米哈遊騰訊投的AI獨角獸火出圈,背後竟有心動的人?
年關將至,AI業界卷王輩出,好幾家公司都在最近拿出了重量級的大模型。雖然很熱鬧,不過放在平時,你可能會覺得這和遊戲公司沒什麼太大的聯繫。
但這次的情況不太一樣:在被稱爲「新一代國產LLM之光」的大模型背後,我們聽到一個特別神奇的,和遊戲行業有千絲萬縷聯繫的故事。
1月15日,MiniMax發佈了公司首個開源模型——MiniMax-01系列,首次在4000億以上參數的大模型中,使用了不同於傳統Transformer架構的線性Attention機制架構,能高效處理的上下文長達400萬token,達到了全球最長的水平。

這個成果是什麼概念?你可以理解爲,MiniMax大膽地在商用級別規模上,驗證了一條前人沒走通的路,結果不僅讓AI大模型的“記憶”被延長到了一個相當可觀的程度,且成本還比GPT-4o低10倍。所以海外不乏對MiniMax-01的熱議甚至讚美,還有人稱其爲“來自中國的AI變革”。
與此同時,也有人從MiniMax發表的論文中注意到,這次突破所使用的核心架構——以Lightning Attention爲主的架構,早在數年前就有人開始發表相關論文。這個人叫秦臻,他的框架理論從2022年到2024年不斷更新,第一作者全是他。在新模型的相關論文中,MiniMax大量引述了他的研究成果。
這就引出了第一件神奇的事:有人順藤摸瓜,發現秦臻竟然並非AI創業公司的人,而是在心動 TapTap 增長和商業化部門(IEM)下的AI團隊擔任算法研究員,研究高效序列建模方法。
更巧的是,MiniMax這家成立於2021年的AI獨角獸,背後也站着遊戲公司:2023年,米哈遊、騰訊都曾參股MiniMax,次年米哈遊又追加了一輪投資——不過,這真的只是巧合,和背後遊戲公司的關係毫無關聯。因爲MiniMax也一直在研究線性Attention這條路線。只不過秦臻的研究成果,恰好爲他們提供了重要的理論支撐。
問題在於,心動不能說和AI毫無聯繫,但也實在沒太多牽扯;即便有所涉獵,研究條件、深度想來也很難比得上專業AI團隊……他們爲什麼會招到這樣的人?爲什麼會搞出這樣的研究成果?
通過心動,葡萄君聯繫上了秦臻,以及他的同事,TapTap IEM AI算法組的Leader 賴鴻昌。
他們聊到了第二件神奇的事:秦臻此前在商湯科技工作,在小組被解散之後,他也曾向各種大廠投遞過簡歷。但他沒選擇資源豐厚的大廠,最終卻和TapTap來了個雙向奔赴。
在AI領域,TapTap 倒是很早就有所行動,負責人戴雲傑早在2021年就於Slack上表示過,要關注相關技術、推動投入研究資源。

但光看團隊背景的話,這依然有點不可思議——一直以來,TapTap 的AI部門實際上沒有所謂的“主線任務”,公司只是抱着長期主義的態度,覺得AI值得提前探索和投入,因此對團隊也沒有太多要求,只是鼓勵他們多做一些探索性的嘗試,無論是做算法設計,還是結合App、遊戲。爲了讓團隊安心探索,據說他們還有一條制度:無論產出如何,都不會存在M-績效。
而秦臻的存在就顯得更爲特殊:部門的算力資源當然比不上大廠,能支持他做研究的顯卡不多,雖然可以小規模驗證想法,但肯定支撐不了商用級別規模的LLM驗證;公司角度呢,秦臻研究的線性Transformer架構,實際上也和心動的遊戲業務沒有太大聯繫,很難說會對業務增長有真正的幫助。
但第三件神奇的事,卻正是由這些神奇的人和事彙集而成:在業務關聯不大的情況下,TapTap一直支持着AI部門的探索,秦臻也堅持把線性Transformer架構鑽研了下去。最終,他的多篇論文被髮佈於頂刊,被持續研究相關技術的MiniMax引用、發揚光大,做出了國產LLM的一次重要嘗試和突破。
和他們聊過之後,我更加覺得,少了任何一個巧妙的因素,這件事可能都發展不到這個地步。但有時候,這種重大的突破,可能就是和遊戲研發一樣,需要更多的耐心、更包容的環境以及長期主義,來支撐那些有動力堅持探索的人,去把有價值的事做下去。
就像秦臻和我們說的,他相信:如果你做的事真的很有價值,最後一定會有它被用上的一天。
以下爲對話的內容實錄:
01
大廠難落地的項目,
換個地方生根發芽
葡萄君:你是怎麼來到TapTap的?
