文在同行評審的研討會上被接受,谷歌的AI Co-Scientist也在三個生物醫學領域獲得了實驗驗證。然而,經過實驗確認的AI科學發現,清單仍然很短。
05 最強的模型,也是最不透明的模型
2025年,產業界貢獻了超過90%的代表性AI模型,但最強的模型仍然主要是閉源模型。訓練代碼、參數規模、數據集規模與訓練時長等關鍵信息,在OpenAI、Anthropic和谷歌等資源投入最密集的模型中,已基本停止對外披露。
在2020年,開源與未公開訓練代碼的模型數量還是大致相當的。但到了2025年,在95個重要模型中,有80個未公開其訓練代碼,僅有4個實現了代碼開源。
從性能上,開源模型曾短暫逼近閉源模型,甚至接近改寫格局的邊界,但在2025年和閉源模型又稍稍拉開了差距。
雙方的起點差距很大,2023年5月,閉源模型 GPT-4-0314 在 Arena 排行榜上領先最強開源模型 Vicuna-13B 達174分(15.2%)。但隨後一年中,隨着 Mixtral、WizardLM 和 Llama-3.1-405B 等模型相繼出現,開源模型快速縮小差距,到2024年8月已將差距壓縮至僅7分(0.5%),一度接近追平。
然而,進入2025年後,隨着 o1-preview 和 Gemini 2.5 Pro 等新一代閉源模型發佈,領先優勢再次回到閉源陣營。截至2026年3月,Claude Opus 4.6(1503分)重新拉開與最強開源模型 GLM-5(1454分)的距離,差距回到49分(3.4%)。
這一趨勢在“基礎模型透明度指數”上同樣清晰可見。這是一個一個用0到100分衡量AI模型“開放程度”的指標體系,評分依據包括:模型權重是否可以自由獲取與授權使用,以及訓練方法、預訓練數據與後訓練數據的透明度水平。現在的主流模型的開放程度普遍較低,大多數得分集中在2到16分之間。
該指數的業界平均分在2023年爲37分,2024年上升到了58分,一度讓人對透明度改善抱有期待。然而2025年,這個數字跌回了40分,幾乎抹掉了一年間的所有進展。
06
生產率在提升,入門級崗位在消失
總體來看,AI對經濟增長具有一定的促進作用,但對就業來說卻未必。
