全球最大!上海發佈萬億參數科學大模型,國產算力築底,數物化生“通喫”




科學智能(AI for Science)領域又迎來里程碑式的“上海時刻”。2月4日晚間,上海人工智能實驗室宣佈,開源全球首個基於“通專融合”架構的萬億參數科學多模態大模型——Intern(書生)-S1-Pro。這是全球開源社區中參數規模最大的科學模型,其性能表現穩居全球第一梯隊,標誌着科學智能正從“工具革命”的1.0時代,跨入由“革命性工具”驅動科學發現的2.0時代。
既見“沙粒”,亦見“沙丘”
在人工智能(AI)領域,模型的參數規模往往決定了其“腦容量”。此次發佈的全新書生科學模型,總參數量達到驚人的1萬億(1T),刷新了行業紀錄。然而可貴的是,如此巨大的參數規模,並沒有讓模型變得過分“笨重”。
據介紹,書生萬億科學大模型採用了創新的混合專家架構(MoE)。形象地說,其內部相當於有512位各領域“頂尖專家”坐鎮,每當面對具體的科學問題,系統會精準調用最合適的8位“專家”,一起參與分析決策。這種“按需點將”機制,使這個萬億模型只需要激活大約2%的參數(220億),就可以從容應對複雜數理邏輯推理。
更精妙的是,書生萬億科學大模型,還通過底層創新,使得模型實現了“物理直覺”的跨越。據介紹,相較於處理語言,AI模型在解決科學問題時會遭遇很多新的挑戰。尤其是語言的“字符間距”、或者說“數據密度”相對穩定,但科學領域卻絕非如此——天文學家們往往要從洪荒中努力捕捉極其渺茫的信號,而生命科學卻往往能在一個實驗裏採集到百萬級的數據。爲此,上海人工智能實驗室引入“傅里葉位置編碼(FoPE)”並重構“時序編碼器”,像是爲大模型賦予了“雙重聽覺”——既可以在微觀上感知單個音符,又可以在宏觀上欣賞整個樂章;亦或者說,這種機制讓模型也擁有了“雙重視覺”,既可以直擊“沙粒之棱角”,也能眺望“沙丘之綿延”。
根據上海人工智能實驗室主任、首席科學家周伯文的構想:“通專結合”是實現通用人工智能(AGI)的可行方案。而此次開源的書生萬億科學大模型,實際上就通過一系列底層創新,爲這一構想的落地提供了現實的路徑。
書生萬億科學大模型界面。
能力橫跨五大學科
基礎層的創新,已經支撐書生萬億大模型在實戰中初步顯現出過人實力。可以說,它不僅能“解題”,更有潛力“解決問題”,提升科研生產力,併爲前沿科學探索提供堅實支撐。
