讓谷歌橫空出世的世界最大矩陣

圖源:pixabay
撰文 |丁玖 朱慧堅(廣州南方學院)
1998年9月4日,兩個25週歲的年輕小夥拉里·佩奇(Larry Page,生於1973年3月26日)和謝爾蓋·布林(Sergey Brin,生於1973年8月21日)在加利福尼亞州舊金山灣區聖馬特奧(San Mateo)縣的城市門洛帕克(Menlo Park)提交了谷歌公司的註冊文件。這個小城僅有三萬多居民,南面的近鄰是斯坦福大學,而他們正在那裏攻讀計算機科學系的博士學位。
他們創辦的這家公司,四分之一個世紀後,其“谷歌搜索”成了全球訪問量最高的兩個網站之一。佩奇和布林最初將他們開闢的新搜索引擎暱稱爲“背部按摩(BackRub)”,因爲該系統會檢查反向鏈接來評估網站的重要性。最終,他們將名稱改爲Google,然而這是對古戈爾(googol)一詞的錯誤拼寫。古戈爾是一個巨大的數字10100(1後面跟着100個零),選擇這個數字是爲了表明該搜索引擎旨在提供大量信息。不過,直到今天,全世界的網頁個數還遠遠低於這個已經超過宇宙所有原子個數的大數;或許永遠也達不到。
古戈爾由美國哥倫比亞大學數學系教授愛德華·卡斯納(Edward Kasner,1878-1955)的侄子、年僅9歲的米爾頓·西羅塔(Milton Sirotta)創造,用來表示一個難以想象的大數。卡斯納在其1940年出版的《數學與想象力》一書中推廣了古戈爾的概念,它形象地展示了大數與無窮之間的尺度,想必谷歌的創始人受此啓發,給他們的搜索引擎新生兒起了這個拼錯了一個字母的名字。順便一提,卡斯納最傑出的弟子是首屆菲爾茲獎的兩名獲獎者之一、美國數學家傑西·道格拉斯(Jesse Douglas,1897-1965)。
無論佩奇還是布林,創辦公司後都沒有待在世界名校斯坦福美麗的校園,穩穩當當地堅持到最後,以獲一紙博士證書。他們最終的學位——碩士——仍然高於年長他們18歲的比爾·蓋茨(Bill Gates,1955-);後者入學哈佛大學讀本科兩年後毅然退學,與合作伙伴開創了微軟公司,開啓了他一生的輝煌事業。佩奇和布林共同創辦的公司——谷歌——同樣也成了本世紀全世界最著名的高科技公司之一。沒有追求學位圓滿的他們三人,後來都被選爲美國國家工程院院士。
佩奇和布林都有猶太血統。兩人中,年輕半歲的布林有個數學家爸爸,佩奇的父親則是計算機科學家。布林之父米哈伊·布林(Mihail Brin,1947-)是個國際知名的俄羅斯純粹數學家,專長爲動力系統與黎曼幾何,本科畢業於莫斯科大學,博士導師爲蘇聯動力系統大家德米特里·阿諾索夫(Dmitri Anosov(1936-2014)和阿納托爾·諾克(Anatole Katok,1944-2018)。布林教授在普林斯頓大學數學系編輯的純數學國際頂尖雜誌《數學年刊》上發表過三篇論文,也出版過書籍,如與他後來的馬里蘭大學同事合著的《動力系統引論》,2015年由劍橋大學出版社推出。