秦臻:在上一家公司的小組解散後,我看過一些大模型公司和大廠的機會。我那時的目標還不是很明確,但對之前做的線性Attention方向比較感興趣,也比較擅長這件事,所以就想找個地方繼續研究。
2023年初聊下來一圈,我感覺大廠唯一的好處就是資源會更多,但規章制度會相對死板,給你的自由發揮度比較小。和TapTap聊過之後,我覺得這邊會提供一個相對寬鬆自由的氛圍。客觀來說,對於做Research這件事,TapTap提供的算力也絕對充足——因爲即使在大廠,這件事也很難推動。綜合考慮,我最後選擇了TapTap。
葡萄君:是不是大廠們不太關注這個方向,你們聊不到一塊?
秦臻:我一般都會介紹我做過的一些工作,大部分人也算是有興趣,但真正指望落地還是比較困難的。因爲當時算是大模型的混沌階段、古早時期,大家可能還是想先追趕LLaMA之類的模型。
葡萄君:線性Attention在早期的潛力還沒有被驗證,那時會不會有面試官覺得你在吹牛?
秦臻:還好,因爲學術論文的論點不會那麼大,只是表明它會在某些場景下可能有優勢,沒人會想着用這個替代大模型。而且論文總歸會有一些亮點,否則也發不出去。
葡萄君:AI大廠都涉獵不深,TapTap爲什麼會接觸到這種技術?
賴鴻昌:2020年GPT-3面世時,TapTap 負責人戴雲傑就關注到了大語言模型,並開始思考技術突破可能帶來哪些新的變化。在2023年,必應發佈了第一款GPT應用New Bing後,TapTap 也嘗試做了類似的遊戲AI交互式搜索。
戴雲傑早期對GPT-3的關注
後來開始在市場上篩選目標候選人,招聘了大半年都沒有合適的簡歷,直到後來篩到了秦臻。
當時我們的感受是,秦臻有很好的學術審美,知道自己該做什麼。這個方向雖然與業務沒有直接關聯,但是最關鍵的事是要follow前沿,保持與學術、工業界的交流,不要掉隊。所以我們決定,一定要有一個這樣的人才來帶着我們去做一些前沿研究。
葡萄君:你們聊得怎麼樣?
賴鴻昌:雙方都很愉快,很快就敲定了。他講的線性Attention,我們大概能get到。而且這個研究成本我們能cover住,也能很好地follow到學術前沿。
另一方面,做這個方向的人本來就不多,而秦臻可以說就是專家,也有很強的自驅力。如果他真的跑通了,即使TapTap不能落地超大參數量模型,我們也可以用相對可控的成本,去做一個可能符合自己業務場景的模型,這是一個長遠規劃。
葡萄君:公司給你的資源真的夠用嗎?
秦臻:對於做Research來說,絕對是充足的,很多高校的實驗室,據我所知一般都沒有這種資源。只不過你要大規模驗證,又是完全不夠用的狀態。
這就是心動和大廠的一個區別——你在大廠可能能得到很多資源,但是發揮空間很小。而且因爲人很多,你一次性能調動的資源,可能沒有想象的那麼多。比如一個組內大幾千張顯卡,但首先訓練大模型的人佔了大部分,幾個組一分,到最後你自己探索的卡,可能也就是百張的量級,沒有本質的區別。
賴鴻昌:我們團隊也認真討論過,有這些卡夠不夠、用來幹嘛,以及要不要加。
討論的結果是,我們需要剋制地去看待和發展AI,讓自己不會掉隊,而不是要一開始就梭哈AI。正是這種剋制,才使得秦臻最後能跑出來。我們比的不是誰資源更多,而是誰能做得更久。
葡萄君:在這麼混沌的領域搞探索,你們團隊會覺得迷茫或艱難嗎?
