中國AI進入“深水區”,基礎模型與智能底座同步邁向原生時代

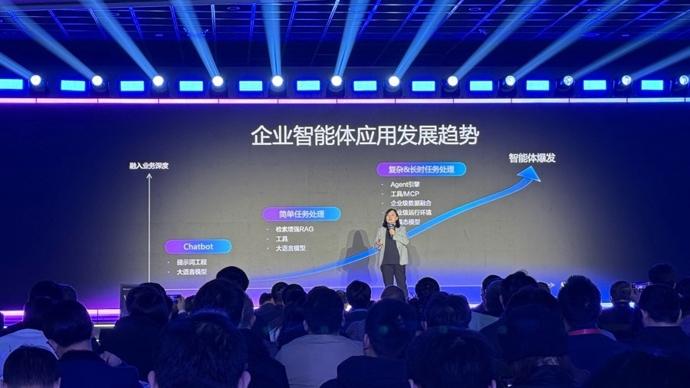

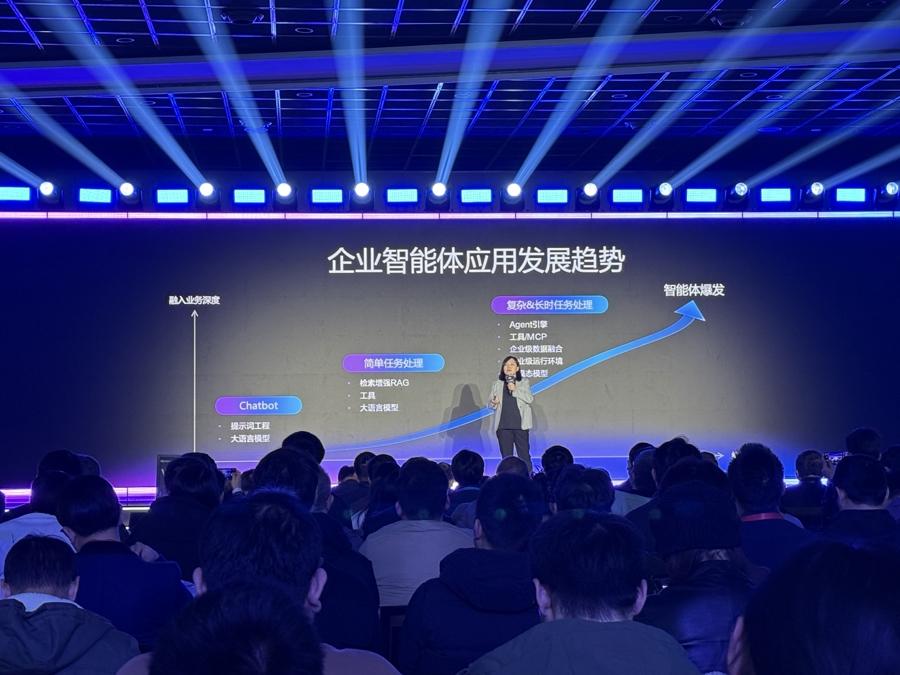
進入2026年,中國AI產業格外熱鬧。百度與阿里雲兩大科技巨頭,在短短數日內相繼拋出重磅技術進展,從單純的參數競賽或應用展示,轉向了更爲根本的“原生”與“內生”能力構建。
原生全模態:文心大模型尋求“統一”的智能
1月22日,百度上線了文心5.0正式版,最引人注目的標籤是2.4萬億的龐大參數規模以及 “原生全模態” 的技術路線。與行業中常見的將文本、圖像、語音等模態分別訓練再“拼接”融合的方案不同,文心5.0選擇了一條更具挑戰性的道路:採用統一的自迴歸架構,讓文本、圖像、視頻、音頻等多源數據在同一模型框架內進行聯合訓練與優化。

這種從底層設計上的統一,目標在於實現多模態特徵更深度的融合與協同。百度集團副總裁吳甜現場展示了一個案例:僅輸入一段講解如何復刻“活了麼”App的視頻,文心5.0便能自動拆解步驟、理解交互邏輯,並直接生成可運行的前端代碼,超越簡單的“看圖說話”,展現出對跨模態信息的複雜推理與生成能力。
在性能評測上,百度透露,在涵蓋語言與多模態理解的40餘項權威基準測試中,文心5.0正式版已超越GPT-5-High、Gemini-2.5-Pro等國際頂尖模型,穩居全球第一梯隊。其圖像與視頻生成能力也與垂直領域的專精模型相當。
除了架構創新,文心5.0還通過超大規模混合專家結構(MoE)提升推理效率,並強化了智能體與工具調用能力。百度還推出 “文心導師”計劃,吸納了835位跨行業、跨學科的專家,從知識、評價、校準等方面對模型進行持續“教導”,這或許是在追求極致性能參數之外,確保AI專業性、可靠性乃至價值觀對齊的更深層佈局。
內生智能:大模型能力從“外掛”變爲“內生”
幾乎在同時,阿里雲則在數據庫領域掀起了一場“AI原生”革命。1月20日,在PolarDB開發者大會上,阿里雲發佈了全面內化AI能力的一系列新產品,核心是 AI數據湖庫(Lakebase),並明確提出了 “AI就緒數據庫” 的四大核心支柱。
阿里雲資深副總裁李飛飛指出,數據庫正經歷從“雲原生”到“AI就緒”,再到“AI原生”的必然演進。PolarDB此次的突破,旨在將大模型能力從“外掛”變爲“內生”,讓數據庫不僅能存儲和查詢多模態數據,更能直接驅動智能決策。

具體而言,其四大支柱包括:多模態AI數據湖庫,實現結構化、半結構化、非結構化數據的統一管理;高效融合搜索能力,在SQL中深度集成向量與全文檢索,融合語義與關鍵詞匹配;模型算子化服務,支持庫內推理、Agent長短時記憶機制,讓數據“活”起來參與計算;以及面向Agent應用開發的一體化後端服務。
這意味着,開發者可以在數據庫內部直接完成對圖片、文檔等非結構化數據的語義檢索與推理加工,無需在多個系統間頻繁導出導入數據,極大提升效率的同時,也保障了數據隱私與合規性。PolarDB正試圖將自己從被動的“數據倉庫”,轉變爲主動的“智能數據引擎”。
目前,PolarDB已服務超2萬用戶,覆蓋金融、汽車、互聯網等關鍵行業,其“AI就緒”的理念已開始在理想汽車、小鵬汽車、米哈遊等企業的核心業務中落地探索。
深水區競速:從應用創新到架構定義
百度文心5.0與阿里雲PolarDB的發佈,看似分屬大模型與數據庫兩個賽道,但都指向中國AI產業當前競爭的新維度。
專家表示,從近段時間的趨勢來看,自主技術路徑的深化已經成爲大勢所趨,無論是百度的“原生全模態統一建模”,還是阿里雲的“AI內生數據庫”,都展現出在基礎技術路線上進行探索和定義的決心:“這關乎長期的技術話語權與產業主動權。”
此外,從“能用”到“好用”的跨越,也是此輪升級的關鍵點。記者獲悉,雙方都致力於解決AI落地的實際痛點。比如,文心5.0通過工具調用和代碼生成降低開發門檻,PolarDB通過簡化數據流程和庫內計算來提升效率、保障安全。競爭焦點正從炫技轉向提效。
中國AI產業已駛入“深水區”,短期的話題熱度不再有光環,單純的應用場景開拓需有堅實且自主的底層架構作爲支撐。專家表示,中國科技企業正在同時攀登“智能高度”與夯實“智能地基”,這將深刻影響全球AI產業格局的未來走向。

