小布林6歲時隨全家從蘇聯移民到美國。1990年他追隨父親的腳步跨進了馬里蘭大學,不過,父親是數學系的教授,他則在數學系和計算機科學系讀本科。三年後,他以數學與計算機科學雙專業榮譽畢業生的優異成績獲得學士學位。馬里蘭大學數學系一直引以自豪的另一個本科畢業生是菲爾茲獎獲得者查爾斯·費弗曼(Charles Fefferman,1949-),他17歲就獲得數學與物理學的雙學位,於普林斯頓大學獲得數學博士後,22歲時成爲芝加哥大學的正教授;他的同門博士師弟就是另一個菲爾茲獎獲得者陶澤軒(Terence Tao,1975-)。
佩奇是個土生土長的美國人,他的父親卡爾·佩奇(Carl Page Sr.,1938-1996)是筆者之一博士母校密歇根州立大學的計算機科學教授。老佩奇博士畢業於密歇根州的首席大學、也是全美最負盛名的公立大學之一密歇根大學的計算機科學系,在其職業生涯中是美國人工智能研究的先驅之一。可惜佩奇教授英年早逝,未能像布林教授那樣目睹了兒子成長爲業界巨人。
小佩奇也步了父親的後塵,一腳跨進密歇根大學的校門,父子倆成爲這所被譽爲“美國公立大學之母”的中西部巨無霸大學的先後校友。在父母的直接影響下,兒子6歲時就對電腦產生了興趣,因爲他可以“玩弄那些散落在周圍的東西”——他父母留下的第一代個人電腦。他成爲“小學裏第一個用文字處理器交作業的孩子”。可以說他是在電腦配件的叢林中長大的,“熟能生巧”這一中文成語可以恰如其分地形容佩奇從兒童走向青年對計算機世界的癡迷程度。後來他說:“從小我就意識到自己想發明創造。所以我對科技和商業產生了興趣。大概從12歲起,我就知道自己最終會創辦一家公司。”
在密歇根州立大學所在地東蘭辛高中畢業後,從1991年到1995年,佩奇在密歇根大學讀計算機工程,以榮譽稱號獲得工程學士學位,然後進入西部學術重鎮斯坦福大學攻讀計算機科學博士學位,在他創業元年獲得碩士學位。
在尋找論文選題時,佩奇考慮探索萬維網的數學特性,將其鏈接結構理解爲一個龐大的有向圖。他的導師特里·維諾格拉德(Terry Winograd,1946-)鼓勵他繼續研究這個想法。2008年穀歌20週歲,佩奇以感恩之情回憶道:“這是我收到的最好建議。”
成功實現快速高效網頁搜索的好想法,不僅得益於有深遠眼光學術導師的好建議,還需要背景類似、志同道合、互補長短的合作伙伴,這對應用科學十分奏效。在斯坦福這個佈滿才華橫溢年輕學者的校園內,同在計算機科學疆場習武的布林加入到佩奇的行列,兩人結伴開始了對網頁搜索引擎的創新研究。卓有成效的共同努力導致“網頁排序(PageRank)”這個互聯網史上具有里程碑意義的新穎概念和術語的誕生。
在英文的語義下,兩個單詞的無空格組合PageRank可以有兩層含義;其一是與實施對象相關的如上翻譯“網頁排序”,其二是“佩奇排序”,理由爲Page是佩奇的姓。事實上,“PageRank”這個名字是個雙關語,既指網頁排名算法,也指其開發者佩奇。該算法最初是作爲一種基於鏈接流行度對搜索結果進行排序的系統而開發的。
