很強!人形機器人VLA 驅動全身協同在智元得到驗證,行走與操作同時完成




讓人形機器人能夠像人一樣完成裝箱、搬運、推車等移動操作任務,一直是人們對具身智能的期待。近日,來自香港大學、智元AGIBOT、復旦大學和上海創智學院的聯合研究團隊提出了WholeBodyVLA,一種面向真實世界的人形機器人全身Vision–Language–Action 框架。該工作基於智元靈犀X2研究發佈,將VLA(視覺語言動作模型)擴展至雙足人形機器人的全身控制,驗證了其在全身移動操作任務中的可行性。
與原地操作相比,移動操作的難點不在於單一技能,而在於行走與操作必須在同一任務中長期、穩定地協同發生。圍繞這一挑戰,WholeBodyVLA 總結出限制移動操作發展的兩個核心問題:真機數據稀缺和運動執行中的不穩定性。
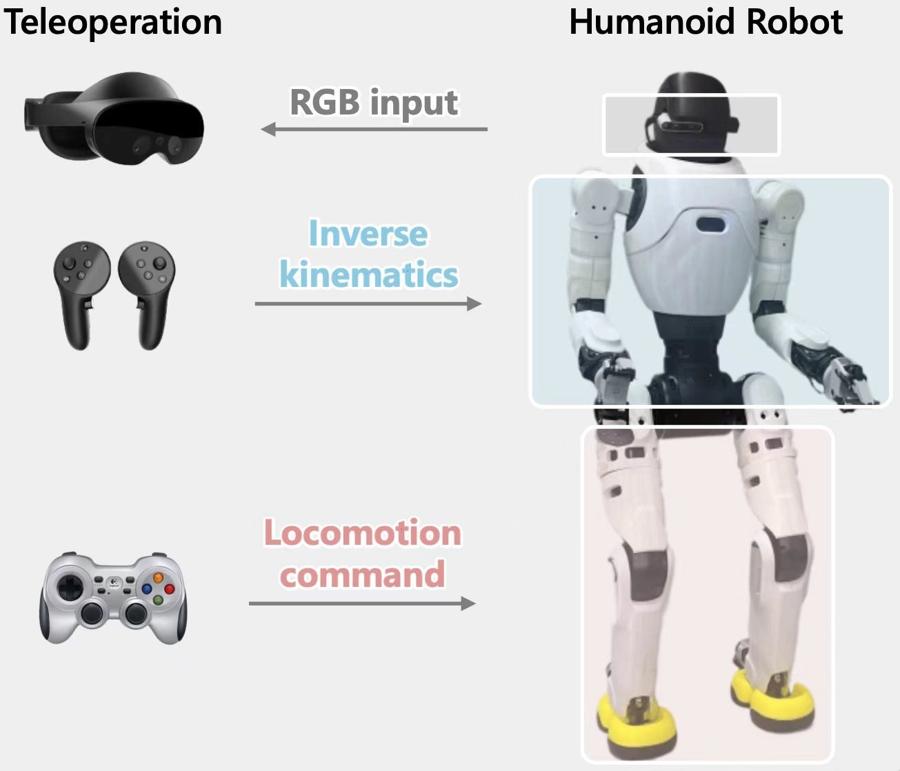
相比原地操作,人形機器人在移動操作任務中的數據採集要“貴”得多。往往需要不止一個數採員同時遙操機器人上半身進行操作、下半身完成行走,這通常只能通過混合方案實現(例如 VR 控制上半身、遙控器控制下半身),這種方式操作流程長、效率低;或者使用全身動捕系統,但價格高昂。
相比純粹的操作,移動操作對運動精準性和穩定性的要求高的多,任何偏離都可能導致目標操作物體脫離相機視野和工作空間。即使VLA輸出了正確的運動指令,下半身控制器仍然有概率執行失敗,例如出現走歪、踉蹌等現象。

爲了解決這些挑戰,研究團隊提出了WholeBodyVLA,並引入了兩個關鍵創新:從人類視頻中學習和麪向移動操作的RL控制器。前者是WholeBodyVLA 通過從第一視角人類視頻中學習移動與操作的潛在動作,操作相關的潛在動作則基於 AgiBot World 數據集進行建模,後者是通用連續運動控制目標簡化爲一組離散運動指令,僅保留移動操作必要的強化學習訓練目標,從而顯著提升了控制器在運動執行時的穩定性。
研究團隊在 智元靈犀X2人形機器人上進行了大量真機實驗驗證,發現 WholeBodyVLA 具備大範圍、長程移動操作任務,距離泛化性和操作泛化性,地形泛化性。總的來說,WholeBodyVLA 展示了 VLA 擴展到雙足人形機器人自主全身控制的可行路徑。

















