海外殺瘋!階躍語音模型 CES 出圈後登頂全球第一,聽到對話即可思考


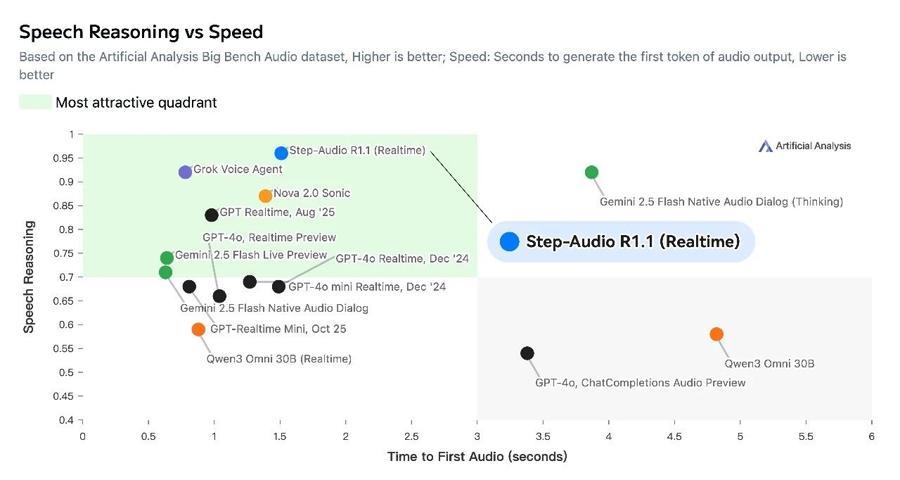
全球知名權威大模型評測榜單 Artificial Analysis Speech Reasoning 更新,大模型創業公司階躍星辰原生音頻推理模型 Step-Audio-R1.1以96.4%準確率,超越 Grok、Gemini、GPT-Realtime 等主流一線模型,刷新歷史最好成績。目前,階躍星辰已將這款模型開源,開發者可以下載體驗。
據瞭解,該榜單是目前業界評估“原生語音模型”(Native Audio Models)最權威的第三方基準之一。核心考量模型直接處理音頻並進行復雜邏輯推理的能力,主要考察維度包括準確率、首包延遲等。

根據榜單評測,在性能與速度的綜合權衡上,Step-Audio-R1.1 全面碾壓同類語音模型。
2025年11月,階躍星辰發佈了全球首個開源原生音頻推理模型 Step-Audio-R1,可以在不增加額外時延的情況下,端到端理解語音內容,並能夠“像人類一樣聽到對話即可思考”。這次發佈的 Step-Audio-R1.1 模型,是Step-Audio-R1的升級版,兼顧更強實時對話和複雜語音推理能力。完整的實時語音API將在2月上線,目前開放的chat模式已搭載Step-Audio-R1.1核心,支持邊想邊說的流式推理。
和大語言模型同理,語音模型同樣需要具備強大推理能力,才能提供更高階智能、更自然交互。基於推理能力,Step-Audio-R1.1不僅能準確識別聲音,還可以捕捉到聲音背後的情緒和心理狀態、言外之意,並能基於環境音推導對物理世界的理解。比如當聽到最近爆火網絡的“海豹舞”音頻時,模型不僅能識別出韓語歌詞,更判斷出這是典型語言學習或發音練習的音頻,而非自然對話。
一種行業共識是,語音是終端場景下最主流的交互方式。自2025年發力“AI+終端”戰略,階躍星辰相繼發佈了業內首個產品級的開源語音交互模型 Step-Audio、端到端語音模型 Step-Audio 2 系列、音頻編輯模型 Step-Audio-EditX、全球首個開源原生音頻推理模型 Step Audio R1。
在剛閉幕的 2026 年國際消費電子展(CES)上,吉利展示了搭載階躍語音大模型的吉利銀河 M9 海外版,憑藉極具真人感的交互效果引發海外觀衆的熱議。吉利銀河 M9 也是業內首個搭載端到端語音模型的量產車型。

