四分之一個世紀以來,世人盡知谷歌擁有史上最成功的搜索引擎,然而有幾人瞭解到是什麼魔法使它進入市場後迅速走紅,又有幾人通曉引導它成功的關鍵數學爲何?今天是第七個國際數學日,正是每個數學愛好者甚至數學同情者可以藉機接受數學普及的好日子。筆者受中國數學會的一則通知啓發,想到谷歌矩陣這個與國際人的日常生活、學習工作、職場發展都有關係的“全世界最大的矩陣”,覺得談談它或許是向國際數學日所獻的一朵豔麗之花。
由於網頁數量龐大(目前網站總數超過13億,但只有約六分之一的網站“被積極維護”。搜索引擎索引的實際網頁數量在40億至60億之間,而搜索引擎識別的網頁數量則超過130萬億),網絡信息檢索比傳統的信息檢索更具挑戰性。在網絡信息檢索研究中,每個網頁都被表示爲一個超大型有向圖中的一個節點,連接這些節點的有向邊代表頁面之間的超鏈接。
這種超鏈接結構可以通過三種信息檢索方法進行探索,第一種是“超文本誘導主題搜索”,其代表性論文是J. Kleinberg於1999年在美國計算機協會雜誌上發表的Authoritative Sources in a Hyperlinked Environment(超鏈接環境中的權威來源);第二種是“鏈接結構分析的隨機方法”;第三種是本文將重點介紹的網頁排序法,最初思想由佩奇和布林於1996年醞釀而生,他們對此的第一篇技術性文章由四人合寫,其中最後一位作者就是他們的導師維諾格拉德。這篇歷史留名的論文於1999年以斯坦福大學計算機科學系技術報告1999-0120的方式公開問世,標題是The PageRank Citation Ranking: Bringing Order to the Web(PageRank引用排名:爲網絡帶來秩序)。儘管該文似乎從未在學術期刊上正式發表,迄今卻已被引用了兩萬餘次。可見並非總是在名刊甚至期刊上發表的論文才會“推動科技的進步”。
在網頁排序概念出現兩年後橫空出世的谷歌公司,一開始就在官網聲明:
網頁排序是我們軟件的核心。
又過了以驚人速度壯大發展的四年,與公司員工共舞的其尺寸大得難以想象的那個矩陣——後被人們常掛在嘴邊的“谷歌矩陣”,引發出大型通用計算程序包Matlab的開發者克利夫·莫勒(Cleve Moler,1939-)的感慨,在自己公司MathWorks的《Matlab新聞和簡訊》上撰文《世界上規模最大的矩陣計算》。
那麼,這個世間最大的矩陣是怎麼定義出來的?
首先,它是一個非負矩陣,即矩陣的每個元素都是非負實數,並且它也是個方陣,即行數等於列數。其次,它的每一行的所有元素加起來都等於1。這種特殊的非負矩陣有個學名,叫隨機矩陣(stochastic matrix)。在線性代數這門應用廣泛的數學學科,“非負矩陣理論”構成了一個子學科,而隨機矩陣又是其中的核心部分。可惜的是,我們的本科教科書中一般不放進這類東西。
要充分理解谷歌矩陣的定義基礎,先得從網頁排序的基本想法開始。
網頁排序的理念是:
來自重要頁面的鏈接應該比來自不太重要頁面的鏈接權重更高,並且來自任何源頁面的鏈接的重要性應該根據該源頁面鏈接到的頁面數量進行縮放。