在國際數學奧林匹克(IMO-Answer-Bench)和國際物理奧林匹克(IPhO2025)兩大權威基準測試中,書生萬億科學大模型讓人看到了競賽級別的解題能力。在科學智能的其他若干關鍵垂直領域,它同樣表現出色;不僅是單學科成績優異,更是在SciReasoner等高難度的綜合學科評測基準中,取得了與頂尖的閉源商業大模型相當、甚至更優的成績,穩居第一梯隊。
總體上,書生萬億科學大模型已經成功構建了一個橫跨化學、材料、生命、地球、物理等五大核心學科的全譜系能力矩陣,涵蓋100多個專業子任務,可以在許多領域成爲科學研究重要的貢獻者。比如,它能精準解析複雜的分子結構圖和各類實驗圖表;能夠通過邏輯推理,開展理化性質預測,捕捉數據背後的因果規律等高階科學活動。
未來,隨着理解與推理能力的增強,該模型的“能力邊界”還將進一步向真實的科研場景延伸。據上海AI實驗室介紹,其應用範圍將從微觀的化學逆合成、蛋白質序列生成,拓展到宏觀尺度的遙感圖像分析等複雜任務。
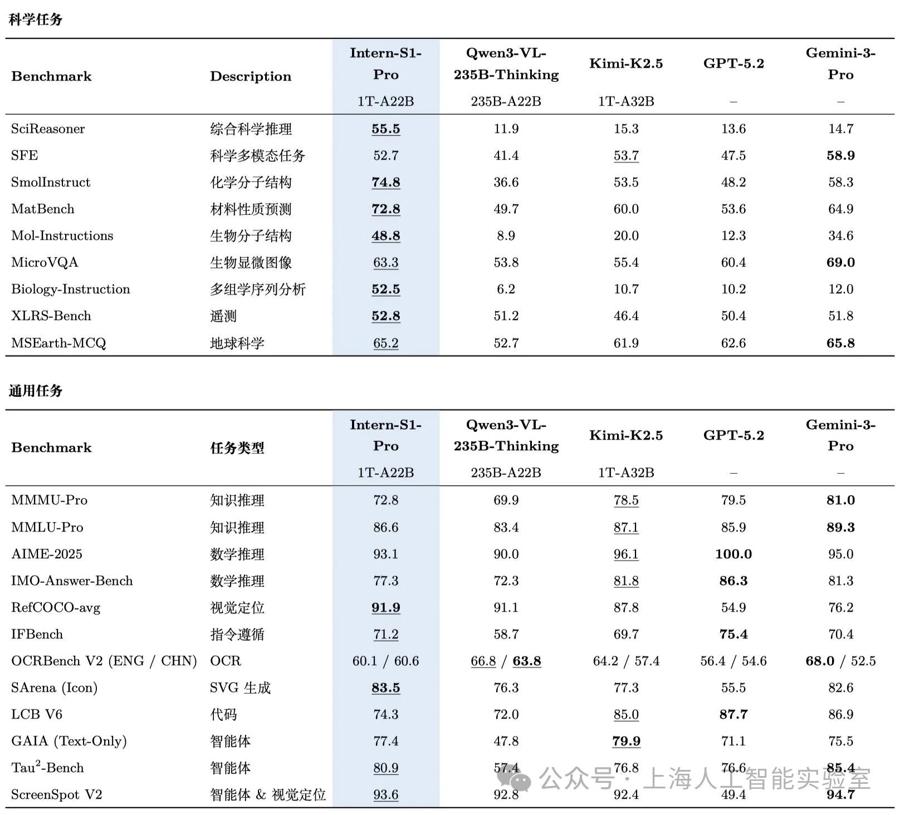
書生萬億科學大模型在各評測基準中表現出色。
深度融入國產生態
大模型的應用成效,受制於算力、算法、數據等多維度因素。書生萬億大模型不僅有算法層突破,更在算力層面努力實現國產自主技術的全鏈路集成,以築牢“算力-算法”的一體化基座。
據上海人工智能實驗室介紹,在基礎研究層面,他們藉助“路由稠密估計”“分組路由”等策略,能像智能交通系統一樣對海量的計算芯片負載進行均衡,再加上算法與系統的協同創新,從而攻克了超大規模模型訓練在“學習效率”和“資源調度”上的核心瓶頸。
值得一提的是,在模型架構設計之初,上海人工智能實驗室便與昇騰計算生態確立了聯合研發路線,實現了從最底層的算子優化到上層的訓練框架的深度適配。而在大規模訓練中,研發團隊攻克了精度對齊、硬件性能極致釋放等一系列核心技術難題,結合先進的內存管理與並行策略,確保了萬億參數模型訓練的高效與穩定。目前,研發團隊還與另一家國產芯片代表企業沐曦開展了聯合研發,爲進一步構築開放共享、面向未來的科學智能基礎設施奠定了堅實基礎。
據介紹,目前,包括大語言模型、多模態模型、強推理模型在內的書生系列大模型及全鏈路開發工具在內的開源體系,已吸引全球數十萬開發者參與。下一步,上海人工智能實驗室將持續推動全鏈條開源與免費商用,進一步降低全球科研門檻,與全球學術界和產業界一道,打造一個更開放、更高效且面向未來的科學人工智能生態。

