賴鴻昌:無論是我們還是其他人,在做AI應用的情況下,都會有點迷茫的。你會發現在技術上、落地上,都有很多的不可行,投入產出都需要評估,這對一個獨立團隊來說是比較痛苦的。
在秦臻來之前,我們做過各種應用探索,沒有特別明確的主線,也是因爲大部分事情都無法成爲主線。
葡萄君:未知數太多,可能是AI研究魅力和痛苦的共同來源。
賴鴻昌:是的,所以去年,我們團隊的Leader李昀澤定下了基調,他期望大家按照自己的興趣去研究。先有了符合自己認知的需求和場景,再去實現落地,方向就會變得明確。而且我們團隊和公司給的氛圍,也是以自由度和自驅爲主,讓專業的人去做專業的事。這也比較符合心動與TapTap的文化。
02
你不可能永遠領先,
但也不會永遠落後
葡萄君:MiniMax的大模型,實現了上下文400萬token,這是什麼樣的一個概念?
秦臻:技術背景上,Transformer的核心模塊是Attention,它的複雜度和上下文長度是平方關係,也就是說400萬的長度,需要400萬平方的算力成本。之前大家不會做那麼長,根本原因就是成本扛不住。
但假設你把Attention換成線性的,成本會變成400萬。而MiniMax使用混合模型後,線性比例是7/8,也就是說它的成本約等於(7/8×4000000)+(1/8×4000000^2),這遠遠低於純Attention的成本。
另外,能訓到這麼大,意味着它有Scaling能力。一直以來沒有公司去做這件事,就是因爲擔心Scaling會失敗,這樣你訓練的那些成本可能就白費了,所以MiniMax能付出這樣的勇氣去走通這條路,還是非常有前瞻性、讓人敬佩的。
葡萄君:這件事的實現,可能對AI發展有什麼樣的影響?
秦臻:從去年年初到年中,混合模型在學術界一直有所討論,但規模一般都不是特別大,大概就是LLaMA 7B、13B的級別。大模型團隊肯定也有業績壓力,訓一個月模型,最後發現不work?大部分人都沒有勇氣做這種事。
現在MiniMax可以說是跑通了,之後大家可能會去復現這個事情。同時它也會引起工業界的關注度,因爲之前大家會覺得,相比真正的大模型來說,線性Attention還是一個學術玩具級別的東西。但是當一家公司把混合模型在商用規模上跑通之後,事情就不一樣了。
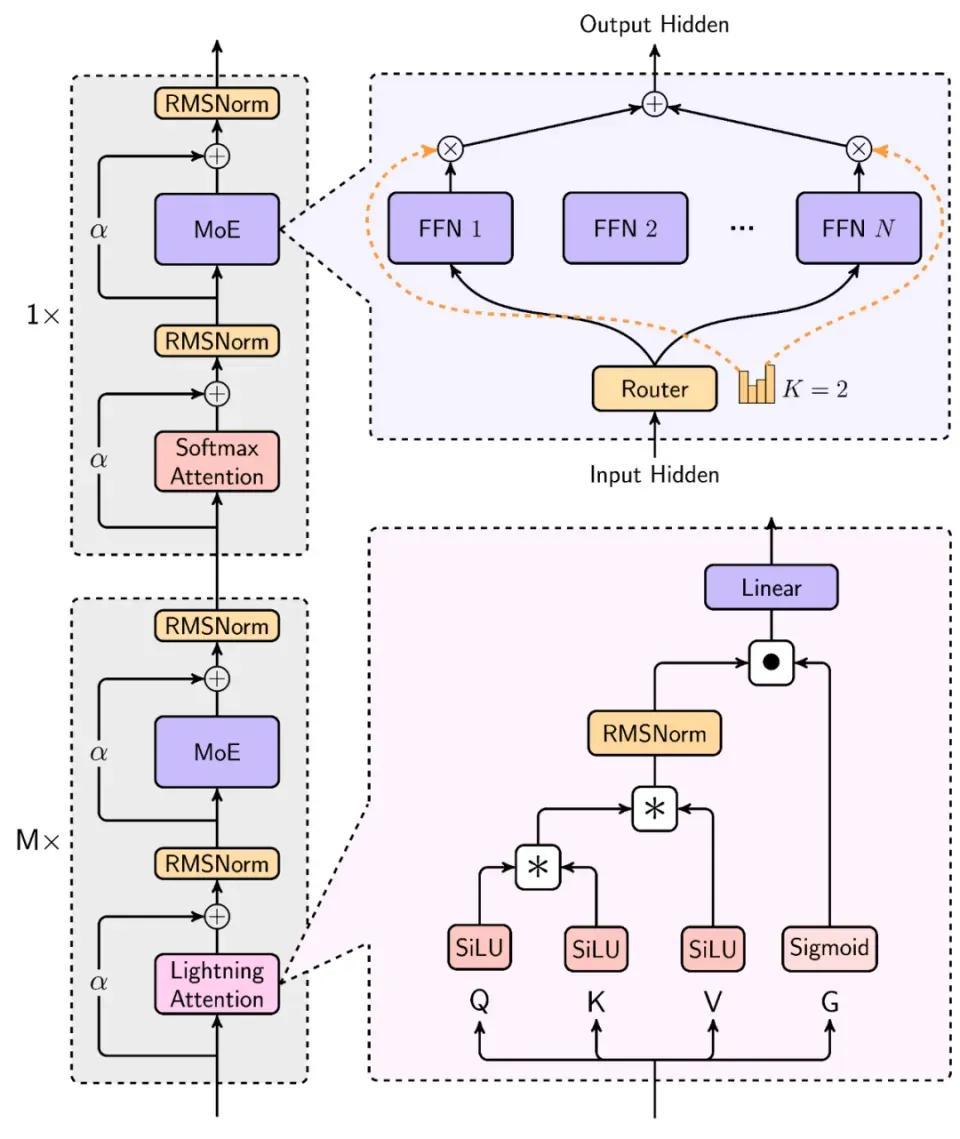
MiniMax 01模型的混合架構
葡萄君:它能降低的成本,大概是一個什麼樣的量級?