這個創新思想是容易想得通的。多年前,當筆者之一在國內高校做有關谷歌矩陣的演講時,向聽衆如此解釋它:國家領袖網頁上的內容肯定比數學教授的網頁內容在大衆眼裏更加重要,而且前者的網頁會被更多的網頁鏈接到,因此它應享有更加靠前的排名。如果採用數學語言來表達前述的意思,那麼該想法是通過定義給定網頁P的合理排名r(P)來實現的。r(P)定義爲:
r(P) = ∑ Q ∈ I(P) r(Q)/|Q|,
其中I(P)是所有指向P的那些網頁組成的集合,r(Q)是網頁Q的排名,|Q|表示從網頁Q發出的鏈接數。如上表達式說明,網頁P的重要程度,首先依鏈接到它的其他網頁的多寡而定,越多越重要,且那些指向它的網頁Q越重要,則P也隨之越重要,可謂“水漲船高”;其次,若指向網頁P的某個網頁Q也指向其他網頁,則被鏈接的網頁越多,P在Q眼中的重要性相應就變低,這解釋了爲何|Q|出現在分母。打個比方,如果閣下的網頁被某個名流鏈接到,不必太得意,或許該名流熱衷於社會交際,同時也鏈接了其他許多人的網頁,這樣的話你的網頁重要性並沒有因該名流的光顧而大增。
以上對單個網頁P的排名r(P)雖然定義合理,但這是一個隱式定義,因此我們借用迭代法來找到上述“不動點方程”的一個解,方法如下:
假設共有n個網頁P1,P2,...,Pn。爲每個網頁分配一個初始排名r0,最公平合理的初始排名是均勻排名
r0(Pi) = 1/n, i = 1, 2, …, n。
然後對k = 1, 2, 3, ... 如下操作排名迭代:
rk(Pi) = ∑ Pj ∈ I(Pi) rk−1(Pj)/|Pj|,i = 1, 2, …, n。
現在定義n階方陣P = [pij]ni,j = 1:對於i, j = 1, 2, …, n,若網頁Pi鏈接到網頁Pj,則令
pij = 1/|Pi|;
否則的話,定義pij = 0。顯見,P是非負方陣且每行元素之和等於1。換言之,P是n階隨機矩陣。此外,對於行向量
πkT = (rk(P1), rk(P2), …, rk(Pn)),
上述的迭代過程可以用矩陣乘法的形式表示:
πkT = (πk-1)TP, k = 1, 2, …。
如果下列極限存在的話,佩奇和布林將極限向量
πT = lim k→∞ πkT
定義爲網頁排序向量,而它的第i個分量πi則成爲網頁Pi的排名。
可是,要使得定義不被詬病,他們需要回答兩個問題:
1.這個原始的谷歌矩陣P是否存在對應於特徵值1的左特徵向量πT?若πT存在,歸一化(目的讓所有分量之和變成1)後的πT是否唯一?
2.當k趨於無窮大時,迭代向量序列πkT = (πk-1)TP的極限是否存在?若存在,那麼迭代收斂得多快呢?
現在用一個簡單例子說明思想。考慮一個僅有六個網頁的微型網絡,並使用原始的谷歌矩陣。

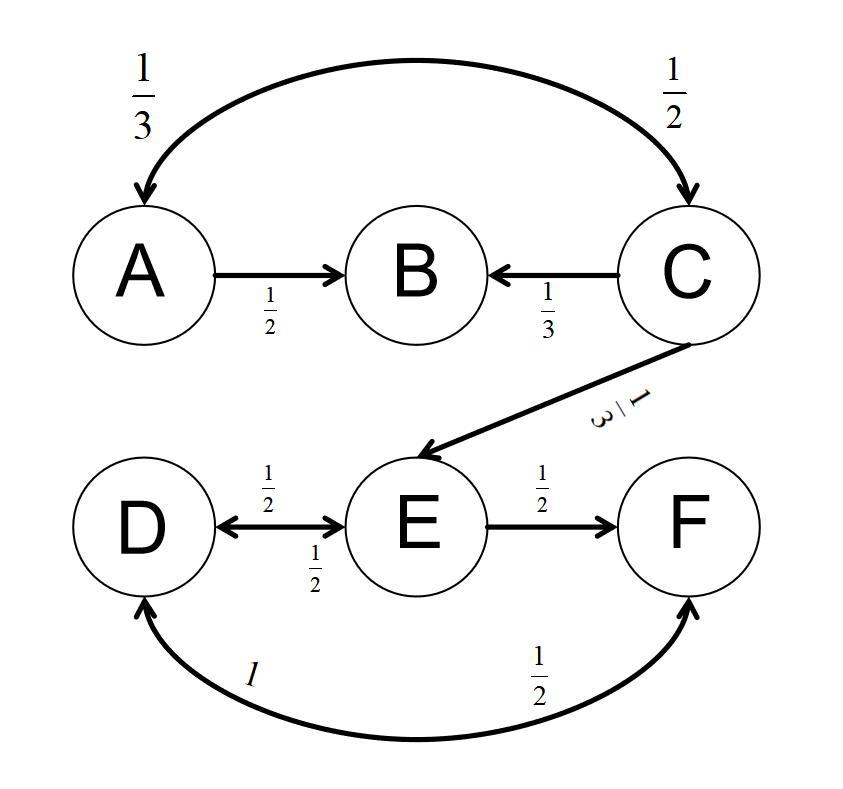
注意到矩陣的第二行元素全爲零,這是因爲沒有從第二個網頁(對應的有向圖節點叫做懸空節點)發出的鏈接。所以P不是一個隨機矩陣!