一項針對1.2萬家歐洲企業的研究發現,AI採用使勞動生產率提高了4%,而培訓能夠進一步增強這一效果。在美國,2025年的生產率增長達到2.7%,幾乎是過去十年平均水平1.4%的兩倍。
對打工人的利好是,AI在很多領域真的能提高效率。在客服領域,AI帶來了14%至15%的生產率提升;在軟件開發領域,實測提升幅度達26%;在營銷內容輸出方面甚至高達73%。生成式AI工具爲美國消費者帶來的年度價值估計已達1720億美元,較一年前的1120億美元增長54%,且其中大多數工具是免費或接近免費獲取的。
但是從就業上看,AI對年輕人很不友好。AI正在逐漸替代職業階梯的最底層,也就是那些原本由年輕人來承擔的入門級工作。年輕人失去的不只是一份薪水,而是積累經驗、進入行業的通道本身。
從數據上看,美國22–25歲的年輕羣體中,高AI暴露職業的就業水平相比低暴露職業下降了約16%。這一差距差距自2024年年中開始擴大,並在此後持續增長。
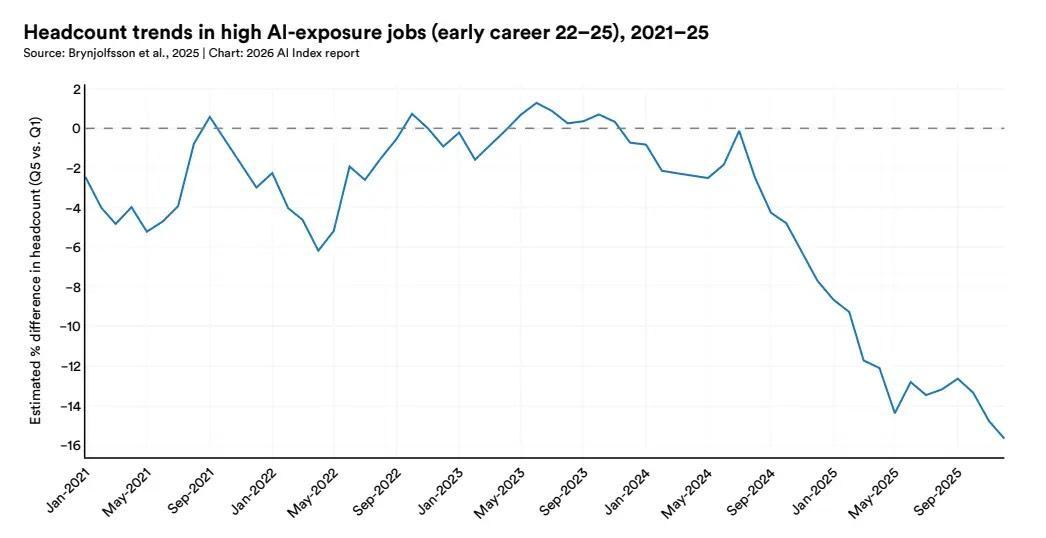
這一點,在年輕的軟件開發者身上體現的特別明顯。美國22-25這個年齡段的軟件開發者,就業人數自2024年以來下降了近20%。與此形成對比的是,更年長的開發者羣體人數仍在增長。
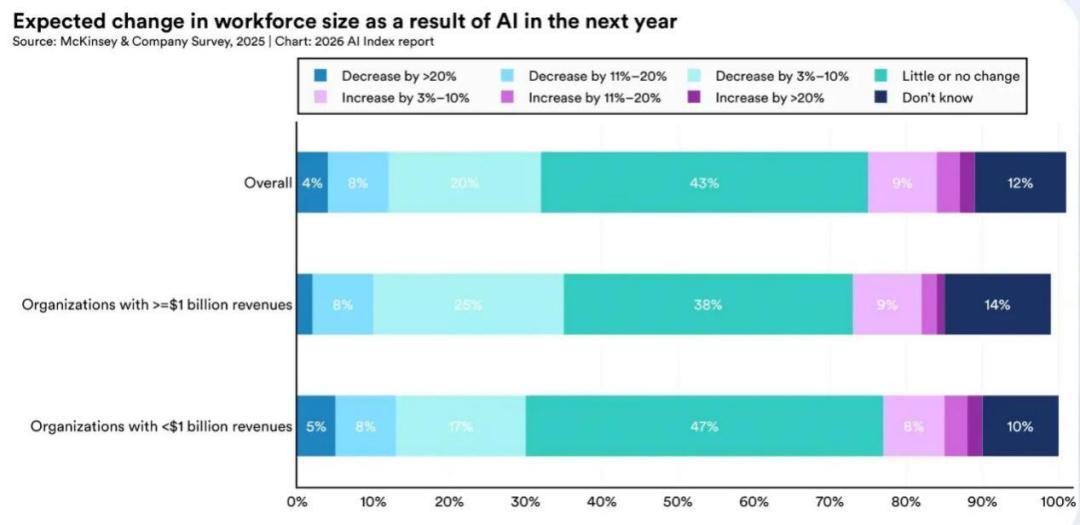
雖然從整體來說,AI還沒有明確導致失業,但是從僱主的態度上,可能很多職位在未來都會受到削減。據麥肯錫2025年的調查,約三分之一的受訪者預計員工規模將出現下降,而且這一比例在大型企業(年收入≥10億美元的企業)中更高,而只有很少的僱主計劃增加人手。
報告還補充了一個細節。有證據顯示,對AI的高度依賴可能帶來長期學習懲罰,減慢人類技能的發展速度。生產率的短期提升,與人類能力的長期侵蝕,可能不是非此即彼的,而是正在同時進行。
07 能源與算力
自2022年以來,全球AI算力能力以每年3.3倍的速度增長,已達到約1710萬H100等效算力單位。