秦臻:理論上,假設之前的成本是N^2,現在則是(1-P)*N+P*N^2,這個P你可以取得很小。在P=1/8的時候,它看起來還沒有降得特別明顯,但假設P=1%,你的N又比較長,可能就會降100倍。
葡萄君:基數越大,省得就越多。
賴鴻昌:是的,大模型的參數,平方關係下很容易乘數爆炸。400B的模型,再平方一下就是天文數字。所以大家爲了降低成本做了很多工作,從FlashAttention到線性Attention,都是爲了把複雜度降低,先有理論上的可能,最終變成實際工業中可投產的技術。
葡萄君:秦臻是從多早開始關注這種技術方向的?
秦臻:從2021年下半年開始,我在上一家公司就在做這個方向,到現在已經三年半了。也是機緣巧合,在幾條路線中正好選到這個方向。中間一段時間,我嘗試過其他方案,最後發現有的方案不太行,有的方案是殊途同歸,最後還是選擇了線性Attention。這個方法它首先比較有趣,其次複雜度也是最低的,後面就一直做下去了。
葡萄君:有趣在哪?
秦臻:在算法設計上,它是一個普適的想法,能應用到很多乍一看不相關的領域,相當於你不止研究了算法,還學會了一種設計思路。另一方面,研究這個領域,也能讓我和那些喜歡這種算法之美的有趣同行交流。
葡萄君:線性Attention方面的研究成果,這幾年你是如何思考研究方向的?
秦臻:大家公認的第一篇提出線性Transformer的論文,是在2020~2021年間發佈的。大概從這時到ChatGPT面世之前,將近兩年時間,相關文章都搜不到幾篇。大家對這塊的理解也不夠深——現在很多人知道的Mamba模型,它的核心是狀態空間模型(State Space Model, SSM),也是21年左右提出雛形的,現在看來和線性Attention是一個東西,只不過那時候大家互不知曉。
到2023年ChatGPT面世,線性Attention的關注度逐漸上升了一點。Lightning Attention就是在2023年下半年開始做的,同期也有不少類似的工作,包括Mamba,我看到之後,就感覺這個東西后面肯定會火,只是它火的程度超出我的預期了。
在那段時間,我發現所謂的線性Attention以及另一個小方向,叫Linear RNN和SSM其實都是一回事。雖然設計時有區別,但最後在計算邏輯上基本完全等價。
這個發現讓我有點開心,也有點擔心。開心在於,如果說你從很多不同方向去研究一件事,發現最後的方案收斂了,那收斂的結果應該是蠻有價值的;而擔憂在於,如果未來大家都一樣了,後面的區別到底在哪裏呢?