爲了補救,我們將第二行的每個元素加上1/6,便得到一個隨機矩陣S:
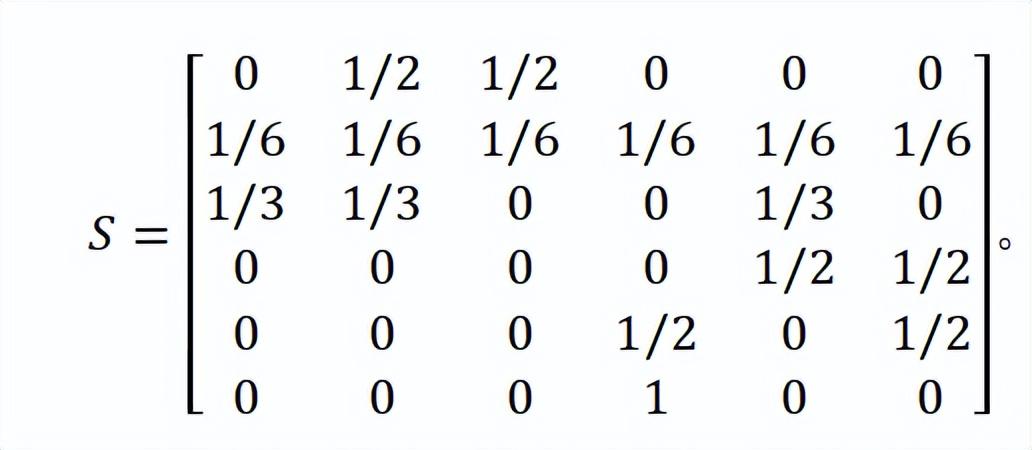
對於這個經過改造的矩陣,非負矩陣理論中最經典的一個定理派上了大用場,它以兩個德國數學家的名字命名——佩龍-佛羅貝爾尼斯定理,年輕的前者佩龍(Oskar Perron,1880-1975)於1907年對正矩陣,即每個元素均爲正數的矩陣證明了它,年長的後者佛羅貝爾尼斯(Ferdinand Georg Frobenius,1849-1917)五年後對所謂的不可約非負矩陣推廣了佩龍的結果。一個方陣稱爲是可約的,意思是說,可以將它的行和列以同樣的方式重新排列,其結果矩陣的右下角是個零方陣。譬如,2階及更高階的單位矩陣是可約非負矩陣。
即便上述的隨機矩陣S是可約的,一個經典的不動點定理——布勞威爾不動點定理卻能保證,存在歸一化的非負左特徵向量πT:
πT = πTS, πTe = 1。
這裏按習慣用字母e代表特殊列向量(1, 1, …,1)T。任意矩陣A乘以e,所得向量的各分量等於將A的那行元素加起來得到的和,故非負矩陣A爲隨機矩陣當且僅當Ae = e。
遺憾的是,上例中的隨機矩陣S雖然確保了網頁排序向量πT的存在性,卻由於它是可約的(因爲右下角是3階零矩陣),結果是歸一化的πT不能保證唯一且分量個個爲正。如果網頁排名不唯一,至少會造成網頁排序算法迭代不收斂或計算結果混淆不清。當今各種大學排名榜五花八門,結果千奇百怪,搞得大學當局有時高興有時發愁,就是排名不唯一的後遺症。
爲解決這一棘手問題,布林和佩奇引入了S的由參數α ∈ (0, 1)控制的一種“凸組合”擾動;例如,取α = 0.9,得到一個新矩陣:
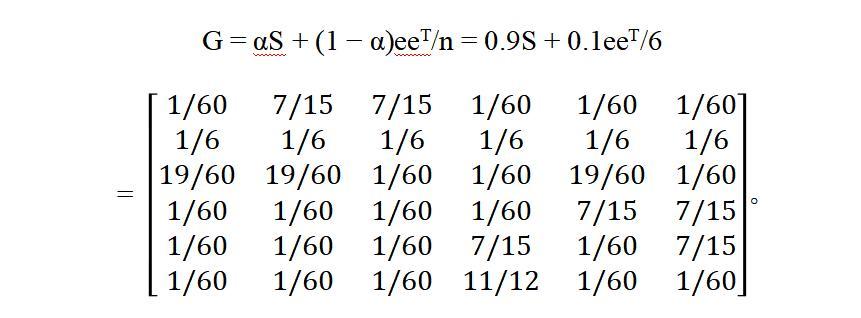
讀者一看就知道G是一個正矩陣。此外,它繼承了S是隨機矩陣的好性質,這一點的證明簡潔而明快:
Ge = (0.9S + 0.1eeT/6)e = 0.9Se + 0.1eeTe/6
= 0.9e + 0.1(eTe)e/6 = 0.9e + 0.1(6)e/6 = 0.9e + 0.1e = e。
