技嘉AI TOP ATOM工作站:一人一機,搞定千億參數
在近期的本地AI部署討論中,一個核心痛點始終存在:要在桌面級功耗和體積下跑動千億參數大模型,往往需要在算力、內存帶寬或易用性上做妥協。技嘉最新推出的AI TOP ATOM迷你工作站,直接對這一難題給出了回應。它將NVIDIA GB10 Grace Blackwell超級芯片與128GB統一內存塞進了機箱,並聯合趨境科技預置了開箱即用的完整軟件棧。對於需要私有化部署、又不想自研運維管道的開發者和中小企業,這款產品提供了一個值得仔細考量的選項。

這臺150mm見方的機器,外觀上刻意與遊戲硬件劃清了界限。銀灰色金屬機箱表面做了細磨砂處理,沒有透窗也沒有任何RGB光源。進出風口採用橫向柵格,內部用強化筋維持結構剛性,這種設計在保證風道順暢的同時,把滿載運行的風噪控制在辦公環境可接受的範圍。整機最顯眼的標識僅是正面右下角的GIGABYTE Logo,且同樣採用低調的蝕刻或暗色處理。

接口配置直接反映了它的使用場景。背部提供了三個USB 3.2 Type-C、一個用於240W供電的Type-C端口、一個HDMI 2.1a、一個萬兆RJ-45,以及一個NVIDIA ConnectX-7接口。後者值得單獨說明:通過這個接口可以直接連接兩臺AI TOP ATOM,將顯存和算力池化,從而支撐4000億參數以上的超大模型。對於需要逐步擴展算力的開發團隊,這種直連方式比萬兆網絡轉發效率更高,延遲也更低。

真正讓這臺機器區別於普通迷你主機的是內部架構。CPU與GPU不再分立,而是以NVIDIA GB10 Grace Blackwell超級芯片的形式封裝在一起。這顆芯片採用臺積電3nm工藝,將20個Arm v9.2核心(10個Cortex-X925加10個Cortex-A725)與Blackwell架構GPU通過NVLink-C2C互聯。GPU部分包含6144個CUDA核心,但由於統一內存架構以及Blackwell Tensor Core對FP4精度的原生支持,其AI推理算力達到1000 TOPS。這意味着它可以單機運行2000億參數的模型,這是同等CUDA數量的消費級顯卡做不到的,因爲後者受限於獨立顯存容量。