之後直到2023年底,我也嘗試訓練過線性Attention架構。雖然那時有幾個團隊,能把線性Attention做到7B、13B這種規模,但是距離真正的LLM,肯定還是有差距的。
葡萄君:做不起來的主要問題出在哪?
秦臻:我當時的認知是,檢索是推理的前置條件,我們一般讓模型有推理能力會通過添加很長的Prompt(即CoT),而Prompt起作用的前提是模型能完整記住prompt的內容。假設你輸入一個很長的Prompt,模型只能記住後面20%的位置,你這個Prompt就相當於幾乎沒起作用。
我試過一些市面上開源的線性Attention模型,也試過自己設計模型,發現檢索能力都比較弱。做到這個時候,就感覺路還蠻難走的,因爲當時既不知道線性Attention的未來是什麼樣,又發現它有這樣的問題,所以一度感覺走進了死衚衕。
葡萄君:行業可能也對這個方向信心不足。
秦臻:關於這個領域的未來,我自己也不清楚——你能不能拿固定大小的東西,記住任意長度的上下文?這個問題看起來是不太實際的。悲觀派就覺得,有限大小的東西,記憶能力肯定是有限的;樂觀派一方面覺得,記憶的大小、空間可能沒有你想的那麼小,還有些人會拿人腦的儲存量與記憶能力做類比。
所以純線性Attention能不能做所謂的推理檢索任務,這應該是個開放問題,可能樂觀一點的人還會去嘗試。
葡萄君:你算是樂觀派嗎?
秦臻:我不算樂觀,但我肯定不悲觀。如果你想到比較有意思的idea,發現沒人做過,那至少試了才知道行不行。
賴鴻昌:技術發展往往是螺旋上升,總會有一些去修正與改進,也不是說所有研究都要一條道走到黑。從Transformer最早發佈到現在,也有很多新的變化。
葡萄君:在這幾年的研究中,你有沒有碰到什麼巨大的難點?
秦臻:剛入門和入行比較久之後都碰到過。剛入門時碰到的問題是缺少idea,但這個階段還還比較好解決,因爲啥都不懂,接近白紙的狀態,儘管你會沒有什麼想法,但是多讀同行的論文就行,至少會有一些嘗試的新方向。
因爲理論上,一個領域A的方案也可以借鑑到領域B。閱讀量大了之後,你只會存在一個問題,就是有沒有時間去嘗試、到底要試哪個,因爲時間是有限的。
入行比較久之後,又是另一種艱難——你看不到太多新東西了。鑽研一兩年之後,發現大家都在同一個水平線上,你從別人的論文裏得不到太多靈感。這時你可能會去看看古早時期的論文,像RNN這個領域,上世紀六七十年代的論文都有,但看多之後,又會發現好多所謂的新東西,其實是幾十年前的翻新。
在這個階段,我感覺沒有太多新的思路可以做。或者說有一些新的,同行已經在做了,我現在去做意義也不大。那段時間還是有點悲觀的,感覺純線性好像又沒什麼用,那做什麼呢?
葡萄君:你是怎麼走出來的?
秦臻:有很多同行也在做類似的事,多看幾遍之後,確實會有一些新的靈感。你不可能永遠領先,但也不會永遠落後。只要一直保持探索、進一步去閱讀,大家總歸會在類似的水平線上交流的。
賴鴻昌:這很像剛纔那個心態問題,我們做AI探索,一開始會很興奮,那個時候可以說是真的愚昧之巔。到了去年,可能都落到了絕望之谷,這樣的曲線在我們行業很常見。我們也經常會陷入自我否定、自我懷疑,但是又繼續去閱讀找靈感的狀態。
反正不管是應用還是研究,應該都是慢慢打磨出來的,急躁的心態很難做好。
03
堅持做有價值的事,
一定有獨特的意義
葡萄君:你們覺得MiniMax爲什麼會先人一步注意到這種技術選型,還把它在這麼大的一個規模上實現了?
