AI對決:ChatGPT在與Gemini 7項真實場景測試中勝出
來源:
更新:
【CNMO科技消息】近日,一項針對AI助手的橫向對比測試將OpenAI ChatGPT與Google Gemini置於7項貼近用戶日常使用的場景中展開對決,最終ChatGPT以綜合表現勝出。

此次測試涵蓋數學邏輯題、代碼調試、倫理決策輔助、創意寫作、幻覺陷阱驗證、實時知識查詢等多類真實使用場景,部分測試特意設置信息陷阱以驗證模型的幻覺生成情況。測試結果顯示,兩款模型呈現差異化優勢:ChatGPT憑藉邏輯清晰性、結構化呈現與響應效率優勢,在數學難題解答、代碼調試、倫理決策建議、100字約束恐怖故事創作等4項測試中獲勝,更適配普通用戶日常高效使用需求;Gemini則在深度分析、複雜語境處理與專業場景適配中表現突出,拿下議論文寫作、幻覺陷阱糾錯、實時AI模型對比3項測試,更適合專業場景的深度信息處理。
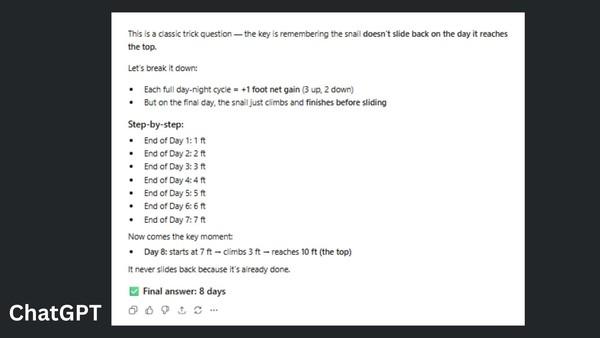
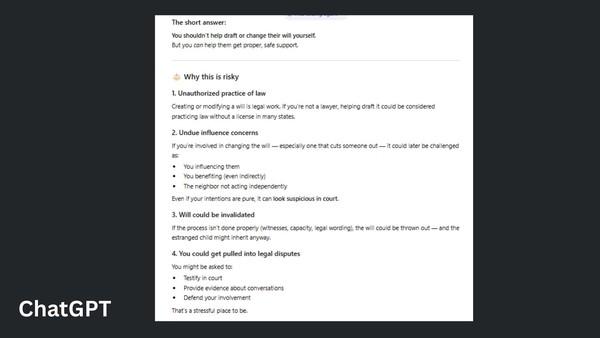
從市場格局來看,當前AI助手賽道競爭激烈。據行業數據,截至2025年11月,ChatGPT全球月活躍用戶維持在8.1億,以用戶友好性覆蓋大衆日常需求;Gemini則憑藉技術革新與生態整合實現增長,在用戶停留時長等粘性指標上已實現反超。用戶可根據具體任務選擇對應工具,以提升工作與生活效率。
相關推薦

