這樣,按照佩龍-佛羅貝爾尼斯的非負矩陣理論,G不僅存在唯一的歸一化左特徵向量πT,其具體數值是
πT = (0.03721, 0.05396, 0.04151, 0.3751, 0.206, 0.2862),
而且正因爲這個網頁排序向量的所有分量均爲正數,它實實在在地提供了所給微型網絡總共6個網頁的排名。更重要的是,取定初始向量π0T = (1/6, 1/6, 1/6, 1/6, 1/6, 1/6),直接迭代法
πkT = (πk-1)TG,k = 1,2,...
計算出的歸一化向量序列{πkT}收斂到G的唯一歸一化左特徵向量πT。
有了上面的具體例子墊底,我們可以敘述谷歌矩陣的一般定義及其相應的網頁排序算法。如前,假設所有的網頁爲P1,P2,...,Pn,其對應的n階原始谷歌矩陣爲P。選取一個固定的n維“概率向量”
v = (v1, v2, v3, …, vn)T,
即v的所有分量都是正數,並且其和等於1,即vTe = 1。
將矩陣P的所有零行替換爲相同的行向量vT,得到隨機矩陣S。現在固定 參數α ∈ (0, 1)(早期谷歌公司使用過參數值α= 0.85),並將谷歌矩陣G定義爲S和evT的凸組合:
G = αS + (1 – α)evT。
G依然是個隨機矩陣:
Ge = [αS + (1 – α)evT]e = αSe + (1 – α)evTe
= αe + (1 – α)(vTe)e = αe + (1 – α)e = e。
更重要的是,由於S是非負矩陣,evT是正矩陣,它們的凸組合的係數小於1,這保證了G是個正矩陣。如此構造的矩陣G被稱爲谷歌矩陣。
萬事俱備只欠東風,現在可以敘述(但不證明)已超過一百年曆史的佩龍-佛羅貝爾尼斯定理在正隨機矩陣時的特殊結論了。
正隨機矩陣譜定理. 設A爲一n階正隨機矩陣。則存在歸一化的所有分量均爲正數的n維行向量πT,即
πT = πTA, πTe = 1;
滿足上述性質的πT是唯一的。此外,A的所有特徵值的最大模等於1,並且1是A在複平面單位圓上的唯一特徵值。更進一步,任給歸一化的n維非負初始向量π0T,迭代向量序列
πkT = (πk-1)TA = π0TAk,k = 1,2,...