秦臻:可能因爲他們是在大模型浪潮之前創立的公司,這類公司的特點就是,相比於浪潮之後的公司會更有一些技術信仰。
賴鴻昌:秦臻的工作驗證了理論可能性,我們確實很佩服MiniMax願意去嘗試,能真的把這個研究成果最終落地。因爲400B的模型,和我們做驗證的難度不是一個量級的,他們也做了很多其他工作。
葡萄君:你看到他們的成果時,第一反應是什麼,會有一些哭笑不得嗎?
秦臻:不會,我很高興。因爲我首先知道,在TapTap訓那麼大的模型肯定是不現實的。所以從個人角度,你看到你所提的方案,被應用在這麼大規模的模型裏,肯定是會高興的。
另一方面,從領域發展的角度,大家之前覺得線性Attention在小規模下可以跑通,但一直沒有人有勇氣做到這麼大,而MiniMax做到了非常關鍵的臨門一腳。我相信這會給行業注入新鮮血液,讓這個領域發展得更好。
葡萄君:站在圈外看熱鬧的視角,我感覺不瞭解事情的人是不是會有一種誤解——“心動的研究成果被別人摘桃子了”。
秦臻:你只要發表了論文,那任何一家公司都可以使用其中的技術。當你提出的技術被商業化落地,心情只有興奮。
賴鴻昌:或者說,他們是在把我們提供的食材做成一道菜。我們也是滿滿的敬畏,而且樂於見到這樣的事情發生。
葡萄君:最近成果出現之後,是不是會有很多人來打聽你?這會對你造成一些影響嗎?
秦臻:這個領域很小,之前的我相當於小透明,現在可能會有一些領域外的同行對我好奇,畢竟我是在TapTap做Research,這是一個比較神奇的事情。
一些社羣中對秦臻的討論
葡萄君:我有點好奇,你實際上是這個方向的翹楚,卻一直在當小透明,會不會覺得心裏有點憋屈?
秦臻:如果沒人關注,你心裏不可能毫無波瀾。但我也想過這個問題——如果你認爲你做的東西有價值,別人看不看沒那麼重要。因爲如果它真的很有價值,最後一定會有它被用上的一天。
如果你真的這麼想,也喜歡自己認定的方向,就要儘量避免浮躁的心態。因爲你做這些事不是爲了贏得更多的關注度,而是爲了你認定的價值去堅持。如果有一天它真的落地了,那還是一個額外的驚喜。
賴鴻昌:無論有沒有人關注、成果如何,都能長期做某一件事情,這也是秦臻作爲Researcher的一個天賦,其他人很難維持這樣的心態。
葡萄君:在AI這個方向上,你們還有什麼想做到的事情嗎?
賴鴻昌:第一,不要去過早地判斷,因爲AI領域的可能性,本身遠超我們能做判斷的能力。
第二,我們希望順着這條路,在今年更多嘗試多模態大模型,支撐TapTap的業務,最好能在具體業務問題上用自己的模型解決。今年,我們會想辦法去做1~2款應用,同時也要保持投入保持韌性,接受失敗。在我們最終做完那一兩款之前,肯定是要再失敗N次的。
秦臻:從Research角度來說,去年半年我在線性模型方向有點陷入低谷,但現在的理解更進了一步,能嘗試的還蠻多的。比如,當你的方案從方向A和方向B都升級過之後,那必然會得到一個更好的成果,但你不知道是方向A還是方向B起了作用,誰是冗餘的,這對我來說就是一個值得研究的問題。
葡萄君:對AI行業未來的發展,你們還有什麼樣的展望嗎?
秦臻:從工業界角度來說,這個領域就是OpenAI領跑,大家跟進。所以除非OpenAI本身碰到很大困難,否則應該還能再蓬勃發展一段時間。從我自己預測的角度來說,我還是比較關心線性模型。假設真的能work,它能解鎖的場景真的很多。
但是關鍵在於,這事情有個悖論——就算沒跑通,因爲深度學習的理論並沒有特別完善,你做了一個不work的研究,它實際上可能還是work的。所以除非你真把它做work了,才能證明它work;但你沒做work,卻不代表它一定不work。所以這個方向,可能還會有人持續去嘗試。
賴鴻昌:大模型行業就應該在競爭中發展,而大家最後都會變成技術都受益者。我們能保持follow,在某個時間節點來臨的時候有所準備,那就是最好的結果。