美國共擁有5427個數據中心,是其他任何國家的10倍以上,同時其能源消耗也高於世界上任何其他國家。德國(529個)、英國(523個)和中國(449個)位列其後,其餘大多數國家的數據中心數量均不足300個。
AI公司的收入正以罕見速度增長,但算力與基礎設施成本同步攀升,且增速同樣顯著,這主要體現在雲服務商資本開支的快速擴張上,例如谷歌在2025年的資本支出已超過1500億美元。
資源消耗也隨着模型能力同步上升。Grok 4 的訓練排放約爲 72816 噸二氧化碳當量,AI 數據中心電力容量達到 29.6 GW,這一規模接近紐約州的峯值電力需求。僅 GPT-4o 的年度推理用水量,就可能超過 1200 萬人的飲用水需求。不過模型能力未必完全等於能源消耗,DeepSeek v3 的排放就顯著低於同規模模型。
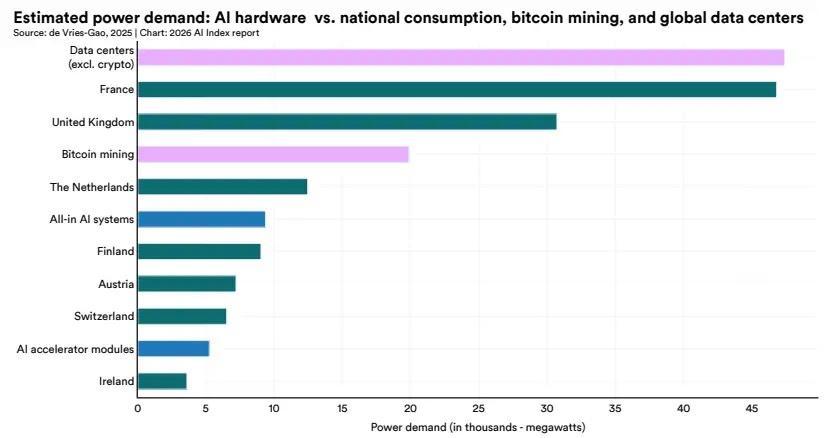
從規模上看,整體AI系統的用電需求已接近瑞士或奧地利的全國電力消費水平,也大約相當於比特幣挖礦的一半。在不計入加密貨幣的情況下,全球數據中心的電力需求約爲47000 MW,其中AI硬件所佔比例正在持續上升。
08 教育與治理,制度明顯滯後
AI 的擴散速度明顯快於以往技術。生成式 AI 在三年內已經達到 53% 的人口使用率,這一速度超過了個人電腦和互聯網。企業層面的採用率達到 88%,大學生中約有 80% 已經使用生成式 AI 工具。
在印度、中國、尼日利亞、阿聯酋和沙特阿拉伯等新興經濟體中,超過80%的受訪者表示在工作中經常使用AI,同時這些國家的信任水平也相對較高。
教育系統中,AI也已經廣泛普及。超過 80% 的美國中學生和大學生在學習中使用 AI。反倒是學校沒有跟上學生的腳步,只有約一半的學校制定了相關政策,而認爲政策清晰的教師僅佔 6%。
正規教育對AI發展的反應正在顯現出明顯滯後,而越來越多的人開始繞開傳統教育體系,通過證書課程、在線學習和在職實踐學習AI。
總體來看,AI素養類技能(例如爲AI寫提示詞)的增長更爲迅速,但在阿聯酋、智利和南非等國,AI工程技能(例如構建AI智能體)增長得更快,意味着在這些國家,學習不再停留在對工具的理解,而是更多進入應用與實踐,在真實使用中學習。