收斂到πT。
譜定理告訴我們,對於佩奇和布林創造出的谷歌矩陣,上述這個被稱爲“冪方法”的迭代程式總收斂到網頁排序向量。又因爲谷歌矩陣規模巨大,冪方法只能是給全球有效網頁快速排名的唯一實用辦法。
收斂性問題圓滿解決後,關注谷歌用於計算網頁排序基本算法效率的讀者自然會問到“收斂得多快”的應用性問題。學過數值線性代數的人知道冪方法的收斂速率取決於矩陣所有特徵值中的次大模。現在我們用矩陣特徵多項式的技巧來尋找谷歌矩陣G所有的特徵值。
首先,因爲S是隨機矩陣,1是它的特徵值,特徵向量是e。記S的所有特徵值爲1, λ2, λ3, ··· , λn。則αS的徵值爲α, αλ2, αλ3, …, αλn。爲方便起見,令A = αS及u = (1 – α)e。則G = A + uvT。
設λ不是A的特徵值。從等式λI − G = (λI − A) − uvT,運用著名的矩陣行列式引理,即若B爲m階非奇異矩陣,且x和y爲m維向量,則
det(B + xyT) = (1 + yTB-1x) det B,
得到G的特徵多項式的表達式
det(λI − G) = [1 – vT(λI − A)-1u] det(λI − A)。
由於
(λI − A)u = (1 − α)(λI – αS)e = (1 − α)(λ − α)e
= (λ − α)(1 − α)e = (λ − α)u,
(λI − A)-1u = (λ – α)-1u,
隨即便有
1 − vT(λI − A)-1u = 1 − (λ – α)-1 vTu = (λ – α)-1[λ – (α + vTu)]。
從而得到
det(λI − G) = (λ – α)-1[λ – (α + vTu)] det(λI − A)。
因爲α + vTu = α + vT(1 − α)e = α + (1 − α) vTe = α + (1 − α) = 1,便有
det(λI − G) = (λ – α)-1(λ – 1) det(λI − A)
= (λ – α)-1(λ – 1)(λ – α)(λ – αλ2) (λ – αλ3)…(λ – αλn)
= (λ – 1)(λ – αλ2) (λ – αλ3)…(λ – αλn)。
這就證明了下列的定理:
谷歌矩陣譜定理.谷歌矩陣G = αS + (1 – α) evT的所有特徵值是
1, αλ2, αλ3, …, αλn。
由於每個λi位於單位圓的內部,故
|αλi| < α < 1, i = 2, 3, ..., n,
因此冪方法的收斂速率取決於參數值α的大小。這個值如果取得靠近(0, 1)開區間的右端點,冪方法的迭代步伐就會慢下來;反之,若將它取得太小,甚至靠近(0, 1)的左端點,G又與折射出真實網絡世界各網頁之間“朋友關係”的S相距太遠,這樣計算雖然快了,但結果或許有不能全方位反映真實世界之危險。總之,選擇參數α的數值要顧及到準確與速度的雙重思量。
就數學而言,上面的谷歌矩陣譜定理是下面的秩-1矯正矩陣譜擾動定理的一個特殊化。這個一般結果是筆者之一20年前在一篇合作文章中證明的。
秩-1矯正矩陣譜擾動定理. 設A爲一n階矩陣,其特徵值是λ1, λ2, ..., λn。若u和v爲兩個n維向量,其中u是A對應於λ1的特徵向量,則A + u vT的特徵值是λ1 + vTu, λ2, …, λn。
將上述定理中的A取爲谷歌矩陣譜定理中的αS,u取爲(1 – α)e,則如前所述,A的特徵值是α, αλ2, αλ3, …, αλn,且u是A對應於α的特徵向量。則秩-1矯正矩陣譜擾動定理給出G = αS + (1 – α)evT的第一個特徵值爲
λ1 + vTu = α + (1 – α)vTe = α + (1 – α) = 1,
而αS的特徵值αλ2, αλ3, …, αλn通通留給了G,得到谷歌矩陣譜定理的結論。
過去四分之一個世紀,PageRank 算法不僅成就了一家商業巨頭,更深刻改變了人類獲取信息的範式。儘管在今天,隨着人工智能的演進和網絡生態的更迭,傳統搜索引擎的形態正經歷劇烈的陣痛與重塑,但其背後的數學邏輯——通過矩陣刻畫關聯、用特徵值尋找秩序——依然是處理海量數據的核心思想。今天正值國際數學日,回望這個“世界最大矩陣”,我們感嘆的不僅是算法帶來的便利,更是數學作爲一種普適語言,在紛繁複雜的現實世界中剝離混沌、指引真理的純粹力量。