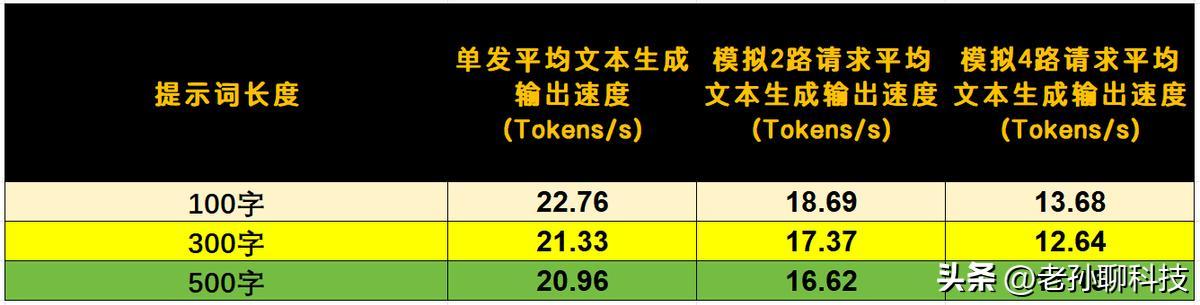
內存設計是整個方案的另一個關鍵點。技嘉AI TOP ATOM工作站配置了128GB LPDDR5x統一內存,CPU與GPU共享這一地址空間,帶寬爲273GB/s。在運行GLM-4.5-Air這類106B模型時,FP4量化後的顯存佔用約爲68至69GB,剛好落在總容量的一半左右,留出了餘量給Embedding或Rerank等其他模型實例並行運行。實際測試中,500字長提示詞下的文本生成速度維持在20.96 tokens/s,4路併發時仍高於10 tokens/s。這種性能表現對於一臺功耗控制在140W左右的桌面設備而言,已經超出了可用的基線。
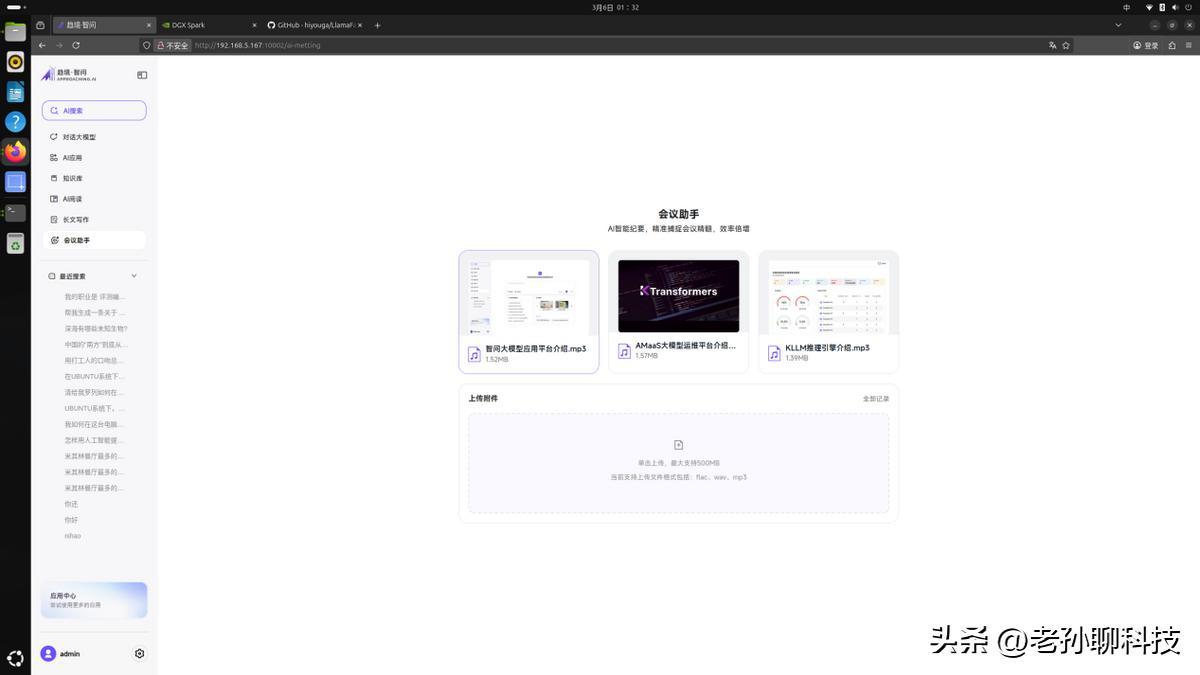
軟件層面,技嘉與趨境科技的合作直接解決了本地AI部署最大的痛點:環境配置。設備出廠即預裝了趨境智問系統,內置智譜GLM-4.5-Air 106B模型。用戶通過瀏覽器訪問即可進入管理平臺,這是一個圖形化的零代碼運維界面,可以實時監控GPU負載、顯存佔用、Token消耗,並支持一鍵啓動或切換模型實例。實測中同時運行LLM對話、Embedding和Rerank三個實例,系統自動分配資源無衝突。
面向日常使用的智問應用平臺則覆蓋了AI對話、文檔閱讀、會議紀要、週報生成、長文寫作等功能。其中會議助手的實時記錄與行動項追蹤、AI閱讀模塊的多格式文檔摘要翻譯,均在實際工作中具備較高的使用頻率。所有處理均在本地完成,數據不離開設備,滿足企業對私有化部署的合規要求。
從實際體驗來看,AI TOP ATOM填補了一個長期存在的市場空白:它既不是需要專業技術團隊耗時部署的機架式服務器,也不是缺乏大模型承載能力的普通迷你PC。對於需要運行百億至千億參數模型的算法工程師、數據科學家,或者希望將AI能力內嵌到業務流程但又不願承擔雲端數據風險的中小企業,這臺設備提供了明確的工程化路徑。它允許用戶在4到5分鐘內從通電進入模型推理狀態,並且通過ConnectX-7接口保留了線性的算力擴展能力。在本地AI從概念驗證走向實際生產的過渡期,這類軟硬一體、開箱即用的方案,可能是比自行攢機更理性的選擇。