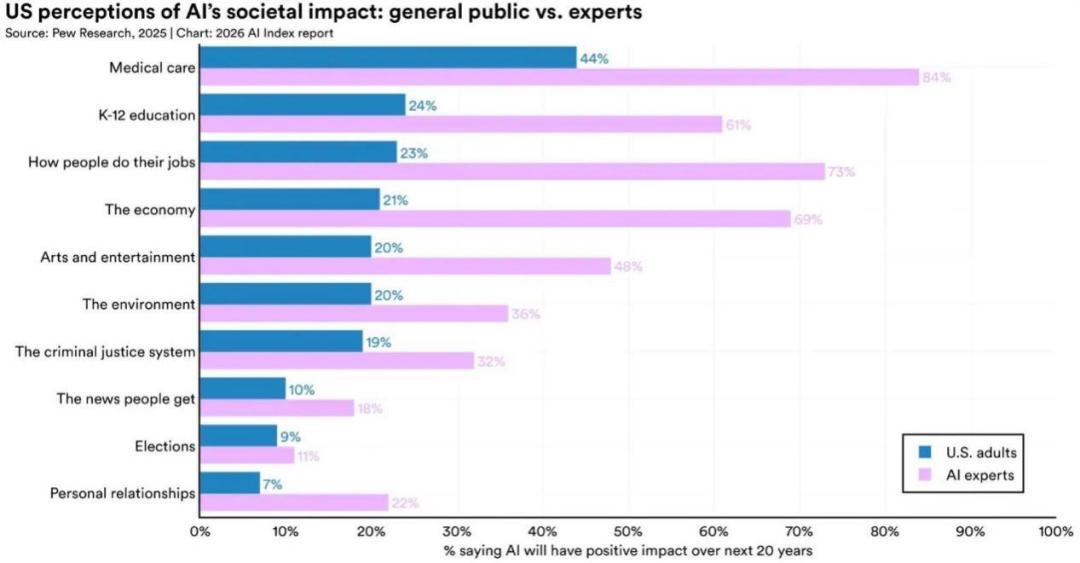
從治理上看,民衆對AI的信任程度並不高。根據皮尤(Pew)調查,專家與公衆對AI的預期已經出現了明顯的分歧。在美國,73% 的專家認爲 AI 會對工作產生正面影響,而公衆中持相同看法的僅爲 23%。近三分之二的美國人(64%)預計人工智能將在未來 20 年內導致就業崗位減少,而只有 5% 的人預計會增加就業崗位。在醫療和經濟方面,雙方同樣分歧嚴重。
不僅是不信任專家,美國公衆對AI政府監管的信任度爲 31%,在被調查國家中處於最低水平。也就是說,AI能力最強的國家,恰恰是本國公衆最不信任其政府來治理AI的國家。
而從美國國會的聽證會人員構成來看,涉AI聽證會的參與者中,業界代表比例從2017年的13%飆升至2025年的37%,成爲最大的羣體,學術界則降至15%。民衆對於AI的不信任,並非沒有理由。誰在主導關於AI的政策討論,數字已經給出了答案。
參考文獻:
[1] Sha Sajadieh, Loredana Fattorini, Raymond Perrault, Yolanda Gil, Vanessa Parli, Lapo Santarlasci, Juan Pava, Nestor Maslej, Russ Altman, Erik Brynjolfsson, Carla Brodley, Jack Clark, Virginia Dignum, Vipin Kumar, James Landay, Terah Lyons, James Manyika, Juan Carlos Niebles, Yoav Shoham, Elham Tabassi, Russell Wald, Toby Walsh, Dan Weld. “The AI Index 2026 Annual Report,” AI Index Steering Committee, Institute for Human-Centered AI, Stanford University, Stanford, CA, April 2026.